在搭建完Hadoop集群后,最让人激动的时刻莫过于启动Hadoop了,看到namenode出来了,简直高兴得跳起来啦。但是,在slave机器上jps并没有datanode,此刻又陷入了苦恼了。
我们现在先挑出来形象的讲讲,id这个东西就是一个事物的唯一标识了,如人的身份证号,又或者是手机的序列号等等。在这里,master和slave是一个集群,那么它们也有自己的id号的,而且一个集群里的id都是一样的。假如master和其中一台slave所持有的id不一致,那就意味着不在一个集群了。
回归正题,那个id到底藏在了哪里呢?
这就要我们去找之前搭建hadoop所配置的hdfs-site.xml文件中查看你配置的路径了;如下图。这个目录是我们格式化的时候产生的,这个路径下有一个current目录,用来存放namenode的核心数据的,接着它里面有一个集群的标志文件VERSION,记录了一系列集群的标识id。

按照上图的路径的话,我们去/opt/hadoop/hdfs/name目录下,目录里有个current的目录,里面有一个VERSION的文件,接着“cat”命令查看文件内容;

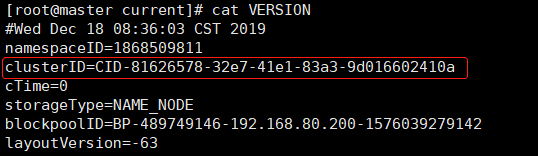
VERSION内容如下,其中有一个clusterID,这个就是上面的集群标识ID了,那么这样的话,在slave机器里的datanode的数据文件下的clusterID会跟下面的master的namenode数据文件的clusterID一致了,否则它们就不是一个集群下的节点了。
以相同的办法打开并查看datanode数据文件下的VERSION标识ID文件,如下图:

对比两个的clusterID是一致的,所以它们是在一个集群的,所以就有了master开启并工作之后,slave下的datanode也跟着帮“社团老大”工作了,否则不在一个集群是找不到“社团老大”就无法工作了。
其中的原因是:我们在启动集群前又格式化了一次,此时重新生成一个namenode的数据文件并重新生成VERSION文件,但是datanode的version文件不会同步更新,导致了datanode的clusterID和namenode的clusterID不一致,最终造成datanode无法启动。
到这里就很容易理解啦,解决办法有两个:
- 把namenode节点和datanode节点下的数据文件删除了,再重新格式化一次,按照上图的话,就把/opt/hadoop/hdfs这个目录以及目录下的文件都删除。
- 把master机器上namenode的clusterID复制到slave机器上datanode的clusterID,保持一致。
然后就是这两个方法的选择了,呃呃呃!我觉得呢,如果是刚刚搭建的Hadoop就选择第一个了,原因有二:一、刚搭建没有重要数据,简单粗暴;二、就是担心还存在除了clusterID的问题还有其他没发现的原因,那就干脆重来了;那么,如果是后来工作了许久的Hadoop的话,因为存在着重要数据就选择第二种了,所以就选择第二种啦!
这样就把走失的datanode召回到集群里了!
如果以上还没解决就移步到这里参考啦!
若有不足之处望留言!
——————END———————
Programmer:柘月十七
