前言
在业务中,经常碰到需要从外部批量读取数据然后导入到mysql等数据库的操作,通常情况下,我们使用一个insert语句就可以完成,但在数据量为上万甚至百万的时候,这样做是不是太耗时了呢?
下面我们先来看一个简单的案例,在数据库中我们提前建立了一个表,将通过程序导入10000条数据到这张表,
方式1:单线程insert
# -*- coding:utf-8 -*-
import time
from pymysql import *
# 装饰器,计算插入10000条数据需要的时间
def timer(func):
def decor(*args):
start_time = time.time()
func(*args)
end_time = time.time()
d_time = end_time - start_time
print("这次插入10000条数据耗时 : ", d_time)
return decor
@timer
def add_test_users():
conn = connect(host='localhost',user='root',password='root',database='db1',charset='utf8')
cs = conn.cursor()
for num in range(0, 10000):
try:
sql = "insert into user1(uid,uname,email) values(%s,%s,%s);"
params = (num, "zcy", "[email protected]")
cs.execute(sql,params)
except Exception as e:
return
conn.commit()
cs.close()
conn.close()
print('OK')
if __name__ == '__main__':
add_test_users()
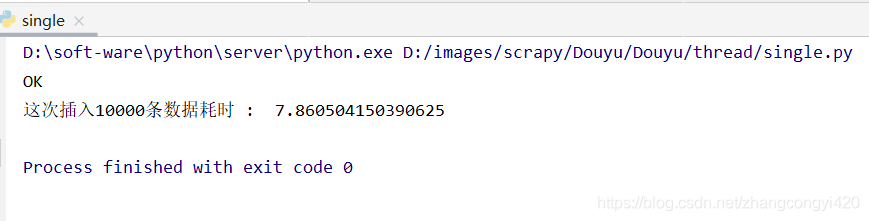
通过单线程插入随机的1万条数据花费了7秒左右的时间
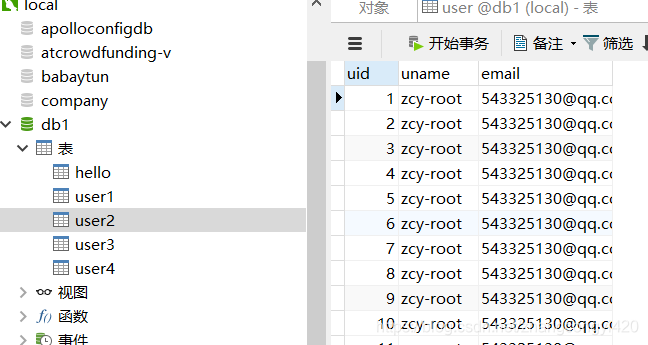
另外,pymysql还提供了isnertMany的语法,只需要一次执行,就可以把语句传递给,mysql,让mysql的引擎去执行,如下,我们再在user2表中插入1万条数据
# -*- coding:utf-8 -*-
import time
from pymysql import *
# 装饰器,计算插入10000条数据需要的时间
def timer(func):
def decor(*args):
start_time = time.time()
func(*args)
end_time = time.time()
d_time = end_time - start_time
print("这次插入10000条数据耗时 : ", d_time)
return decor
@timer
def add_test_users():
#将待插入的数据先进行遍历,处理放到一个元祖的列表里面
usersvalues = []
for num in range(1, 10000):
usersvalues.append((num,'zcy-root','[email protected]'))
conn = connect(host='localhost',user='root',password='root',database='db1',charset='utf8')
cs = conn.cursor() # 获取光标
# 注意这里使用的是executemany而不是execute,下边有对executemany的详细说明
cs.executemany('insert into user2 (uid,uname,email) values(%s,%s,%s)', usersvalues)
conn.commit()
cs.close()
conn.close()
print('OK')
if __name__ == '__main__':
add_test_users()
执行程序,这一次只花费了2秒多的时间,相当于是提升了3倍的速度,明显通过isnertMany的语法要快不少,而且使用这种方式的好处在于,在执行数据插入之前我们可以对待插入的数据做前置的处理

方式2:使用futures的ProcessPoolExecutor进程池
ProcessPoolExecutor组件类似于java中的异步线程池,原理类似,即在它底层可以通过线程调度开启多线程的方式协同处理任务,既然是多线程,处理数据的速度理论上来讲,在涉及到大量的数据的时候其处理的性能会提升不少
我们再创建一个user3的表,往里面插入1万条数据
编写代码如下,
import pymysql
import requests,time
from concurrent.futures import ProcessPoolExecutor
def data_handler(urls):
conn = pymysql.connect(host='localhost',user='root',password='root',database='db1',charset='utf8')
cursor = conn.cursor()
for i in range(urls[0], urls[1]):
sql = 'insert into user3(uid,uname,email) values(%s,%s,concat(%s,"hello","@qq.com"));'
res = cursor.execute(sql, [i, "root", i])
conn.commit()
cursor.close()
conn.close()
def run():
urls = [(1,2000),(2001,5000),(5001,8000),(8001,10000)]
with ProcessPoolExecutor() as excute:
##ProcessPoolExecutor 提供的map函数,可以直接接受可迭代的参数,并且结果可以直接for循环取出
excute.map(data_handler,urls)
if __name__ == '__main__':
start_time = time.time()
run()
stop_time = time.time()
print('插入1万条数据耗时 %s' % (stop_time - start_time))
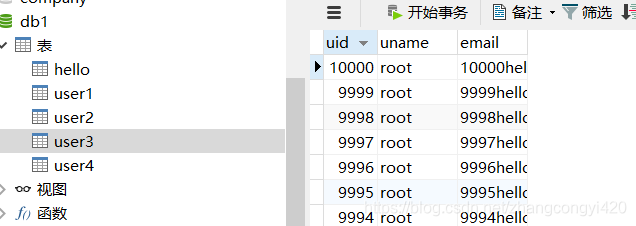
这段代码的核心思想在于将10000条数据分成不同的等分,每个线程各自处理一等分的数据,多线程协同处理效率自然就高了,运行这段程序,
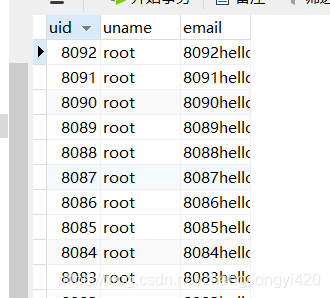
在程序运行过程中,我发现了一个问题就是,在3秒左右的时候,已经处理了8000多条数据,但是此后速度变慢了,反而耗费了很久才执行完毕,分析了一下原因,可能是我的机器本身性能不够好导致CPU在进行上下文切换的时候效率降低了,但这并不能说明这个组件本身的问题,也有可能是数据量还不够大,这个组件的优势还没有完全的体现出来
方式3:使用协程gevent
这也是一个类似多线程的组件
from gevent import monkey;monkey.patch_all()
import gevent
import time
import pymysql
def data_handler(anum,num):
conn = pymysql.connect(host='localhost',user='root',password='root',database='db1',charset='utf8')
cursor = conn.cursor()
for i in range(anum,num):
sql = 'insert into user4(uid,uname,email) values(%s,%s,concat(%s,"hello","zcy@163"));'
res = cursor.execute(sql,[i,"root",i])
conn.commit()
cursor.close()
conn.close()
start_time=time.time()
gevent.joinall([
gevent.spawn(data_handler,1,2000),
gevent.spawn(data_handler,2001,5000),
gevent.spawn(data_handler,5001,8000),
gevent.spawn(data_handler,8001,100001),
])
stop_time=time.time()
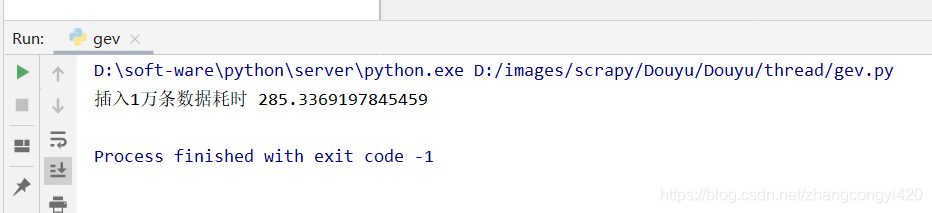
print('本次耗时 %s' %(stop_time-start_time))
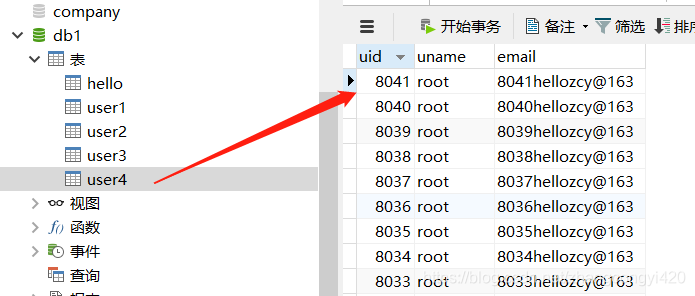
同样我们再数据库创建一个名为user4的表,执行这段程序,这段程序的运行效果和上面的差不多,也出现了先快后慢的效果

方式4:使用threading+queue+连接池的方式
换一个思路,我们使用python原生的多线程的方式,大前提仍然是将数据划分成不同的等分,让每个线程都处理一部分的数据
但如果按照前文的第一种方式,直接insert的话会有一个瓶颈就是,数据库的连接会有上限,连接数是固定的,要提升的话只能通过提升机器的性能了,所以考虑使用数据库连接池加多线程的思路解决
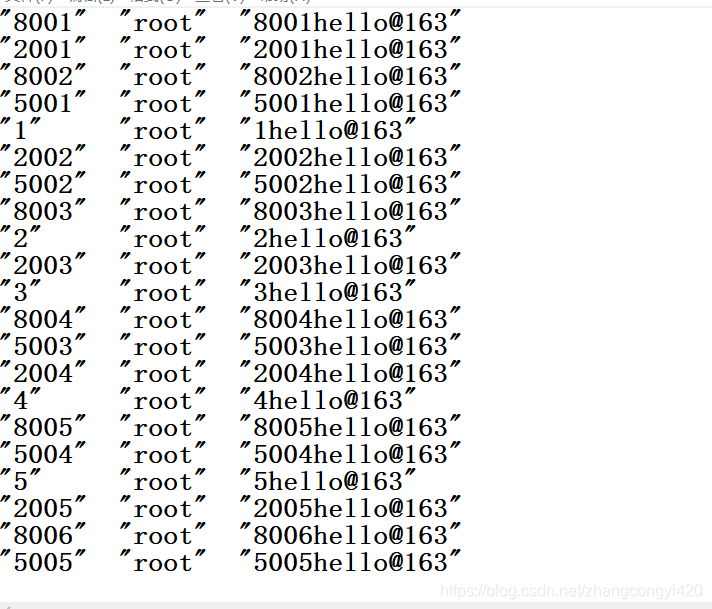
建立一张user5的空表,这一次数据源是从外部的一个txt中读取数据到程序,然后通过程序将数据导入到user5中,实际业务中,数据源可能是excel等
整体代码如下:
import pymysql
import threading
import re
import time
from queue import Queue
from DBUtils.PooledDB import PooledDB
class ThreadInsert(object):
def __init__(self):
start_time = time.time()
self.pool = self.mysql_connection()
self.data = self.getData()
self.mysql_delete()
self.task()
print("========= 数据插入,共耗时:{}'s =========".format(round(time.time() - start_time, 3)))
#数据库连接
def mysql_connection(self):
maxconnections = 15 # 最大连接数
pool = PooledDB(
pymysql,
maxconnections,
host='localhost',
user='root',
port=3306,
passwd='root',
db='db1',
use_unicode=True)
return pool
#从本地的文件中读取数据
def getData(self):
st = time.time()
with open("D:\\logs\\user2.txt", "rb") as f:
data = []
for line in f:
line = re.sub("\s", "", str(line, encoding="utf-8"))
line = tuple(line[1:-1].split("\"\""))
data.append(line)
n = 1000 # 按每1000行数据为最小单位拆分成嵌套列表,可以根据实际情况拆分
result = [data[i:i + n] for i in range(0, len(data), n)]
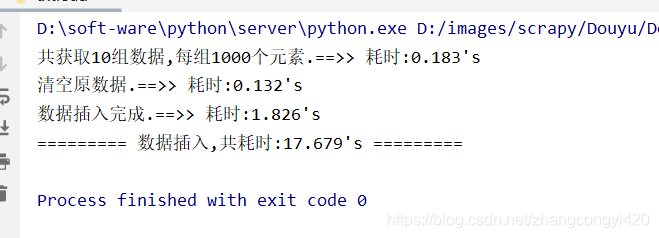
print("共获取{}组数据,每组{}个元素.==>> 耗时:{}'s".format(len(result), n, round(time.time() - st, 3)))
return result
#数据库回滚
def mysql_delete(self):
st = time.time()
con = self.pool.connection()
cur = con.cursor()
sql = "TRUNCATE TABLE user5"
cur.execute(sql)
con.commit()
cur.close()
con.close()
print("清空原数据.==>> 耗时:{}'s".format(round(time.time() - st, 3)))
#数据插入
def mysql_insert(self, *args):
con = self.pool.connection()
cur = con.cursor()
sql = "INSERT INTO user5(uid, uname, email) VALUES(%s, %s, %s)"
try:
cur.executemany(sql, *args)
con.commit()
except Exception as e:
con.rollback() # 事务回滚
print('SQL执行有误,原因:', e)
finally:
cur.close()
con.close()
#开启多线程任务
def task(self):
# 设定最大队列数和线程数
q = Queue(maxsize=10)
st = time.time()
while self.data:
content = self.data.pop()
t = threading.Thread(target=self.mysql_insert, args=(content,))
q.put(t)
if (q.full() == True) or (len(self.data)) == 0:
thread_list = []
while q.empty() == False:
t = q.get()
thread_list.append(t)
t.start()
for t in thread_list:
t.join()
print("数据插入完成.==>> 耗时:{}'s".format(round(time.time() - st, 3)))
if __name__ == '__main__':
ThreadInsert()
运行这段程序,从时间上来看,还是可以的,但由于是从外部读取文件处理了之后再往数据库插入的,整体上来说,性能也还不错,而且更符合实际的应用场景,建议使用
以上便是本文的全部内容,当然,实际应用中场景可能更复杂,需要在程序中做其他的逻辑处理,都可以在此基础上进行扩展,最后感谢观看!
