获取网页源码
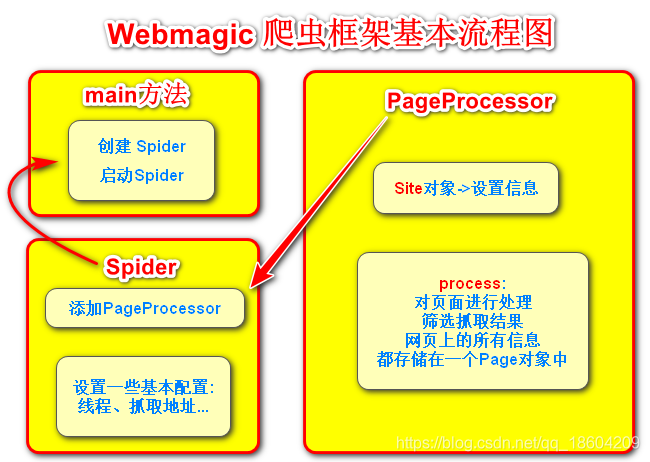
程序入口Spider
Spider 一般写在Main方法里
它可以设置爬虫的配置,包括编码、抓取间隔、超时时间、重试次数等,也包括一些模拟的参数,例如User Agent、cookie,以及代理的设置
public static void main(String[] args) {
//创建爬虫解析页面
PageProcessor pageProcessor = new FirstWebmagic();
//创建爬虫
Spider spider = Spider.create(pageProcessor);
//给爬虫添加爬取地址
spider.addUrl("https://xiaoshuai.blog.csdn.net/");
//启动一个线程
spider.thread(1);
//启动爬虫
spider.run();
}
编写PageProcessor
在WebMagic里,实现一个基本的爬虫只需要编写一个类,实现PageProcessor接口即可。这个类基本上包含了抓取一个网站,你需要写的所有代码。
下面来看一下这个接口里面有什么
/** 负责解析页面,抽取有用信息,以及发现新的链接 **/
public interface PageProcessor {
/**
* 处理页面,提取要提取的 URL,提取数据和存储
*
* @param Page page 页面信息
*/
public void process(Page page);
/**
* 获取设置信息
*
* @return site
* @see Site
*/
public Site getSite();
}
Site 配置信息
主要是设置 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
这里我们在getSite()方法里写上
@Override
public Site getSite() {
Site site = Site.me();//创建Site
site.setTimeOut(1000);//设置超时
site.setRetryTimes(3);//设置重试次数
return site;
}
process 页面处理
process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
所有抓取的信息都在这里
我们可以根据需要获取想要的结果
@Override
public void process(Page page) {
//抓取到的页面为一个page对象
Html html = page.getHtml();//我们从page里面获取Html信息
System.out.println(html);//然后一个html源代码就输出到控制台了
}
一个完整的代码示例
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class FirstWebmagic implements PageProcessor {
@Override
public void process(Page page) {
//抓取到的页面为一个page对象
Html html = page.getHtml();//我们从page里面获取Html信息
System.out.println(html);//然后一个html源代码就输出到控制台了
}
@Override
public Site getSite() {
Site site = Site.me();//创建Site
site.setTimeOut(1000);//设置超时
site.setRetryTimes(3);//设置重试次数
return site;
}
public static void main(String[] args) {
//创建爬虫解析页面
PageProcessor pageProcessor = new FirstWebmagic();
//创建爬虫
Spider spider = Spider.create(pageProcessor);
//给爬虫添加爬取地址
spider.addUrl("https://xiaoshuai.blog.csdn.net/");
//启动一个线程
spider.thread(1);
//启动爬虫
spider.run();
}
}