一.XML文件简述
详细内容请参考以下几篇博主文章:
https://blog.csdn.net/weixin_40684476/article/details/83057238
https://blog.csdn.net/u012562943/article/details/50462179
https://blog.csdn.net/erlian1992/article/details/51544646
https://blog.csdn.net/erlian1992/article/details/51569678
https://blog.csdn.net/erlian1992/article/details/51570210
注:
- 在XML中,所有元素都必须有关闭标签。
- XML标签对大小写敏感,必须使用相同的大小写来编写打开标签和关闭标签。
- 在XML中,所有元素都必须彼此正确地嵌套。
- 在XML中,XML的属性值须加引号。
- XML文档必须有一个元素是所有其他元素的父元素。该元素称为根元素。
- 在XML技术中,标签属性所代表的信息,也可以被改成用子元素的形式来描述,如
<input name=“text”>
**************************
<input>
<name>text</name>
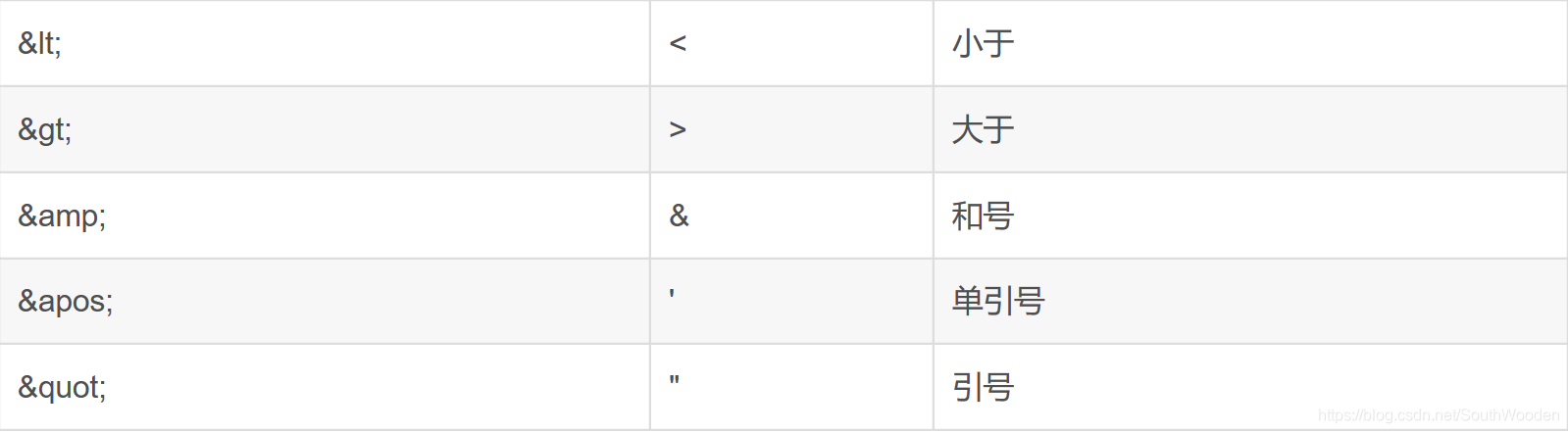
</input>7.实体引用
二.XML文件示例
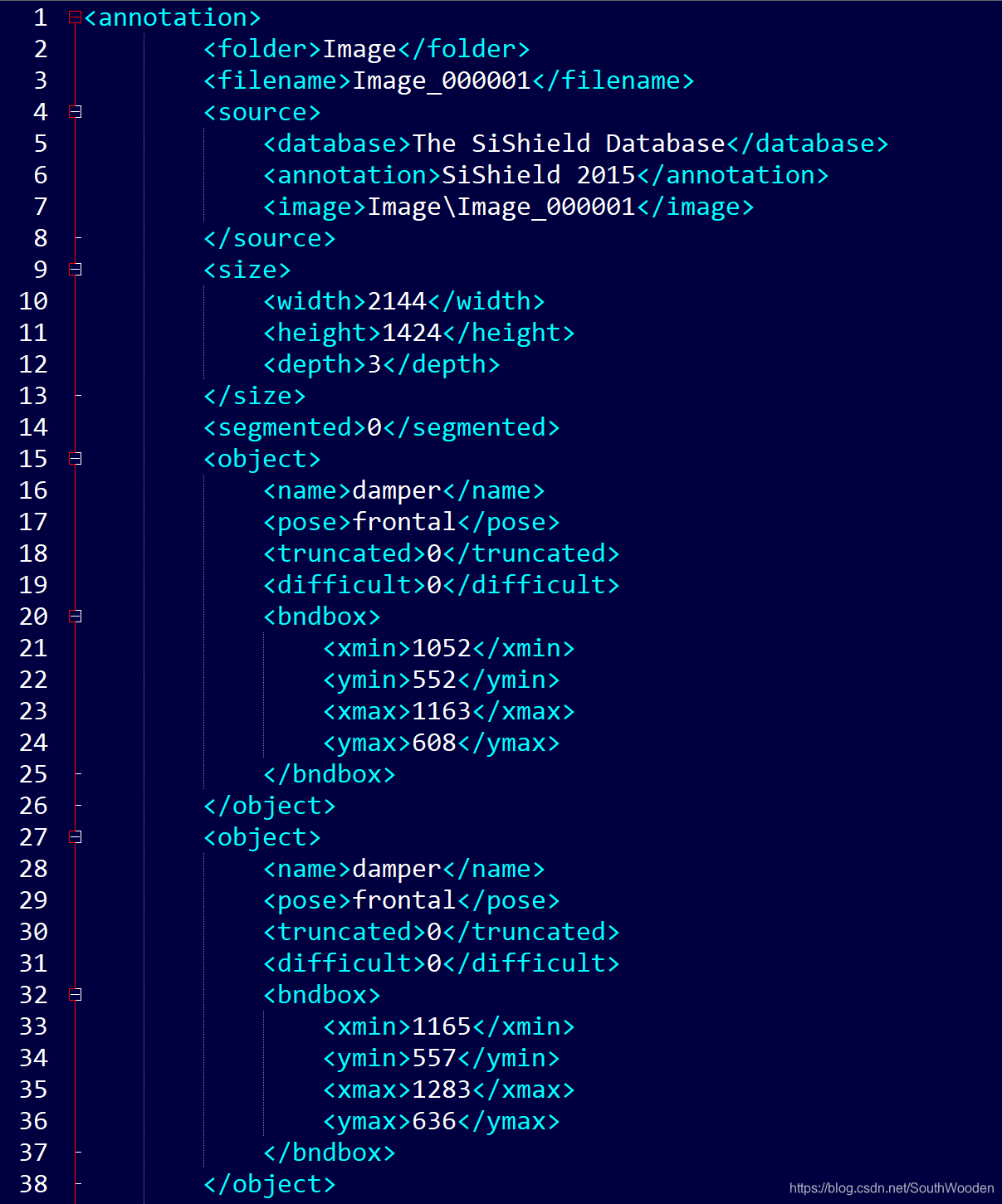
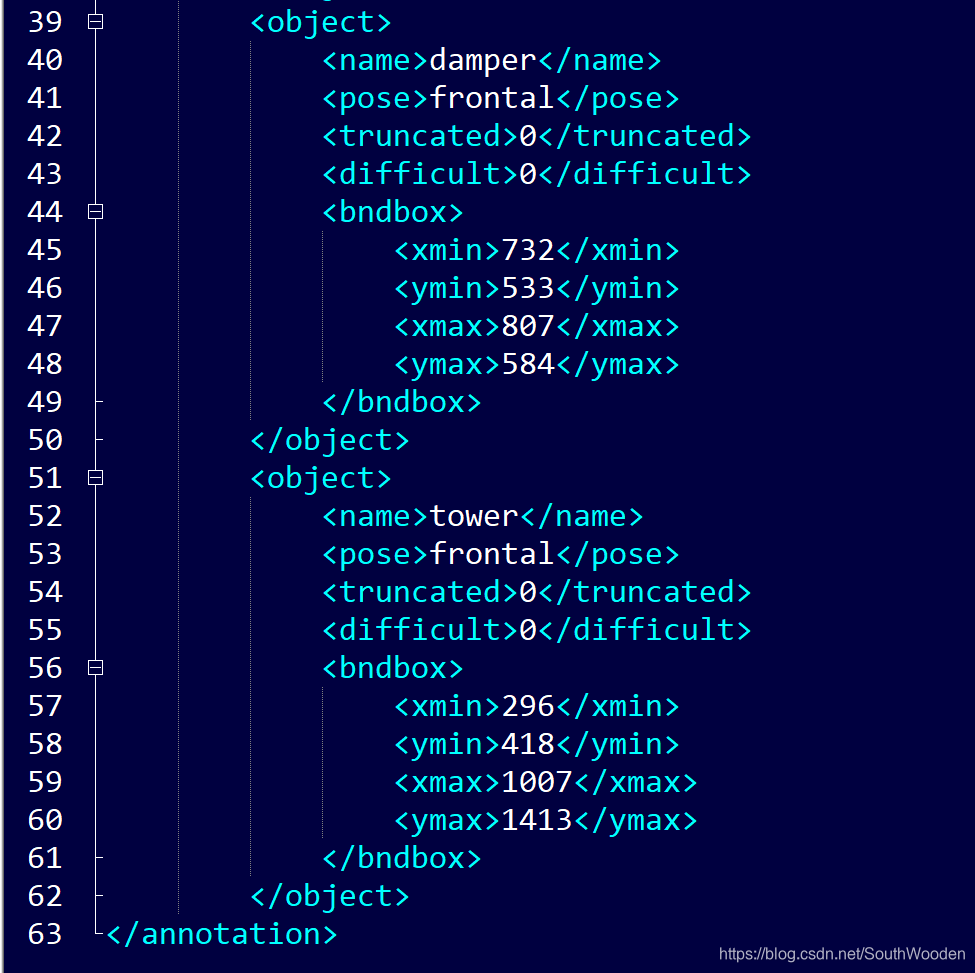
1.根元素< annotation >
2.子元素< folder >,< size >,< object >等
3.标签 带< >的都是标签
4.文本 被开始标签和结束标签包含的是文本,如damper, tower等
三.采用DOM解析XML文件
- 文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。一个 DOM 的解析器在解析一个 XML 文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。
- 实现代码(原理参考注释)
from xml.dom.minidom import parse
def readXML():
# 打开这个文档,用parse方法解析,得到domTree对象
domTree = parse("C:\\Users\\Tony.Hsu\\Desktop\\Image_000001.xml")
# 得到文档根元素
rootNode = domTree.documentElement
print("****information****")
print(rootNode.nodeName)
print(rootNode.nodeType)
folder_node = rootNode.getElementsByTagName("folder")[0]
print(folder_node.childNodes[0].data)
filename_node = rootNode.getElementsByTagName("filename")[0]
print(filename_node.childNodes[0].data)
segmented_node = rootNode.getElementsByTagName("segmented")[0]
print(segmented_node.childNodes[0].data)
# 得到根节点下面的第一个source节点
source_node = rootNode.getElementsByTagName("source")[0]
image = source_node.getElementsByTagName("image")[0] # 根据标签名找到,并且输出第一个元素
print(image.nodeName, ":", image.childNodes[0].data) # 输出标签名的子节点的第一个值,并转为data类型,读取其文本内容
database = source_node.getElementsByTagName("database")[0]
print(database.nodeName, ":", database.childNodes[0].data)
annotation = source_node.getElementsByTagName("annotation")[0]
print(annotation.nodeName, ":", annotation.childNodes[0].data)
# 得到根节点下面的第一个size节点
size_node = rootNode.getElementsByTagName("size")[0]
width = size_node.getElementsByTagName("width")[0]
print(width.nodeName, ":", width.childNodes[0].data)
height = size_node.getElementsByTagName("height")[0]
print(height.nodeName, ":", height.childNodes[0].data)
depth = size_node.getElementsByTagName("depth")[0]
print(depth.nodeName, ":", depth.childNodes[0].data)
# 按照名称查找子节点,注意这里会递归查找所有子节点
# 得到根节点下面所有的object节点
objects = rootNode.getElementsByTagName("object")
# 得到根节点下面所有的bndbox节点
# bndboxs = rootNode.getElementsByTagName("bndbox")
print("****information of objectives****")
# 遍历处理,objects是一个列表
for object in objects:
# name 元素
name = object.getElementsByTagName("name")[0]
print(name.nodeName, ":", name.childNodes[0].data)
# pose 元素
pose = object.getElementsByTagName("pose")[0]
print(pose.nodeName, ":", pose.childNodes[0].data)
# truncated 元素
truncated = object.getElementsByTagName("truncated")[0]
print(truncated.nodeName, ":", truncated.childNodes[0].data)
# difficult 元素
difficult = object.getElementsByTagName("difficult")[0]
print(difficult.nodeName, ":", difficult.childNodes[0].data)
# bndbox 元素
bndbox = object.getElementsByTagName("bndbox")[0]
# xmin 元素
xmin = bndbox.getElementsByTagName("xmin")[0]
print(xmin.nodeName, ":", xmin.childNodes[0].data)
# ymin 元素
ymin = bndbox.getElementsByTagName("ymin")[0]
print(ymin.nodeName, ":", ymin.childNodes[0].data)
# xmax 元素
xmax = bndbox.getElementsByTagName("xmax")[0]
print(xmax.nodeName, ":", xmax.childNodes[0].data)
# ymax 元素
ymax = bndbox.getElementsByTagName("ymax")[0]
print(ymax.nodeName, ":", ymax.childNodes[0].data)
print("*********************")
if __name__ == '__main__':
readXML()输出结果
****information****
annotation
1
Image
Image_000001
0
image : Image\Image_000001
database : The SiShield Database
annotation : SiShield 2015
width : 2144
height : 1424
depth : 3
****information of objectives****
name : damper
pose : frontal
truncated : 0
difficult : 0
xmin : 1052
ymin : 552
xmax : 1163
ymax : 608
*********************
name : damper
pose : frontal
truncated : 0
difficult : 0
xmin : 1165
ymin : 557
xmax : 1283
ymax : 636
*********************
name : damper
pose : frontal
truncated : 0
difficult : 0
xmin : 732
ymin : 533
xmax : 807
ymax : 584
*********************
name : tower
pose : frontal
truncated : 0
difficult : 0
xmin : 296
ymin : 418
xmax : 1007
ymax : 1413
*********************
