JavaEE学习日志持续更新----> 必看!JavaEE学习路线(文章总汇)
Java学习日志(六)
Set接口
java.util.Set接口 extends Collection接口
Set接口特点:
- 不允许存储重复元素
- 没有索引,没有带索引的方法(和Collection接口的方法一致)
哈希值
就是一个十进制的整数,由操作系统随机给出。对象的地址值,就是使用的哈希值,由JVM模拟出来的一个地址,不是对象的实际物理地址。
获取哈希值:
在Object类中有一个方法hashCode,可以获取对象的哈希值
int hashCode() 返回对象的哈希码值。
hashCode方法的源码:
native:指的是调用系统的方法。由操作系统随机给出
public native int hashCode();示例:当重写Person类的hashCode方法,使方法返回1时,p1和p2对象的哈希值相等,但p1与p2对象的地址值不相等
public class Person {
//重写Object类的hashCode方法
@Override
public int hashCode() {
return 1;
}
}public class Demo01 {
public static void main(String[] args) {
//创建Person对象
Person p1 = new Person();
//Person类默认继承了Object,所以可以使用hashCode方法
int h1 = p1.hashCode();
System.out.println(h1);//764977973-->1
Person p2 = new Person();
int h2 = p2.hashCode();
System.out.println(h2);//381259350-->1
//toString方法,获取对象的地址值
System.out.println(p1.toString());//demo03.hashcode.Person@2d98a335-->1
System.out.println(p2.toString());//demo03.hashcode.Person@16b98e56-->1
System.out.println(p1==p2);//false 由JVM模拟出来的一个地址,不是对象的实际物理地址
}
}String类的哈希值
String类重写了Object类的hashCode方法,相同的字符串,返回的哈希值是一样的。
重写源码:
public static int hashCode(byte[] value) {
int h = 0;
byte[] var2 = value;
int var3 = value.length;
for(int var4 = 0; var4 < var3; ++var4) {
byte v = var2[var4];
h = 31 * h + (v & 255);
}
return h;
}示例:
public class Demo02 {
public static void main(String[] args) {
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println(s1.hashCode());//96354
System.out.println(s2.hashCode());//96354
//巧合,不同字符串的两个相同的哈希值
System.out.println("重地".hashCode());//1179395
System.out.println("通话".hashCode());//1179395
}
}哈希表
jdk1.8之前:数组+单向链表
jdk1.8之后:数组+单向链表或数组+红黑树(提高效率)
数组:按照元素的哈希值对元素进行分组,相同哈希值的元素存储在同一个数组下
链表/红黑树:存储相同哈希值的元素
示例:
“abc”:哈希值为96354
“重地”:哈希值为1179395
“通话”:哈希值为1179395
哈希表存储元素前,会计算元素的哈希值,哈希值就是元素在数组中的存储位置。
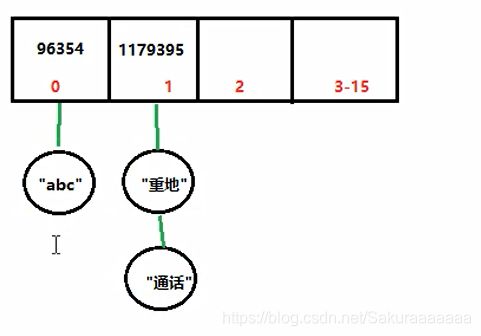
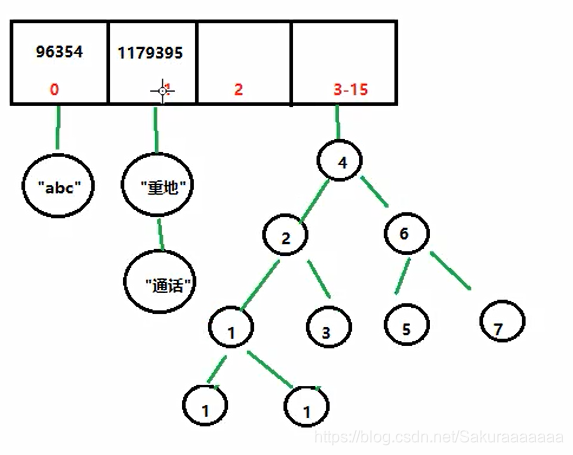
两个元素的哈希值相同,叫哈希冲突,会影响查询的效率。
若有超过8个以上的元素,则采用红黑树
HashSet集合
java.util.HashSet集合 implements Set接口
HashSet集合的特点
- 不允许存储重复元素
- 没有索引,没有带索引的方法(和Collection接口的方法一致)
- 是一个无序的集合,存储元素和取出元素的顺序有可能不一致
- 底层是一个哈希表
示例:
private static void show01() {
Set<String> set = new HashSet<>();
//往集合中添加元素
set.add("a");
set.add("b");
set.add("d");
set.add("c");
set.add("a");
//使用迭代器遍历Set集合
Iterator<String> it = set.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);// a b c d
}
}虽然HashSet集合是一个无序的集合,但会根据自然顺序进行排序,如abcd或1234
private static void show02() {
Set<Integer> set = new HashSet<>();
//往集合中添加元素
set.add(2);
set.add(1);
set.add(4);
set.add(3);
//增强for遍历
for (Integer integer : set) {
System.out.println(integer);// 1 2 3 4,按照自然顺序排序
}
}HashSet集合存储元素不重复的原理
被存储的元素重写了hashCode和equals方法,以保证元素唯一。
HashSet集合在调用add方法存储元素时,会调用元素的hashCode方法和equals方法判断元素是否重复。
示例:
public class Demo02 {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
String s1 = new String("abc");
String s2 = new String("abc");
set.add(s1);
set.add(s2);
set.add("重地");
set.add("通话");
set.add("abc");
System.out.println(set);
}
}1. 相同的字符串,相同的哈希值:
当执行set.add(s1);时,add方法会调用字符串s1的hashCode方法,计算s1哈希值为96354,会在集合中找有没有96354这个哈希值的元素,发现没有,就会把s1存储到集合中。
当执行set.add(s2);时,add方法会调用字符串s2的hashCode方法,计算s1哈希值为96354,会在集合中找有没有96354这个哈希值的元素,发现有,s2就会调用equals方法和已有元素比较,s2.equals(s1)=true,两个元素的哈希值相同,且equals方法返回true,认定两个元素相同,就不会把s2存储到集合中。
1. 不同的字符串,相同的哈希值:
当执行set.add("重地");时,add方法会调用字符串"重地"的hashCode方法,计算"重地"哈希值为1179395,会在集合中找有没有1179395这个哈希值的元素,发现没有,就会把"重地"存储到集合中。
当执行set.add("通话");时,add方法会调用字符串"通话"的hashCode方法,计算"通话"哈希值为1179395,会在集合中找有没有1179395这个哈希值的元素,发现有,"通话"就会调用equals方法和已有元素比较,“通话”.equals(“重地”)=false,两个元素的哈希值相同,但equals方法返回false,认定两个元素不相同,就把"通话"存储到集合中。
HashSet集合的扩容(rehash)
集合的扩容,也叫集合的再哈希(rehash)。
jdk中有这么一句话:这个类提供了基本的操作(固定时间性能add , remove , contains和size ),假定哈希函数将分散的桶中正确的元素。 迭代此集合需要的时间与HashSet实例的大小(元素数量)加上后备HashMap实例的“容量”(桶数)之和成比例。 因此,如果迭代性能很重要,则不要将初始容量设置得太高(或负载因子太低)非常重要。
再来看HashSet的空参构造:
HashSet()构造一个新的空集; 支持HashMap实例具有默认初始容量(16)和加载因子(0.75)。
HashSet集合扩容的条件 = 初始容量*加载因子
如:
- 16*0.75 = 12 集合存储12个元素,就会扩容,容量扩大一倍 32
- 32*0.75 = 24 集合存储24个元素,就会扩容,容量扩大一倍 64
不要将容量设置太高
- 初始容量:100
100*0.75 = 75 存储了75个元素再扩容,内存中元素过多效率地下
加载因子设置太低
- 加载因子:0.1
- 16*0.1 = 1.6 存储1个元素扩容1此,频繁扩容,效率低下
HashSet集合存储自定义类型元素
存储的自定义类型的元素(Person,Student),必须重写hashCode和equals方法。 以保证同属性的元素视为同一个元素(姓名和年龄相同,人视为同一个人)。
定义一个Person类
public class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
//重写了hashCode方法,可以保证同名同年龄的人,返回相同的哈希值。
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}存储Person对象
public class Demo03 {
public static void main(String[] args) {
//创建HashSet集合,存储Person
HashSet<Person> set = new HashSet<>();
set.add(new Person("小一",18));
set.add(new Person("小一",18));
set.add(new Person("小二",20));
set.add(new Person("重地",18));
set.add(new Person("通话",18));
//遍历
for (Person person : set) {
System.out.println(person);
}
//在没重写hashCode和equals方法前的结果
// Person{name='重地', age=18}
// Person{name='小二', age=20}
// Person{name='通话', age=18}
// Person{name='小一', age=18}
// Person{name='小一', age=18}
//重写hashCode和equals方法后的结果
// Person{name='小一', age=18}
// Person{name='小二', age=20}
// Person{name='重地', age=18}
// Person{name='通话', age=18}
}
}LinkedHashSet集合
java.util.LinkedHashSet集合 extends HashSet集合
特点:
- 不允许存储重复元素
- 没有索引,没有带索引的方法
- 底层是一个哈希表+单向链表 -->双向链表,是一个有序的集合
public class Demo04 {
public static void main(String[] args) {
HashSet<String> linked = new LinkedHashSet<>();
linked.add("aaa");
linked.add("ccc");
linked.add("bbb");
linked.add("aaa");
System.out.println(linked);
//[aaa, ccc, bbb]不允许重复,有序
}
}Collections集合工具类
java.util.Collections:集合的工具类
shuffle方法和不带比较器的sort方法
static void shuffle(List<?> list, Random rnd) 使用指定的随机源随机置换指定的列表。
static <T extends Comparable<? super T>>void sort(List<T> list) 根据其元素的natural ordering ,将指定列表按升序排序。
注意:以上方法,必须传递List集合,不能传递Set集合
示例:
public class Demo01 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
System.out.println(list);//[1, 2, 3, 4]
//使用shuffle方法,打乱元素顺序
Collections.shuffle(list);
System.out.println(list);//[1, 4, 2, 3]
//使用sort方法,对集合中元素进行默认排序(升序)
Collections.sort(list);
System.out.println(list);//[1, 2, 3, 4]
ArrayList<String> list02 = new ArrayList<String>();
list02.add("a");
list02.add("1");
list02.add("B");
list02.add("cd");
list02.add("cc");
System.out.println(list02);
//使用sort方法,对集合中元素进行默认排序(升序,编码表顺序)
Collections.sort(list02);
System.out.println(list02);//[1, B, a, cc, cd]
}
}带比较器的sort方法
static <T> void sort(List<T> list, Comparator<? super T> c) 根据指定比较器引发的顺序对指定列表进行排序。
注意:以上方法,必须传递List集合,不能传递Set集合
参数:
java.util.Comparator:是一个比较器接口,有一个用于定义排序规则的抽象方法
int compare(T o1, T o2) 比较它的两个参数的顺序。
排序规则:
升序:o1-o2
降序:o2-o1
示例1:对默认类型进行排序
public class Demo02 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(4);
list.add(3);
System.out.println(list);//[2, 1, 4, 3]
//使用sort,传递比较器对集合中的元素进行升序排序
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
System.out.println(list);//[1, 2, 3, 4]
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
System.out.println(list);//[4, 3, 2, 1]
}
}示例2:对自定义类型(Person类的age属性)进行排序
public class Demo03 {
public static void main(String[] args) {
ArrayList<Person> list = new ArrayList<>();
list.add(new Person("小一",29));
list.add(new Person("小二",19));
list.add(new Person("小三",17));
list.add(new Person("小四",21));
//[Person{name='小一', age=29}, Person{name='小二', age=19}, Person{name='小三', age=17}, Person{name='小四', age=21}]
System.out.println(list);
//使用sort方法,对Person进行排序,按照年龄的降序排序
Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o2.getAge()-o1.getAge();
}
});
//[Person{name='小一', age=29}, Person{name='小四', age=21}, Person{name='小二', age=19}, Person{name='小三', age=17}]
System.out.println(list);
}
}