今天完成了实验五第二问,因为自己一开始不会,搜索了相关知识后稍微了解了,然后跟着网上的思路解决了,出现了点问题,还是完成了。明天完成第三问,进行实验六。
编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到
DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代
码。
第一种方法源代码:
利用反射来推断包含特定类型对象的RDD的schema,适用对已知数据结构的RDD转换
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder import org.apache.spark.sql.Encoder import spark.implicits._ object RDDtoDF{ def main(args: Array[String]) { case class Employee(id:Long,name: String, age: Long) val employeeDF = spark.sparkContext.textFile("file:///usr/local/spark/employee.txt").map(_.split(",")).map(attributes => Employee(attributes(0).trim.toInt,attributes(1), attributes(2).trim.toInt)).toDF() employeeDF.createOrReplaceTempView("employee") val employeeRDD = spark.sql("select id,name,age from employee") employeeRDD.map(t => "id:"+t(0)+","+"name:"+t(1)+","+"age:"+t(2)).show() } }
但是写成scala文件运行,会报错。
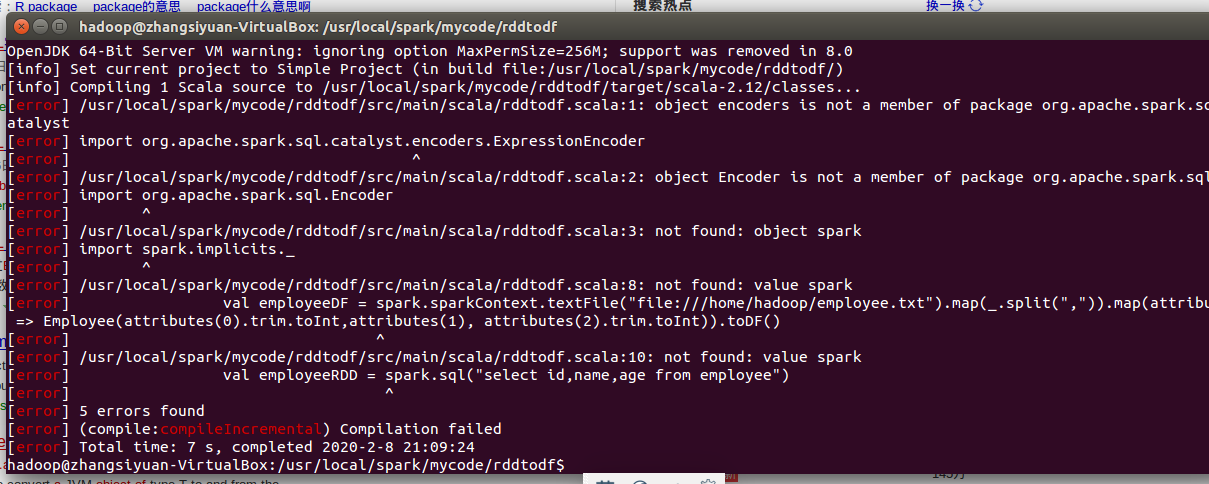
暂时没解决。
但是把每一行看做一个spark命令,在spark-shell中执行,可以成功运行。

方法二:使用编程接口,构造一个schema并将其应用在已知的RDD上。
import org.apache.spark.sql.types._ import org.apache.spark.sql.Encoder import org.apache.spark.sql.Row object RDDtoDF{ def main(args: Array[String]) { val employeeRDD = spark.sparkContext.textFile("file:///usr/local/spark/employee.txt") val schemaString = "id name age"val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true)) val schema = StructType(fields) val rowRDD = employeeRDD.map(_.split(",")).map(attributes => Row(attributes(0).trim, attributes(1), attributes(2).trim)) val employeeDF = spark.createDataFrame(rowRDD, schema) employeeDF.createOrReplaceTempView("employee") val results = spark.sql("SELECT id,name,age FROM employee") results.map(t => "id:"+t(0)+","+"name:"+t(1)+","+"age:"+t(2)).show() } }