-
描述一下JVM加载class文件的原理机制
答:JVM中类的装载是由类加载器(ClassLoader)和它的子类来实现的,Java中的类加载器是一个重要的Java运行时系统组件,它负责在运行时查找和装入类文件中的类。
由于Java的跨平台性,经过编译的Java源程序并不是一个可执行程序,而是一个或多个类文件。当Java程序需要使用某个类时,JVM会确保这个类已经被加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class对象。加载完成后,Class对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。最后JVM对类进行初始化,包括: 1) 如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类; 2) 如果类中存在初始化语句,就依次执行这些初始化语句。
类的加载是由类加载器完成的,类加载器包括:根加载器(BootStrap)、扩展加载器(Extension)、系统加载器(System)和用户自定义类加载器(java.lang.ClassLoader的子类)。从Java 2(JDK 1.2)开始,类加载过程采取了父亲委托机制(PDM)。PDM更好的保证了Java平台的安全性,在该机制中,JVM自带的Bootstrap是根加载器,其他的加载器都有且仅有一个父类加载器。类的加载首先请求父类加载器加载,父类加载器无能为力时才由其子类加载器自行加载。JVM不会向Java程序提供对Bootstrap的引用。下面是关于几个类加载器的说明:
Bootstrap:一般用本地代码实现,负责加载JVM基础核心类库(rt.jar);
Extension:从java.ext.dirs系统属性所指定的目录中加载类库,它的父加载器是Bootstrap;
System:又叫应用类加载器,其父类是Extension。它是应用最广泛的类加载器。它从环境变量classpath或者系统属性java.class.path所指定的目录中记载类,是用户自定义加载器的默认父加载器。 -
byte a=5; byte b; b=b+a;能编译通过吗?
答:不能,因为int转byte会精度损失,所以需要强制类型转换。 -
byte a=5; byte b; b=(byte)(b+a);能编译通过吗?
答:不能,因为b没有给初始化值 -
整型的数值默认为
int类型,小数的数据默认为double类型;小数据类型与大数据类型运算,结果自动转向大数据类型
大数据类型值赋值给小数据类型值需要强制转换,否则报错从大到小可能会有损失,如byte b = (byte)200; -
byte数据类型范围为-128~127,如果超过这个区间则需要强转赋值,如byte b = (byte)-129;或byte b = (byte)128,不强转赋值则会报错不兼容的类型: 从int转换到byte可能会有损失。
同理:byte、short、int、long只要不超过int的范围就可以直接赋值,否则需要强制转换,long类型的数据只需要在最后加L或l -
float数据类型赋值小数时需要在数值后面加F或f -
数字与字符串类型相+时,如果有数字运算在字符串之前,则先计算数字运算,然后以字符串形式与后面的字符串合并 -
什么是java虚拟机,什么是java的虚拟机实例?
答:java虚拟机相当于我们的一个java类,而java虚拟机实例相当于我们new一个java类,不过java虚拟机不是通过new这个关键字而是通过java.exe或者javaw.exe来启动一个虚拟机实例。 -
JVM的生命周期是怎样的?
答:当一个java应用的main函数启动时虚拟机也同时被启动,而只有当在虚拟机实例中的所有非守护线程都结束时,java虚拟机实例才结束生命。 -
JVM虚拟机的内部体系结构
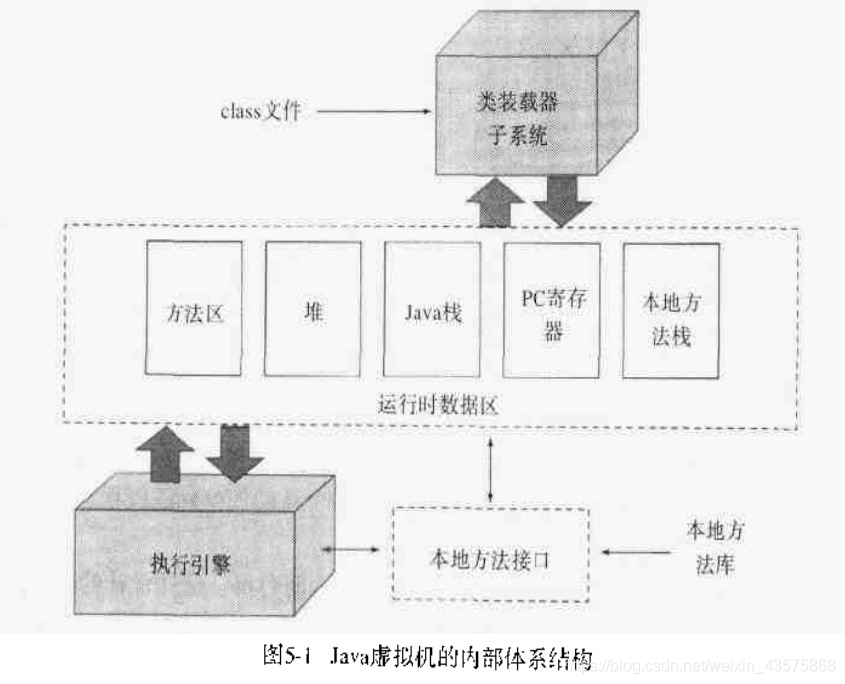
-
一张图看懂JVM:https://www.cnblogs.com/bigben0123/p/9685474.html,挺详细
-
JVM基本结构:https://blog.csdn.net/yfqnihao/article/details/8289363,理解深入易懂
-
为什么在建表时不能使用外键和级联更新?
答:外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。 -
数组学习中的常见问题:第一种:
编译错误,array未初始化变量int[] array; System.out.println(array); 编译错误,array未初始化变量第二种:
编译通过,运行错误NullPointerException空指针异常int[] arr3 = null; System.out.println(arr3); 输出结果,null System.out.println(arr3[0]); 运行报错,空指针异常第三种:
编译通过,运行错误ArrayIndexOutOfBoundsException数组索引越界异常int[] arr4 = new int[1]; System.out.println(arr4[1]); 数组索引越界ArrayIndexOutOfBoundsException第四种:
int、char和String的直接输出名称结果和分配空间后的默认值int[] arr5 = new int[1]; System.out.println(arr5); /输出结果:数组地址 System.out.println(arr5[0]); /输出结果:0,数组分配空间后int类型默认是0 char[] arr6 = new char[]{'a','b','c','d'}; System.out.println(arr6); /输出结果:abcd,出现这种情况的原因: /因为java中规定数组都是对象,所以println(Object)输出的都是这个数组对象的哈希值。 而对于char型数组,println()有专门的重载形式---println(char[]), 它输出的是数组的值。这个是源码里已经设置好了的。 char[] arr66 = new char[1]; System.out.println(arr66[0]); /输出结果:空格 String[] arr7 = new String[1]; System.out.println(arr7); /输出结果:数组地址 System.out.println(arr7[0]); /输出结果:null,数组分配空间后String类型默认null char[] arr8 = new char[1]; System.out.println(arr8+"a"); /输出结果:[C@15db9742a (char数组地址+字符串值) /原因还是由于println()只是对char类型数组重载,对于String类型对象依然是输出地址 System.out.println(arr8[0]+"a");/输出结果: a(空格a) -
下列哪些是方法是public int add (int a)的重载方法?( A C D ) (多选)
A. public int add (long a);
B. public void add (int a); // 叫做方法的重复定义
C. public void add (long a);
D. public int add (float a);
//重载为定义在同一个类中,方法名字相同,参数列表不同(1. 参数个数不同 2. 参数类型不同 3. 不同类型参数间的排列顺序 ),与方法的返回值无关 -
对象的创建内存图运行过程
class 对象的创建内存图 { public static void main(String[] args) { C c=new C(10); } } class C { int n=5; public C(){ System.out.println(n); } public C(int n){ System.out.println("1======="+this.n); this.n=n; System.out.println("2=========="+this.n); } }答:
1.当jvm 加载当前的类到方法区之后,main方法开始压栈。
2.在栈中 ,创建一个名称为c的,数据类型为C的变量的空间。
3.加载C类的信息到方法区,开始在堆中创建C类的对象。
4.对象的属性经过三种初始化 :
① 默认初始化:在开辟属性的空间时。执行。
② 显式初始化:在构造方法中,但是没有执行构造方法中的代码时,执行
③ 构造初始化:在构造方法中修改
5.假设 该对象的地址为0x15
6.将0x15的值赋给引用变量c。 -
方法与构造方法的区别与联系
答:区别:
① 写法上
1》 构造方法 名称必须是类名,并且没有返回值。
2》 方法 名称可以是任意的标识符,必须有返回值,无论是void或者返回值数据类型。
② 调用:
1》 构造方法 调用 通过new关键字来进行调用。
2》 方法 调用 通过对象来进行调用。
③ 对象 :
1》 构造方法 对于同一个对象,只能调用一次。
2》 方法 对于同一个对象,无数次。
④ 功能 :
1》 构造方法 功能 创建对象 和初始化对象
2》 方法 功能 实现了某种功能
联系:
① 构造方法也是方法,实现某些功能。
② 构造方法与方法都有重载形式。 -
Java中静态代码块、构造代码块、构造方法、普通代码块、成员变量初始化顺序
答:父类静态代码块(静态成员变量)>子类静态代码块(静态成员变量)>父类构造代码块(普通成员变量)>父类构造方法>子类构造代码块(普通成员变量)>子类构造方法 -
this、super的区别和应用场景
答:super关键字是子类调用父类的成员,它包括父类的public、protected修饰的变量、方法等等super.父类的方法子类调用父类的方法1、super从子类中调用父类的构造方法,this在同一类内调用其它方法
2、this和super不能同时出现在一个构造函数里面
3、this或super调构造器时必须放在第一句,如果不放在第一句则可能对父类的数据多次初始化
4、this和super都指的是对象,所以,均不可以在static环境下使用 -
final、finally和finalize的区别
答:final:是最终的意思,可以修饰类,成员变量,成员方法。
修饰类,类不能被继承;修饰方法,方法不能被重写但是可以继承;修饰变量,变量就变成了常量,只能被赋值一次,也可以继承
finally:是异常处理的一部分,用于释放资源一般来说,代码肯定会执行,特殊情况:在执行到finally之前jvm退出了
finalize:是Object类的一个方法,用于垃圾回收 -
继承时需要注意哪些?
答:子类覆盖父类方法时的要求:两同、两小、一大
1.方法名和参数列表必须相同:子类==父类
2.返回值类型和抛出异常:子类<=父类
3.权限修饰符:子类>=父类
子类无法覆盖父类的:
(1)构造方法 (2)static声明的静态方法 (3)private声明的私有方法 (4)final声明的最终方法 -
JAVA 继承 父类子类 内存分配图解https://blog.csdn.net/erica_1230/article/details/76571936 -
子类在继承父类后,实例化子类时,父类被实例化了吗?父类的成员变量和方法存在于堆内存中的哪里?
答:子类在继承父类后,如果父类中有非静态非私有(普通)的成员变量,那么在堆里子类对象内存中给这些父类的成员变量再分配一些内存,并且子类对象内存中存的只是父类的一个引用,并没有给父类实例化,通过super来调用子类对象内部的父类的特征(属性和方法)。(还不懂就看JAVA 继承 父类子类 内存分配图解这一题的网址) -
多态成员访问的特点?
答:比如有个类B继承类A,A a = new B()
成员变量:编译看左边看A类里的,运行看左边看B类里的,但是如果在B类里对成员变量赋值了,那么更改的也只是堆内存中子类(B类)对象内存中为父类(A类)分配的那一块内存中的成员变量,对类A没有影响。例子如下:class test { public static void main(String[] args) { A a = new B(); System.out.println(a.a);//结果为10,因为B类中没有对分配给父类变量的一块内存赋值 } } class A{ int a =10; } class B extends A{ int a = 30; }class test { public static void main(String[] args) { A a = new B(); // 运行结果为20 30 System.out.println(a.a);// 结果为20 } } class A{ int a =10; } class B extends A{ int a = 30; public B(){ super.a = 20; System.out.println(super.a);// 结果为20 System.out.println(this.a);// 结果为30 } }成员方法:编译看左边,运行看右边,如25的练习题
构造方法:创建子类对象时,先访问父类的构造方法,对父类的数据进行初始化,子类构造器里面默认有super();
静态方法:编译看左边,运行看左边(静态和类相关,算不上重写,还是看左边) -
多态练习题
// 无结果,有结果的在下面 class A { public String show(D obj){ // D obj=d; return ("A and D"); } public String show(A obj){ return ("A and A"); } } class B extends A { public String show(B obj) { return ("B and B"); } public String show(A obj) { return ("B and A"); } } class C extends B{} class D extends B{} public class Test { public static void main(String[] args) { A a1 = new A(); A a2 = new B(); B b = new B(); C c = new C(); D d = new D(); System.out.println(a1.show(b)); System.out.println(a1.show(c)); System.out.println(a1.show(d)); System.out.println(a2.show(b)); System.out.println(a2.show(c)); System.out.println(a2.show(d)); System.out.println(b.show(b)); System.out.println(b.show(c)); System.out.println(b.show(d)); } }class A { public String show(D obj){ // D obj=d; return ("A and D"); } public String show(A obj){ return ("A and A"); } } class B extends A { public String show(B obj) { return ("B and B"); } public String show(A obj) { // A a2 = new B() return ("B and A"); } } class C extends B{} class D extends B{} public class Test { public static void main(String[] args) { A a1 = new A(); A a2 = new B(); B b = new B(); C c = new C(); D d = new D(); System.out.println(a1.show(b)); // 因为B类是A类的子类,所以结果为① A and A System.out.println(a1.show(c)); // 因为C是B的子类,B是A的子类,所以结果为② A and A System.out.println(a1.show(d)); // 因为有直接接收D类的方法,所以结果为③ A and D System.out.println(a2.show(b)); // 多态的方法编译看左边看A类show方法,运行看右边看B类show方法, // A里有接收B的方法(原因同1(即①)),B里也有,走B,所以结果为④ B and A System.out.println(a2.show(c)); // 原因看2②和4④,所以结果为⑤ B and A System.out.println(a2.show(d)); // 编译看左边看A类show方法,运行看右边看B类show方法 // A类有接收D的方法,所以结果为⑥ A and D System.out.println(b.show(b)); // 直接看B类里的show方法,所以结果为⑦ B and B System.out.println(b.show(c)); // 因为C继承B,B继承A,并且两个方法都可以接收C,但是按辈分最近的接收 // 所以结果为⑧ B and B System.out.println(b.show(d)); // 虽然里面有个接收B的show方法可以接收 // 但是B继承A,所以B里面有直接接收D的show方法 // 所以结果为⑨ A and D } } -
String类对象创建内存图
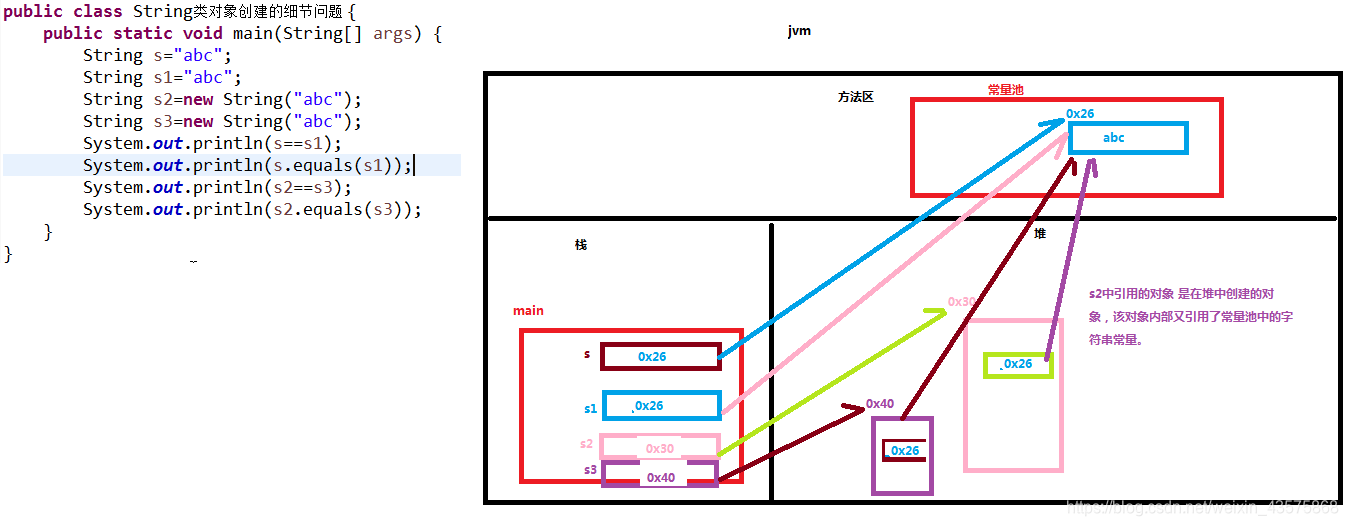
-
String对象创建的细节问题
答:常量池:jdk1.6时,常量池在方法区;jdk 1.7后,移除了方法区间,运行时常量池和字符串常量池都在堆中。
理解java中String字符串常量池
https://blog.csdn.net/qq_27093465/article/details/52250033
https://www.cnblogs.com/shoshana-kong/p/11249311.html
***(这个帖子详细)https://www.cnblogs.com/tongkey/p/8587060.html
***https://blog.csdn.net/zzzgd_666/article/details/87999870#commentBox
对于两个声明的字符串使用 " + " 拼接, 因为jvm的优化,会将拼接后的结果放入常量池.但是两个声明的字符串不会,(String s = “abc”+ “def”, 会直接生成“abcdef"字符串常量 而不把 “abc” "def"放进常量池)String ss3 = new String("hello") + new String("hello"); // new + new 或者 "a"+new 都是在堆中分配一块空间,返回给ss3在堆中新的对象的地址 String ss4 = "hellohello"; // 字符串常量直接从字符串常量池中找hellohello,有的话直接引用,没有创建再引用 String intern3 = ss3.intern(); // intern():如果常量池中已经存在该字符串,则直接返回常量池中该对象的引用。否则,在常量池中加入该对象,然后 返回引用 // 调用ss3.intern()方法会先检查字符串池中是否含有该字符串,有的话则直接得到引用地址 // 没有的话则将堆中ss3对象的引用存放到字符串常量池 System.out.println(ss3.hashCode()); System.out.println(ss4.hashCode()); //hashCode()获取的是常量池里的地址,这里直接找的是hellohello的地址,所以ss3与ss4的hashCode()相同 System.out.println(ss3 == ss4);//false System.out.println(ss4==intern3);//trueString ss = new String("hello")创建了两个对象,一个对象是常量池中创建的"hello",另一个对象是堆中分配的内存,ss指向的就是堆中内存的地址。
String ss3 = new String("hello") + new String("hello");new + new 或者 “a”+new 都是在堆中分配一块空间并且内存中存入了"hellohello",并没有在常量池中创建"hellohello",返回给ss3的是在堆中新的对象的地址。当调用ss3.intern()时,jdk1.6之前的是在常量池中创建一份"hellohello",而jdk1.7之后的是在常量池中创建一份ss3的引用,我用的是jdk1.8版本,String ss4="hellohello"中的ss4获取的是常量池中存储的ss3的引用,所以ss3==ss4为true -
String、StringBuffer和StringBuilder的区别?
答:String是不可变字符串,长度不可改变;StringBuffer是线程安全的可变字符序列,可以改变该对象的值和长度;StringBuilder是线程不安全的可变字符序列,但是执行速度快。 -
泛型在class文件中不存在,只是在编译器存在。叫可擦除技术 -
ArrayList、LinkedList和Vector的区别?
答:ArrayList:底层-可变大小的数组;特点-有序、可重复(查询快、增删慢、线程不安全)
遍历的方式:(五种)1、数组:toArray()—>Object[]
2、迭代器:Iterator
3、特有的迭代器ListIterator
4、一般for
5、增强for
LinkedList:底层-双向链表;特点-有序、可重复(增删快、查询慢、线程不安全)
Vector:底层-数组;特点-有序、可重复(线程安全) -
泛型的使用
- 泛型概念:
①参数化类型。数据类型不同,数据类型的位置是变量,随着变量值的不同,数据类型也不同。 - 泛型格式:<标识符>
标识符一般用ETKV来进行表示,其中E通常用来表示Element 元素,K Key 键,V value 值,T type 类,这些没有实际含义。 - 泛型的分类
泛型类
格式:class 类名<泛型,泛型,泛型> { }public class 泛型类 { public static void main(String[] args) { /*B<String> b=new B(); b.add("1", "2"); B<Integer> b1=new B(); b1.add(1, 2);*/ B<String,Integer> b2=new B(); b2.add("1", 3); } } /泛型类 多个用逗号隔开 class B<M,V>{ public void add(M a,V b) {} }泛型接口
格式:①泛型具体,子类可以不带泛型
②泛型不具体,子类也需要带泛型public class 泛型接口 { public static void main(String[] args) { ZiT1 z=new ZiT1(); z.add("1", "2"); ZiT2<Integer> zt=new ZiT2(); zt.add(1, 2); } } interface T<E>{ public void add( E a, E b); } //泛型接口的两种实现形式 ,① 泛型具体,子类可以不带泛型 class ZiT1 implements T<String>{ @Override public void add(String a, String b) { } } //泛型接口的两种实现形式 ,② 泛型不具体,子类也需要带泛型 class ZiT2<M> implements T<M>{ @Override public void add(M a, M b) { } }泛型方法
格式: 权限修饰符 修饰符<泛型>返回值类型 方法名称(参数){ }
注意:1、泛型方法是在方法上声明了泛型,而不是使用了泛型的方法。
使用类或者接口的泛型这些方法不算泛型方法。
2、类或者接口的泛型只能用在非静态方法中,不能用于静态方法,对于静态方法,只能使用泛型方法的形式。public class 泛型方法 { public static void main(String[] args) { K<String> k=new K(); k.add("123", "123"); k.add("123", 123); } } class K<M>{ //V 表示的泛型仅在该方法中使用,该类的其它方法不使用。 //泛型的方法 格式 : 返回值前加 泛型的声明 public <V>void add(M a, V b) { } //静态方法 只能使用泛型方法,不能使用类或接口上的泛型。 public static <K>void div(K a) { } }- 通配符
<? extends E>: 只能传入E的子类
<? super E>:只能传入E的父类
- 泛型概念:
-
树的遍历方式:
- 先序遍历:根左右
- 中序遍历:左根右
- 后序遍历:左右根
-
HashSet集合底层、特点、去重复问题
答:底层是哈希表(由HashMap实现,是HashMap的key列),特点是不重复、无序,去重复:重写equals()和hashCode() -
HashSet集合的存储过程
答:(简答)首先通过hashCode()比较哈希码值,根据哈希码值推算出该对象在集合中的存储位置,如果该位置上有对象,继续走equals()比较两个对象是否相等,如果相同不插入,不同就直接在该位置后面插入该元素对象。
(详细)1、首先通过对象的HashCode方法算出对象的哈希码值,根据哈希码值推算出该对象在集合中的存储位置。2、如果算出来的存储位置的索引值上有元素对象,这种现象称为哈希碰撞。需要存储的元素对象就与该位置上已经存在的对象进行比较,通过equals判断是否相等,如果相等不插入,否则在该位置后面插入该元素对象(jdk1.8之后该位置上如果插入的元素个数大于等于8个,则从链表形式改为红黑树的形式) -
TreeSet集合底层、特点、去重复问题
答:底层是红黑树(基于TreeMap),特点是不重复、无序、可排序,去重复:①实现Comparable< T>接口,重写compareTo(T o)方法②创建一个类implements Comparator< T>,实现compare(T o1,T o2)方法 -
TreeSet集合的存储过程
答:
(1) 元素的自然排序:
① Comparable 接口 ,实现该接口的类,可以对该类所对应的集合进行排序,这种排序 称为元素的自然顺序排序。
② 实现该接口的方法 :compareTo(T o)当这个方法的返回值 大于0 (对象在后) 小于0 (对象在前 ) 等于0 (相等)
(2)TreeSet集合默认无参构造方法,按照元素的自然顺序进行排序,要求存入该集合的元素自定义类的对象的所在类 必须要实现Comparable,实现接口中的方法:compareTo方法,否则会报异常 ClassCastException 类型转换异常。 -
LinkedHashSet集合
答:该集合由哈希表与双向链表组成,插入与存储顺序相同。一般用于购物车,商品历史记录。特点:有序 不重复 -
Map集合的特点
答:Map集合为双列集合,(1) 存储的元素是键值对的形式(2)键不能重复,值可以重复。(3)一个键只对应一个值。 -
通过Map集合来实现统计字符串中每个字符出现的次数
答:public static void main(String[] args) { // 统计一个字符串中每个字符出现的次数 String s = "adadsafqkjhdkjhkasasd"; //创建HashMap集合来存储字符和次数 Map<Character, Integer> map = new HashMap<>(); // 将字符串转化成字符数组 char[] charArr = s.toCharArray(); // 遍历字符数组统计字符个数 for(char ch : charArr) { if (map.containsKey(ch)) { // 如果hashMap集合中包含这个字符,则在原来的次数上加1 map.put(ch, map.get(ch)+1); }else { // 如果hashMap集合中不包含这个字符,则给这个字符一个初始次数 map.put(ch, 1); } } System.out.print(map); } -
HashMap、TreeMap、LinkedHashMap、HashTable的区别?
答:HashMap底层数据结构是哈希表,线程不安全,效率高,允许有null的键和值,输出是无序的;TreeMap底层数据结构是红黑树,线程不安全,允许有null的键和值,输出是有序的,按照Key键的自然顺序;HashTable底层数据结构是哈希表,线程安全,效率低,不允许有null的键和值;LinkedHashMap是Map接口的哈希表和链表实现,具有可预知的迭代顺序 -
匿名内部类的注意事项

-
TCP、UDP的特点是什么?
答:UDP:面向无连接的,通过数据报包进行传输,每个数据报包的大小不超过64k,传输速度快。实时性,不考虑数据的完整性。
TCP:传输控制协议,面向连接的、可靠的、基于字节流的传输层通信协议。
TCP与UDP区别总结:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
https://blog.csdn.net/q357010621/article/details/80150342 -
反射的方法
答:
Class中的方法:clazz.newInstance():利用无参构造创建对象clazz.getConstructor(String.class,int.class):获取有参构造器clazz.getDeclaredConstructor(int.class):可以获取所有修饰符修饰的构造方法clazz.getConstructors():只能获取公共的构造方法clazz.getDeclaredConstructors():所有构造方法,包含私有方法等方法.getFields():获取权限为公共的属性.getDeclaredFields():获取任意权限属性.getDeclaredField(String):可获取任意访问权限的属性,需要设置可访问.setAccessible(true).getField(String):只获取公共属性.getMethod(String methodName,Class parameterTypes):获取父类及自身的所有公共方法.getDeclaredMethod(String methodName,Class parameterTypes):获取自身类的所有方法
Field中的方法:
.set(Obj obj,Obj value):设置obj对象的Field值为value.get(Obj obj):获取obj对象的Field值
Method中的方法:
invoke(Object obj, Object... args): 方法的调用
-
lambda表达式的写法和实现
答:格式:
有参数无返回的写法:(参数) -> {方法体;};
有返回值的写法:(参数)->{return 返回值;}注意:只有返回语句时,省略大括号必须省略return。
实现:存在函数式接口lambda表达才可以使用,抽象类实现匿名内部类不可使用。
函数式接口:接口中只有一个抽象方法的接口,函数式接口里面可以有默认方法和静态方法,但是只有一个抽象方法。
interface TL{
public void fun();
//静态方法
public static void fun1() {
System.out.println("aaaa");
}
//默认方法
default void fun2() {
System.out.println("接口的默认方法");
}
}
- jdk1.8特性
答:Consumer消费型接口
例:Consumer consumer = System.out::println;
void accept(T t);Supplier供给型接口
例:Supplier supplier = () -> {return new Teacher();};
T get();Function函数型接口
例:Function<String,String> func = (x) -> x.concat(“hello”);
R apply(T t); Function<T,R> 参数为T类型的,返回值为R类型的Predicate断言型接口
boolean test(T t);- 方法引用:
为了进一步简化lambda的书写 ,如果这些方法已经存在了,lambda表达式实现只是为了调用这些已有方法,
可以采用方法引用的形式,来简化lambda表达式的书写。
格式 :::方法引用运算符
①对于静态方法 类名 :: 方法名
注意 方法名后面没有任何内容。
② 对于实例方法 对象名 :: 方法名
③ 对于对象创建 类名 :: new
// lambda表达式
T t = () ->System.out.println("aa");
t.get();
T t1 = () ->{ System.out.println("aa"); };
t1.get();
//这是lambda表达式返回值简写
T2 t2 = (x) -> x;
System.out.println("这是lambda表达式返回值简写:"+t2.get(123));
//这是lambda表达式带方法体和return返回的值
T2 t3 = (x) -> { return x;};
System.out.println("这是lambda表达式带方法体和return返回的值:"+t3.get(123));
//这是用lambda表达式实现Consumer内置函数式接口
Consumer<String> con =(x) -> System.out.println(x);
con.accept("这是用lambda表达式实现Consumer内置函数式接口");
//这是用方法引用实现Consumer内置函数式接口
Consumer<String> consumer = System.out::println;
consumer.accept("这是用方法引用实现Consumer内置函数式接口");
//这是实现Supplier供给型内置函数接口
Supplier<String> supp = () -> "1";
System.out.println("这是实现Supplier供给型内置函数接口"+supp.get());
//这是实现Supplier供给型内置函数接口
Supplier<Teacher> supplier = () -> {return new Teacher();};
Teacher teacher = supplier.get();
System.out.println("这是实现Supplier供给型内置函数接口"+teacher.name);
// 这是用引用方法实现Supplier供给型内置函数接口
Supplier<Teacher> suppl = Teacher::new;
Teacher teac = suppl.get();
System.out.println(teac.name);
// 这是实现Function函数型内置函数接口
Function<String, String> function = (x) -> {return String.valueOf(x);};
String string = function.apply("asd");
System.out.println(string);
Function<String,String> func = (x) -> x.concat("hello");
String s = func.andThen(function).apply("123");
System.out.println(s);
-
Java中数组和集合的区别:
答:
1、数组的长度不可变,集合的长度可变
2、数组既能存基本数据类型也能存引用数据类型,集合只能存储引用数据类型
3、数组只能存同一种数据类型(除非是Object []),集合可以存任意数据类型 -
get和post的区别:
答:
更详细- GET提交的数据放在URL中,POST则不会。这点意味着GET更不安全(POST也不安全,因为HTTP是明文传输抓包就能获取数据内容,要想安全还得加密)
- GET回退浏览器无害,POST会再次提交请求(GET方法回退后浏览器再缓存中拿结果,POST每次都会创建新资源)
- GET提交的数据在请求头,大小有限制(是因为浏览器对URL的长度有限制,GET本身没有限制),POST提交的数据在请求体,大小没有限制
-
java的权限修饰符的访问权限
答:public是公共的,被public所修饰的成员可以在任何类中都能被访问到。被public所修饰的成员能被所有的子类继承下来。
protected是受保护的,被protected所修饰的成员在同一个package或者不同的package中的子类都能访问。被protected所修饰的成员也能被该类的所有子类继承下来。
default是默认的,即不写任何修饰符,只有在同一个package中的子类才能访问到父类中默认修饰的成员。被default所修饰的成员只能被该类所在同一个package中的子类所继承下来。
private是私有的,只能在当前类中被访问到,它的作用域最小。
| 权限修饰符 | 当前类 | 同包 | 不同包子孙类 | 不同包类 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | |
| 默认 | √ | √ | ||
| private | √ |
49.
