文章目录
实例一 温度转换
介绍
温度的刻画有两个不同体系:摄氏度(℃)和华氏度(Fabrenheit)。请编写程序将用户输入华氏度转换为摄氏度,或将输入的摄氏度转换为华氏度。转换算法如下:(C表示摄氏度,F表示华氏度)
C =(F-32)/ 1.8
F = C * 1.8 + 32
算法要求
输入输出的摄像度可采用大小写字母C结尾,温度可以是整数或小数,如:12.34C指摄氏度12.34度;输入输出的华氏度可采用大小写字母F结尾,温度可以是整数或小数,如:87.65F指摄氏度87.65度;输出保留小数点后两位,输入格式错误时,输出提示:输入格式错误。
代码
#TempConvert.py
TempStr = input("请输入带有温度的符号值:") #定义一个变量
if TempStr[-1] in ['F','f']: #if函数,python中引入一个函数时要在行尾加“:”
C = (eval(TempStr[0:-1])-32)/1.8 #缩进格式
print("转换后的温度是{:.2f}C".format(C)) #将结果C保留两位小数
elif TempStr[-1] in ['C','c']:
F = 1.8*eval(TempStr[0:-1])+32
print("转化后的温度是{:.2f}F".format(F))
else:
print("输入格式有误!")
测试结果如下:
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
=================== RESTART: E:\python exercise\TempStr.py ===================
请输入带有温度的符号值:36C
转化后的温度是96.80F
>>>
=================== RESTART: E:\python exercise\TempStr.py ===================
请输入带有温度的符号值:100F
转换后的温度是37.78C
>>>
温度转化变体
人民币与美元的转化。
1美元=6.78人民币。
人民币用RMB表示,美元用USD表示。
#USD_RMB.py
TempStr=input()
if TempStr[0] in ['U']:
RMB=6.78*eval(TempStr[3:])
print("RMB{:.2f}".format(RMB))
elif TempStr[0] in ['R']:
USD=eval(TempStr[3:])/6.78
print("USD{:.2f}".format(USD))
测试结果如下:
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
=================== RESTART: E:\python exercise\USD_RMB.py ===================
USD6
RMB40.68
>>>
=================== RESTART: E:\python exercise\USD_RMB.py ===================
RMB100
USD14.75
>>>
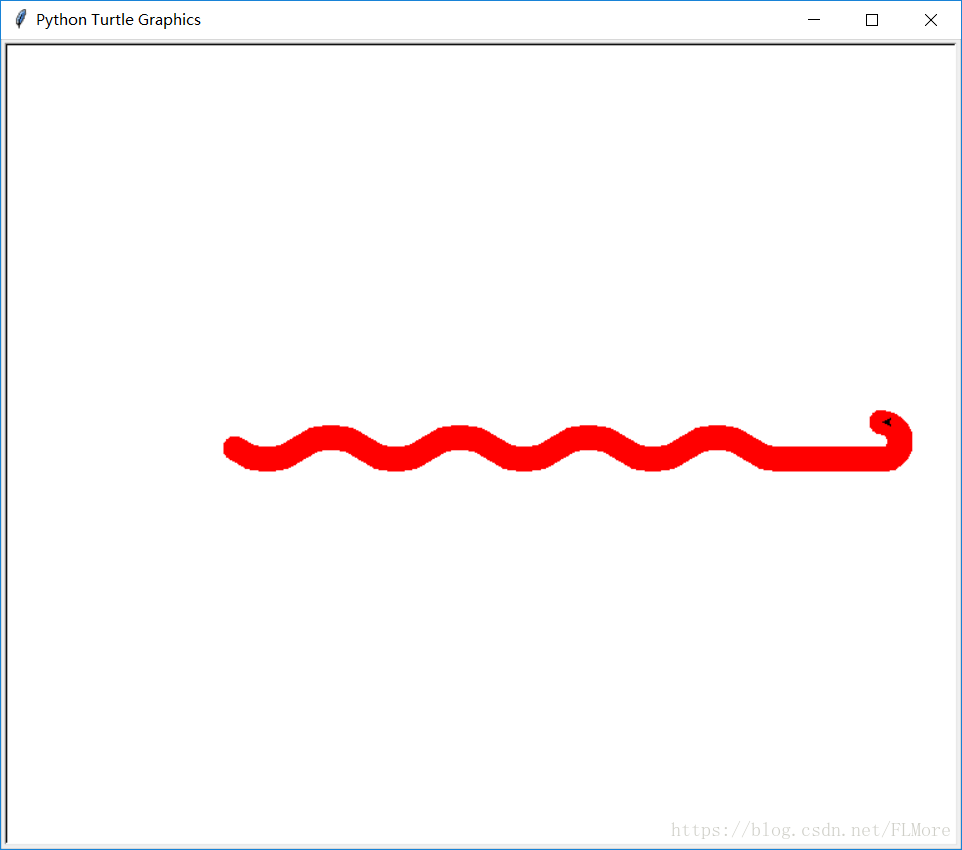
实例二 turtle简单绘制
介绍
使用龟库,绘制一个蟒蛇形状的图形。
代码
#PythonDraw.py
import turtle as t #引入turtle函数并定义为“t”,方便代码书写。
t.pensize(20) #设置画笔粗细
t.pencolor("red") #设置画笔颜色
t.pu() #画笔抬起,turtle飞行。
t.fd(-200) #turtle向前移动 -200 。
t.seth(-40) #设置绝对角度。注意绝对角度与相对角度的区分!
t.pd () #画笔放下,turtle爬行。“pu()”、“pd()”一般成对出现。
for i in range(4): #for函数下的命令循环执行4次。
t.circle(40,80) #画一段半径为40,圆心角为80°的圆弧。
t.circle(-40,80) #turtle.circle命令详解:turtle.circle(radius,extent=,steps=),即半径,弧度,作半径为R的圆内切正多边形,其边数为steps。
t.circle(40,40)
t.fd(80)
t.circle(15,180)
t.done()
测试结果如下:
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
================= RESTART: E:\python exercise\PythonDraw.py =================
用turtle画一个五环
代码如下:
#FiveCircles.py
import turtle as t
t.pensize(10)
t.penup()
t.pencolor ("blue")
t.fd(-180)
t.pendown()
t.circle(80)
t.penup()
t.fd(180)
t.pencolor("black")
t.pendown()
t.circle(80)
t.penup()
t.pencolor("red")
t.fd(180)
t.pendown()
t.circle(80)
t.penup()
t.goto(-90,-80)
t.pencolor("yellow")
t.pendown()
t.circle(80)
t.penup()
t.goto(90,-80)
t.color("green")
t.pendown()
t.circle(80)
测试结果:

实例三 天天向上的力量
介绍
每天比前一天进步1%,那么一年以后进步多少呢?如果每天退步1%,那么一年以后退步多少呢?如何用python程序实现
逐步分析
一年中的每一天都在进步或都在退步。
#DayDayUp.py
dayfactor=0.005
dayup=pow(1+dayfactor,365)
daydown=pow(1-dayfactor,365)
print("向上:{:.2f},向下:{:.2f}".format(dayup,daydown))
工作日进步,周末退步。
#DayDayUpQ3.py
dayup=1.0
dayfactor=0.01
for i in range(365):
if i%7 in [6,0]:
dayup=dayup*(1-dayfactor)
else:
dayup=dayup*(1+dayfactor)
print("工作日的力量:{:.2f}".format(dayup))
一个工作日进步,周末退步的人,要多努力才可以赶得上每天都在进步的人?
#DayDayUpQ4.py
def dayUp(factor):
dayup=1
for i in range(365):
if i%7 in[6,0]:
dayup=dayup*(1-0.01)
else:
dayup=dayup*(1+factor)
return dayup
factor=0.01
while dayUp(factor)<37.78:
factor+=0.0001
print("工作日的努力参数为:{:.4f}".format(factor))
测试结果
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
RESTART: E:\Study&Summary\000-Linux-python process\003-python exercise\DayDayUpQ2.py
向上:6.17,向下:0.16
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
RESTART: E:\Study&Summary\000-Linux-python process\003-python exercise\DayDayUpQ3.py
工作日的力量:4.63
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
RESTART: E:\Study&Summary\000-Linux-python process\003-python exercise\DayDayUpQ4.py
工作日的努力参数为:0.0182
实例四 文本进度条
介绍
采用字符串方式打印可以动态变化的文本进度条;进度条需要在一行中逐渐变化。
代码
#TextProBar.py
import time
scale=50
print("执行开始".center(scale//2,"-"))
start=time.perf_counter()
for i in range(scale+1):
a='*'*i
b='.'*(scale-i)
c=(i/scale)*100
dur=time.perf_counter()-start
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end='')
time.sleep(0.1)
print("\n"+"执行结束".center(scale//2,'-'))
执行结果

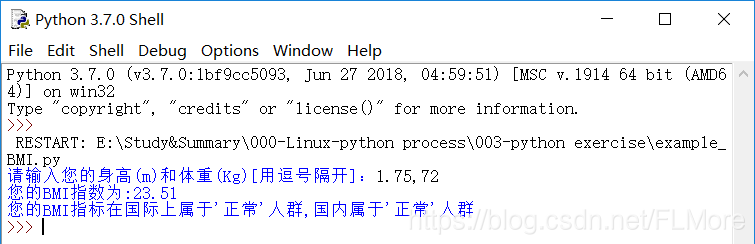
实例五 身体质量指数BMI
问题介绍
BMI指数等于体重(Kg)/身高(m)^2
BMI指数可判断一个人的胖瘦程度,但国际和国内标准略有不同,具体如下:
| 分类 | 国际BMI值 | 国内BMI值 |
|---|---|---|
| 偏瘦 | <18.5 | <18.5 |
| 正常 | 18.5~25 | 18.5~24 |
| 偏胖 | 25~30 | 24~28 |
| 肥胖 | >=30 | >=28 |
代码
#example_BMI.py
height,weight=eval(input("请输入您的身高(m)和体重(Kg)[用逗号隔开]:"))
bmi=weight/height**2
print("您的BMI指数为:{:.2f}".format(bmi))
if bmi<18.5:
nat,china="偏瘦","偏瘦"
elif 18.5<=bmi<24:
nat,china="正常","正常"
elif 24<=bmi<25:
nat,china="偏胖","正常"
elif 25<=bmi<28:
nat,china="偏胖","偏胖"
elif 28<=bmi<30:
nat,china="肥胖","偏胖"
else:
nat,china="肥胖","肥胖"
print("您的BMI指标在国际上属于'{0}'人群,国内属于'{1}'人群".format(nat,china))
运行结果
实例六 圆周率pi的计算
介绍
在一个边长为1的正方形内,内切一个半径为1的四分之一圆。向这个正方形区域内投大量随机点并计算出现在圆周内的点与总的点数的比值,这个比值就等于pi/4,由此可以得出pi的值。

代码
#calculatepi.py
#用蒙特卡罗方法计算
from random import random
from time import perf_counter
DARTS=pow(1000,2)
hits=0.0
start=perf_counter()
for i in range(1,DARTS+1):
x,y=random(),random()
dist=pow(x**2+y**2,0.5)
if dist<=1.0:
hits=hits+1
pi=4*(hits/DARTS)
print("圆周率值是:{}".format(pi))
print("运行时间是:{:.5f}s".format(perf_counter() - start))
运行结果
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>>
RESTART: E:\Study&Summary\000-Linux-python process\003-python exercise\Calculate_pi.py
圆周率值是:3.138468
运行时间是:0.82975s
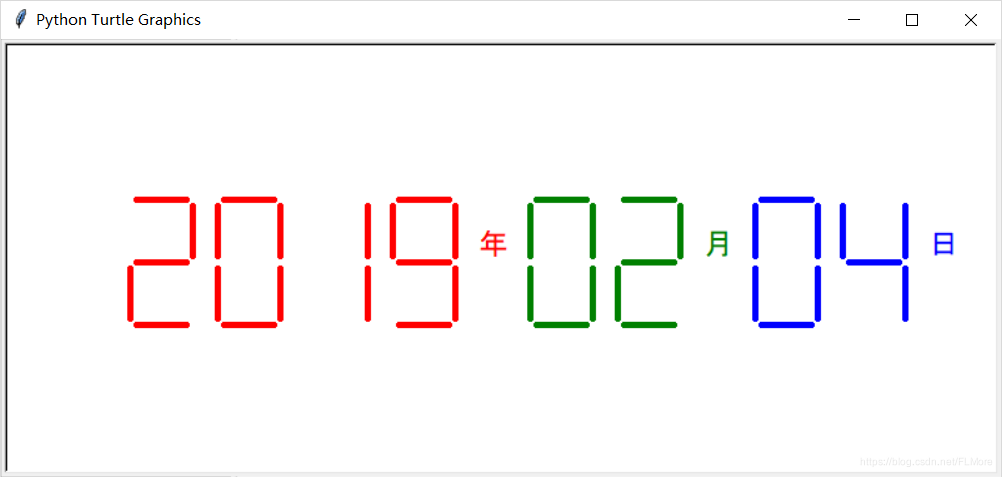
实例七 七段数码管绘制
介绍
利用 turtle 绘图体系绘制单个数码管,之后将一串数字变为数码管,最后并引入 time 库显示时间。
代码1
import turtle as t
def drawline(draw): # 绘制单段数码管
t.pendown() if draw else t.penup()
t.fd(40)
t.right(90)
def drawDight(dight): # 根据数字绘制七段数码管
drawline(True) if dight in [2, 3, 4, 5, 6, 8, 9] else drawline(False)
drawline(True) if dight in [0, 1, 3, 4, 5, 6, 7, 8, 9] else drawline(False)
drawline(True) if dight in [0, 2, 3, 5, 6, 8, 9] else drawline(False)
drawline(True) if dight in [0, 2, 6, 8] else drawline(False)
t.left(90)
drawline(True) if dight in [0, 4, 5, 6, 8, 9] else drawline(False)
drawline(True) if dight in [0, 2, 3, 5, 6, 7, 8, 9] else drawline(False)
drawline(True) if dight in [0, 1, 2, 3, 4, 7, 8, 9] else drawline(False)
t.left(180)
t.penup() # 为后续数字确定位置
t.fd(20) # 为后续数字确定位置
def drawDate(date): # 获取要输出的数字
for d in date:
drawDight(eval(d)) # 通过 eval() 函数将数字变为整数
def main():
t.setup(800, 350, 200, 200)
t.penup()
t.fd(-300)
t.pensize(5)
drawDate("20190203")
t.hideturtle()
t.done()
main()
运行结果1

代码2
import turtle as t
import time
def drawGap():# 绘制数码管间隔
t.penup()
t.fd(5)
def drawline(draw):# 绘制单段数码管
drawGap()
t.pendown() if draw else t.penup()
t.fd(40)
drawGap()
t.right(90)
def drawDight(dight): # 根据数字绘制七段数码管
drawline(True) if dight in [2, 3, 4, 5, 6, 8, 9] else drawline(False)
drawline(True) if dight in [0, 1, 3, 4, 5, 6, 7, 8, 9] else drawline(False)
drawline(True) if dight in [0, 2, 3, 5, 6, 8, 9] else drawline(False)
drawline(True) if dight in [0, 2, 6, 8] else drawline(False)
t.left(90)
drawline(True) if dight in [0, 4, 5, 6, 8, 9] else drawline(False)
drawline(True) if dight in [0, 2, 3, 5, 6, 7, 8, 9] else drawline(False)
drawline(True) if dight in [0, 1, 2, 3, 4, 7, 8, 9] else drawline(False)
t.left(180)
t.penup() # 为后续数字确定位置
t.fd(20) # 为后续数字确定位置
def drawDate(date):# date为日期, 格式为 “%Y-%m=%d+”
t.pencolor('red')
for i in date:
if i == '-':
t.write('年', font=("Arial", 18, "normal"))
t.pencolor("green")
t.fd(40)
elif i == "=":
t.write("月", font=("Arial", 18, "normal"))
t.pencolor("blue")
t.fd(40)
elif i == "+":
t.write("日", font=("Arial", 18, "normal"))
else:
drawDight(eval(i))
def main():
t.setup(800, 350, 200, 200)
t.penup()
t.fd(-300)
t.pensize(5)
drawDate(time.strftime('%Y-%m=%d+', time.gmtime()))# 获取时间
t.hideturtle()
t.done()
main()
运行结果2
实例八 科赫雪花绘制
介绍
科赫曲线是一种分形,又称雪花曲线。本例利用 python 中的 turtle 库与递归函数原理绘制。递归函数有两个重要元素:链条和基例。
代码
import turtle as t
def koch(size, n):
if n == 0:
t.fd(size)
else:
for angle in [0, 60, -120, 60]:
t.left(angle)
koch(size, n - 1)
def main():
t.setup(600, 600)
t.penup()
t.goto(-250, 100)
t.pendown()
t.pensize(2)
level = 3
koch(15, level) # 3阶科赫曲线绘制
t.right(120)
koch(15, level)
t.right(120)
koch(15, level)
t.right(120)
t.hideturtle()
main()
运行结果

实例九 基本统计值计算
介绍
利用 python 程序计算一组数字的均值,样本方差和中位数。
代码
def getNum(): # 获取用户不定长度的输入
nums = []
iNumStr = input("请输入数字(回车退出):")
while iNumStr != "":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(回车退出):")
return nums
def mean(numbers): # 计算平均值
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
def dev(numbers, mean): # 计算方差(样本方差)
stdev = 0.0
for num in numbers:
stdev = stdev + (num - mean) ** 2
return pow(stdev / (len(numbers) - 1), 0.5)
def median(numbers): # 计算中位数
sorted(numbers)
size = len(numbers)
if size % 2 == 0:
med = (numbers[size // 2 - 1] + numbers[size // 2]) / 2
else:
med = numbers[size // 2 ]
return med
n = getNum() # getNum()函数也可以换成一组数字列表
m = mean(n)
print("平均值:{}, 方差:{}, 中位数:{}。".format(m, dev(n, m), median(n)))
实例十 文本词频统计
介绍
通过对纯英文文档“Hamlet”与中文文档“三国演义”中的词频以键值对的方式进行计算与存储,并通过打印结果不断去除干扰项,优化结果,最终得出文档中词频最高的前十名。
代码 1
Hamlet词频分析(hamlet.txt 下载地址)
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '`~!@#$%^&*()_+-={}[];,./\、|': # 归一化处理
txt = txt.replace(ch, " ")
return txt
hamletText = getText()
word = hamletText.split()
counts = {} # 用字典统计词频
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)# 根据字典中值的大小来排序
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count)) #打印词频排名前十
运行结果
the 1138
and 965
to 754
of 669
you 550
i 542
a 542
my 514
hamlet 462
in 436
Process finished with exit code 0
代码 2
三国演义词频分析(三国演义纯文本下载地址)
import jieba
txt = open("threekingdoms.txt", "r", encoding="utf-8").read() # 打开文件并读取
words = jieba.lcut(txt) # 利用 jieba 库归一化处理
counts = {} # 创建一个空字典准备计数
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1 # 对词频计数
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
运行结果
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Adam\AppData\Local\Temp\jieba.cache
Loading model cost 0.788 seconds.
Prefix dict has been built succesfully.
曹操 953
孔明 836
将军 772
却说 656
玄德 585
关公 510
丞相 491
二人 469
不可 440
荆州 425
玄德曰 390
孔明曰 390
不能 384
如此 378
张飞 358
Process finished with exit code 0
从运行结果我们不难看出,孔明与孔明曰其实是一人,二人、不可、如此等词不应该作为人名出现。因此我们需对代码 2 进行优化。
import jieba
txt = open("threekingdoms.txt", "r",
encoding="utf-8").read() # 打开文件并读取
excludes = {"将军", "却说", "荆州", "二人", "不可", "不能", "如此"} # 设置一个排除词的集合,可根据结果反复添加,直至结果最优。
words = jieba.lcut(txt) # 利用 jieba 库归一化处理
counts = {} # 创建一个空字典准备计数
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰": # 将意思相近的词归一化
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
for word in excludes: # 删除要排除的词
del counts[word]
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
运行结果
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Adam\AppData\Local\Temp\jieba.cache
Loading model cost 0.743 seconds.
Prefix dict has been built succesfully.
曹操 1451
孔明 1383
刘备 1252
关羽 784
张飞 358
商议 344
如何 338
主公 331
军士 317
吕布 300
左右 294
军马 293
赵云 278
引兵 276
次日 271
Process finished with exit code 0
可以看到, 这次的结果仍然不是很完善。但我们可以根据代码 2 的方法来反复调试来达到最佳 效果。
实例十一 自动轨迹绘制
介绍
- 定义数据文件格式(接口)
- 编写程序,根据文件接口解析参数绘制图形
- 编制数据文件

代码
import turtle as t
t.title("自动轨迹绘制")
t.setup(800, 600, 0, 0)
t.pencolor("red")
t.pensize(5)
# 数据读取
datals = []
f = open("data.txt")
for line in f:
line = line.replace("\n", "")
datals.append(list(map(eval, line.split(","))))
f.close()
# 自动绘制
for i in range(len(datals)):
t.pencolor(datals[i][3], datals[i][4], datals[i][5])
t.fd(datals[i][0])
if datals[i][1]:
t.right(datals[i][2])
else:
t.left(datals[i][2])
实例十二 政府工作报告词云
介绍
“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过滤掉大量的文本信息,使浏览者只要一眼扫过文本就可以领略文本的主旨。
python 代码实现词云的基本步骤:
1.读取文件, 分词整理
2.设置并输出词云
3.观察结果, 优化迭代
代码 1
分析文本:《决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利》(纯文本下载地址)
import jieba
import wordcloud
f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls) # 将序列中的元素以指定的字符连接生成一个新的字符串
w = wordcloud.WordCloud(font_path="msyh.ttc",
width=1000, height=700,
background_color="white")
w.generate(txt)
w.to_file("grwordcloud.png")
运行结果

代码 2
分析文本:《中共中央 国务院关于实施乡村振兴战略的意见》(纯文本下载地址)
import jieba
import wordcloud
from scipy.misc import imread
mask = imread("chinamap.jpg")
f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud(font_path="msyh.ttc", mask=mask,
width=1000, height=700, background_color="white")
w.generate(txt)
w.to_file("grwordcloud.png")
运行结果

实例十三 体育竞技分析
介绍
利用程序模拟运动员参与多场比赛,从而分析出该运动员的获胜概率。
总体框架如下:
1.打印程序的介绍性信息
2.获得程序运行参数: proA,proB,
3.利用球员A与B的能力值,模拟n局比赛
4.输出球员A和B获胜比赛的场次及概率
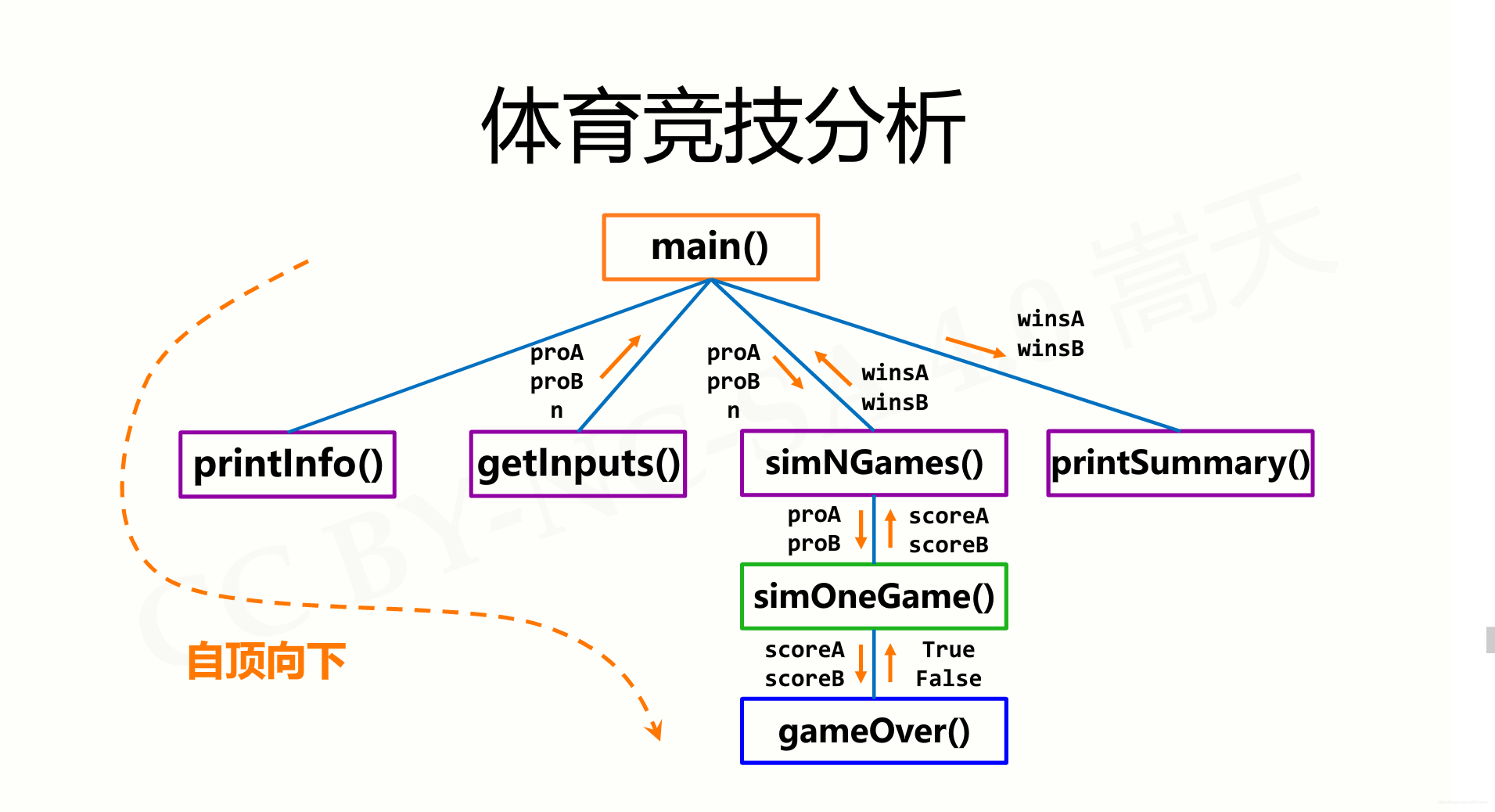
代码
import random
def printIntro(): # 介绍性内容,提高用户体验
print("这个程序模拟两个选手A和B的某种竞技比赛")
print("程序运行需要A和B的能力值(以0到1之间的小数表示)")
def getInputs(): # 获得输入参数
a = eval(input("请输入选手A的能力值(0-1):"))
b = eval(input("请输入选手B的能力值(0-1):"))
n = eval(input("模拟比赛的场次:"))
return a, b, n
def simNGames(n, probA, probB): # 模拟n场比赛
winsA, winsB = 0, 0
for i in range(n):
scoreA, scoreB = simOneGame(probA, probB)
if scoreA > scoreB:
winsA += 1
else:
winsB += 1
return winsA, winsB
def simOneGame(probA, probB): # 模拟一场比赛
scoreA, scoreB = 0, 0
serving = "A"
while not gameOver(scoreA, scoreB):
if serving == "A":
if random.random() < probA:
scoreA += 1
else:
serving = "B"
else:
if random.random() < probB:
scoreB += 1
else:
serving = "A"
return scoreA, scoreB
def gameOver(a, b): # 通过分数判断局的结束
return a == 15 or b == 15
def printSummary(winsA, winsB):
n = winsA + winsB
print("竞技分析开始,共模拟{}场比赛".format(n))
print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA, winsA / n))
print("选手B获胜{}场比赛, 占比{:0.1%}".format(winsB, winsB / n))
def main():
printIntro()
probA, probB, n = getInputs()
winsA, winsB = simNGames(n, probA, probB)
printSummary(winsA, winsB)
main()
运行结果
这个程序模拟两个选手A和B的某种竞技比赛
程序运行需要A和B的能力值(以0到1之间的小数表示)
请输入选手A的能力值(0-1):0.48
请输入选手B的能力值(0-1):0.49
模拟比赛的场次:1000
竞技分析开始,共模拟1000场比赛
选手A获胜512场比赛,占比51.2%
选手B获胜488场比赛, 占比48.8%
Process finished with exit code 0
实例十四 第三方库安装脚本
介绍
第三方库批量自动安装
代码
import os
libs = {"numpy", "matplotlib", "pillow", "sklearn", "requests",
"jieba", "beautifulsoup4", "wheel", "networkx", "sympy",
"pyinstaller", "django", "flask", "werobot", "pyqt5",
"pandas", "pyopengl", "pypdf2", "docopt", "pygame"}
try:
for lib in libs:
os.system("pip install" + lib)
print("sucessful")
except:
print("Failed Somehow")
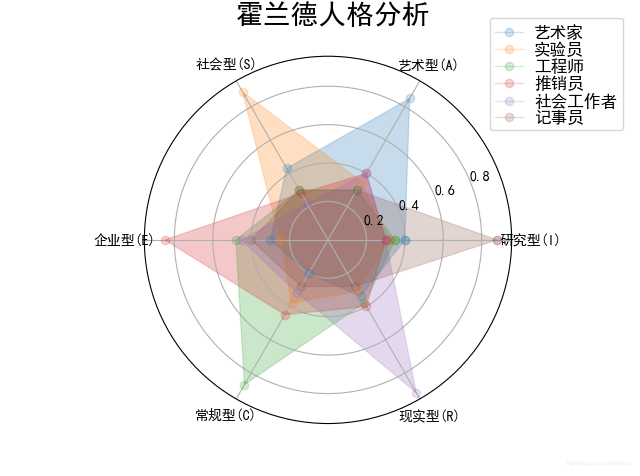
实例十五 霍兰德人格分析雷达图
代码
# HollandRadarDraw
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'SimHei'
radar_labels = np.array(['研究型(I)', '艺术型(A)', '社会型(S)',
'企业型(E)', '常规型(C)', '现实型(R)']) # 雷达标签
nAttr = 6
data = np.array([[0.40, 0.32, 0.35, 0.30, 0.30, 0.88],
[0.85, 0.35, 0.30, 0.40, 0.40, 0.30],
[0.43, 0.89, 0.30, 0.28, 0.22, 0.30],
[0.30, 0.25, 0.48, 0.85, 0.45, 0.40],
[0.20, 0.38, 0.87, 0.45, 0.32, 0.28],
[0.34, 0.31, 0.38, 0.40, 0.92, 0.28]]) # 数据值
data_labels = ('艺术家', '实验员', '工程师', '推销员', '社会工作者', '记事员')
angles = np.linspace(0, 2 * np.pi, nAttr, endpoint=False)
data = np.concatenate((data, [data[0]]))
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(facecolor="white")
plt.subplot(111, polar=True)
plt.plot(angles, data, 'o-', linewidth=1, alpha=0.2)
plt.fill(angles, data, alpha=0.25)
plt.thetagrids(angles * 180 / np.pi, radar_labels, frac=1.2)
plt.figtext(0.52, 0.95, '霍兰德人格分析', ha='center', size=20)
legend = plt.legend(data_labels, loc=(0.94, 0.80), labelspacing=0.1)
plt.setp(legend.get_texts(), fontsize='large')
plt.grid(True)
plt.savefig('holland_radar.jpg')
plt.show()
运行结果