mysql优化
sql优化
1,小表驱动大表,即小的数据集驱动大的数据集
# B表的数据集必须小于A表的数据集,用in 优先于 exists
select * from A where id in (select id from B);
# A表的数据集必须小于B表的数据集,用exists 优先于 in
select * from A where exists(select 1 from B where B.id = A.id)
注意: A,B表的id字段应建立索引
exists
select … from table where exists(subquery)
语法理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(true或false)来决定主查询的数据是否得意保留。
- exists(subquery) 只返回true 或 false ,因此子查询中的select 1 也可以为 select * 或 select ‘X’ , 官方说法实际执行时会忽略select 清单,因此没有区别。
- exist 子查询的实际执行过程可能经过了优化,而不是我们理解的逐条对比,如果担忧效率,可以实际情况校验
- exists 子查询往往也可以用条件表达式,其他子查询或join来替代,具体问题具体分析
order by
create table tbla(
id int primary key not null auto_increment,
age int,
birth TIMESTAMP not null
);
insert into tbla(age,birth) values(22,now());
insert into tbla(age,birth) values(23,now());
insert into tbla(age,birth) values(24,now());
insert into tbla(age,birth) values(25,now());
create index indx on tbla(age,birth);
mysql 支持两种方式的排序,filesort 和 index,index的效率高,它指mysql 扫描索引本身完成的排序。filesort 方式效率低
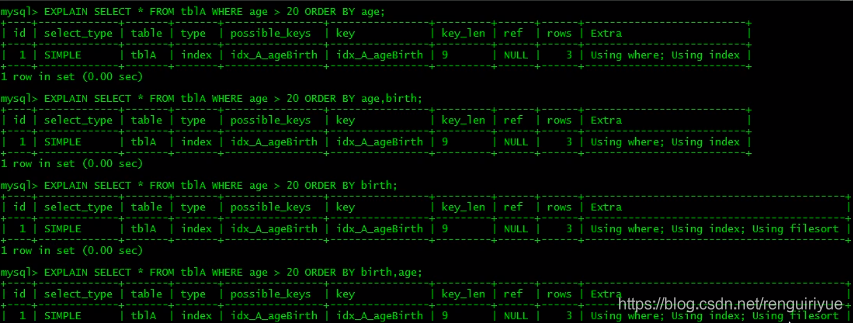
图中sql表明,orderby 后面的不按照索引顺序,会产生using filesort,除此之外,以下情况也会产生。

提高order by 的查询速度

排序的索引与查询的索引相同
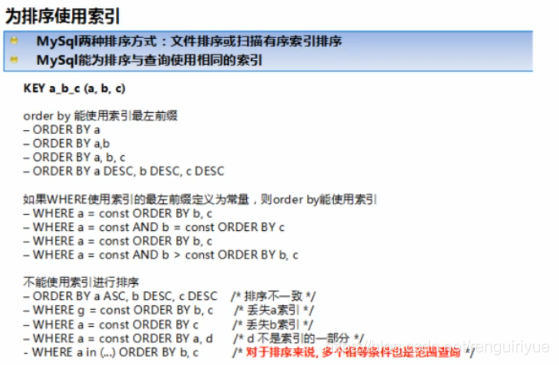
group by
与order by 相似,having 条件能放where的就放where。
慢查询日志
默认不开启,开启会影响sql性能
# 查询状态
# 查询状态
show variables like '%slow_query_log%';
# 开启(只对当前数据库生效,重启会失效)
set global slow_query_log = 1;
# 查看当前多少秒算慢
show variables like '%long_query_time%';
# 设置(需要新建连接后才能看到修改的值)
set global long_query_time = 4;
# 查看慢查询的sql数量
show global status like '%slow_quer%';
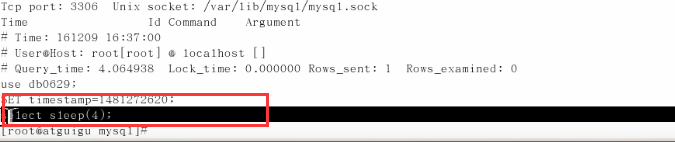
当有慢查询的sql后,可以查询到