前言
前一篇 深度解析阻塞队列LinkedBlockingQueue 从底层源码和结构原理入手,较为深入的讲解了由单链表实现的阻塞队列LinkedBlockingQueue。本篇所要讲解的依然是阻塞队列,阻塞还是那个阻塞,队列还是那个队列。只是ArrayBlockingQueue使用数组实现的阻塞队列。
由于前一篇已经重点讲解了阻塞队列中,阻塞API的实现。所以本篇的重点放在ArrayBlockingQueue与LinkedBlockingQueue实现的不同之处。
阻塞队列
ArrayBlockingQueue是阻塞队列中的一种,见名知意,由数组实现的阻塞队列。类的继承结构图如下:
类的体系结构基本上和LinkedBlockingQueue一模一样。
内部结构
要想知道ArrayBlockingQueue的内部结构,得先了解类的定义和成员变量/常量。
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/**
* Serialization ID. This class relies on default serialization
* even for the items array, which is default-serialized, even if
* it is empty. Otherwise it could not be declared final, which is
* necessary here.
*/
private static final long serialVersionUID = -817911632652898426L;
/** The queued items */
// 存储队列元素的数组
final Object[] items;
/** items index for next take, poll, peek or remove */
// 下一次出队或者查看的元素(队首)索引
int takeIndex;
/** items index for next put, offer, or add */
// 下一次放入元素(队尾)索引
int putIndex;
/** Number of elements in the queue */
// 队列中元素个数
int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
// 可重入锁
final ReentrantLock lock;
/** Condition for waiting takes */
// 线程可以取元素
private final Condition notEmpty;
/** Condition for waiting puts */
// 线程可以放元素
private final Condition notFull;
}
从类的定义以及成员变量来看,对比LinkedBlockingQueue,至少可以看出如下区别:
ArrayBlockingQueue底层用数组实现,LinkedBlockingQueue底层用单链表实现ArrayBlockingQueue记录队列中元素个数用的类型是int,而LinkedBlockingQueue用的AtomicIntegerArrayBlockingQueue只定义了一把锁,而LinkedBlockingQueue定义了两把锁(put锁和take锁)
对于第一点,应该没什么疑问。对于第二点和第三点,先挖个坑,后文详细描述。
构造方法
ArrayBlockingQueue构造方法有三个:
public ArrayBlockingQueue(int capacity) {
// 指定容量,默认非公平锁
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
// 实例化数组
this.items = new Object[capacity];
// 实例化锁
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
this(capacity, fair);
final ReentrantLock lock = this.lock;
// 加锁
lock.lock(); // Lock only for visibility, not mutual exclusion
try {
int i = 0;
try {
// 循环赋值
for (E e : c) {
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
// 结合c的长度不能大于队列(数组)指定长度
throw new IllegalArgumentException();
}
count = i;
// 队列已满,特殊处理下一个元素入队的索引
putIndex = (i == capacity) ? 0 : i;
} finally {
// 解锁
lock.unlock();
}
}
构造方法比较简单,只需要关注一点:初始化的时候必须指定容量,这也很好理解,因为数组初始化的时候就必须指定容量。第38行的代码putIndex = (i == capacity) ? 0 : i不是很好理解,先无需关注,等看了后文关于数组实现队列的设计思想之后自然就理解了。
核心方法
队列的核心操作只有三个:入队、出队、查看队首元素。ArrayBlockingQueue的入队、出队操作对应实现了三组API。其表现行为和LinkedBlockingQueue一模一样,所以重点关注下阻塞API,put/take的实现即可。
put(E e)方法
put(E e)方法是往队列尾部插入元素(入队)。当队列满了的时候,put方法会阻塞当前线程,直到有线程从队列中取出元素,队列还有剩余空间的时候才会继续进行入队操作。put方法的源代码如下:
public void put(E e) throws InterruptedException {
// 不能放入空元素,会抛出NullPointerException
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 加锁(可响应中断)
lock.lockInterruptibly();
try {
while (count == items.length)
// 队列已满,阻塞当前线程
notFull.await();
// 队列未满,入队
enqueue(e);
} finally {
// 解锁
lock.unlock();
}
}
整体逻辑比LinkedBlockingQueue稍微简单一些,基本上分四步:加锁->队列已满,阻塞 / 队列未满,入队->解锁。再来看看入队实现逻辑enqueue
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
// 获取队列底层数组
final Object[] items = this.items;
// 入队
items[putIndex] = x;
if (++putIndex == items.length)
// 当前入队的元素恰好是数组的最后一个元素
// 下一个入队元素的索引就是0
putIndex = 0;
count++;
// 唤醒因为调用take方法而被阻塞的线程(唤醒线程来取元素)
notEmpty.signal();
}
第8行代码++putIndex == items.length又出现了和构造方法一样的特殊处理。实际上这正是ArrayBlockingQueue设计的巧妙之处。接下来用图解的方式来讲解一下:
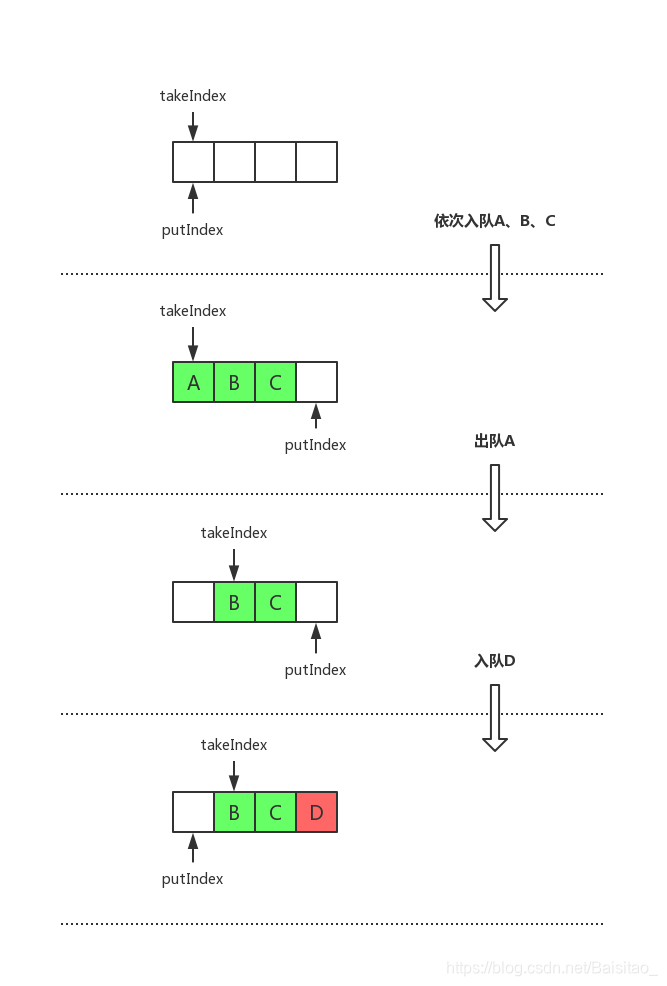
如图所示,假设队列长度为4,依次入队A、B、C,再出队A,再入队D,此时就会满足判断++putIndex == items.length(注意判断的时候,putIndex是指向元素D的),此时就需要把putIndex移到数组第一个位置,如果不移动,再往队列中添加元素,数组下标就越界了,而此时队列中本来还可以存放一个元素。极端情况下,BCD依次出队后,队列已经为空了,依然无法往队列中添加元素。
想要解决这个问题,还有一种办法就是,每次出队一个元素后,就把数组中所有元素往左移动一格。这样的话,每次出队操作都需要移动整个数组,时间复杂度为O(n)。但是如果采用上面这种方式,出队操作时间复杂度变成了O(1)。这其实就是用数组实现的循环队列。
数组实现循环队列的代码,博主之前实现过,源文件:ArrayCycleQueue.java
E take()方法
E take()方法执行的逻辑是删除并返回队列头部元素(出队)。当队列为空的时候,take方法会阻塞当前线程,直到有线程往队列中放入元素,才会继续进行出队操作。take方法的源代码如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 加锁(可响应中断)
lock.lockInterruptibly();
try {
while (count == 0)
// 队列为空,阻塞当前线程
notEmpty.await();
// 队列不为空,出队
return dequeue();
} finally {
// 解锁
lock.unlock();
}
}
再来看看入队实现逻辑dequeue
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
// 获取存储元素的数组
final Object[] items = this.items;
@SuppressWarnings("unchecked")
// 获取要出队的元素,用于返回
E x = (E) items[takeIndex];
// 出队
items[takeIndex] = null;
if (++takeIndex == items.length)
// 此处原理同enqueue方法
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
// 唤醒因为调用put方法而被阻塞的线程(唤醒线程来放入元素)
notFull.signal();
// 返回出队的元素
return x;
}
dequeue和enqueue方法一样,满足++index == items.length时,都会特殊处理index,并且都是把索引从数组尾部移到数组头部。
peek()方法
除了入队和出队,队列还有一个基本操作就是查看队首元素(和出队操作的区别是:是否删除队首元素),方法名是peek,源代码如下:
public E peek() {
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 返回队首元素(并不是索引为0的元素)
// 队列为空时,返回null
return itemAt(takeIndex); // null when queue is empty
} finally {
// 解锁
lock.unlock();
}
}
// 实际执行的方法
final E itemAt(int i) {
return (E) items[i];
}
基本是只是一个读操作,但是也加锁了。是为了防止在读的过程中,有线程执行了出队操作。
填坑
前文挖了两个坑:
ArrayBlockingQueue记录队列中元素个数用的类型是int,而LinkedBlockingQueue用的AtomicIntegerArrayBlockingQueue只定义了一把锁,而LinkedBlockingQueue定义了两把锁(put锁和take锁)
先看第二个,LinkedBlockingQueue底层结构是带有头指针和尾指针的单链表,两把锁其实分别锁的就是头指针和尾指针,对应dequeue和enqueue方法。入队方法和出队方法分别加锁,使入队和出队互不影响,提高了队列的并发度,而ArrayBlockingQueue底层是数组,入队和出队都是操作同一个数组,所以只需要一把锁
再看第一个问题其实也有解释了,LinkedBlockingQueue入队和出队同时进行,分别是不同的锁,想要保证记录的节点数量是正确的,就不能简单的用int;而ArrayBlockingQueue不管是出队还是入队,同时最多只有一个线程在操作,所以用int足矣。
总结
ArrayBlockingQueue和LinkedBlockingQueue相同点:
- 都是阻塞队列,对外提供的功能相同
- 都是利用
ReentrantLock+Condition实现队列的线程安全,以及线程的阻塞和唤醒 - 入队、出队、查看队首元素等操作时间复杂度都是O(1),非常高效
ArrayBlockingQueue和LinkedBlockingQueue不同点:
- 数据结构:
ArrayBlockingQueue底层由数组实现;LinkedBlockingQueue底层由单链表实现 - 锁:
ArrayBlockingQueue只用了一把锁,不能同时入队、出队;LinkedBlockingQueue用了两把锁,可以同时入队、出队 - 初始化:
ArrayBlockingQueue初始化时必须指定大小;LinkedBlockingQueue初始时可以不用指定大小(默认Integer.MAX_VALUE) - GC:
ArrayBlockingQueue底层由数组实现,增加和删除元素时不需要创建或者销毁额外的对象;LinkedBlockingQueue底层由单链表实现,增加和删除元素需要创建和销毁额外的Node对象,会对GC有一定的影响
明白了两者的异同,那实际工作中应该如何取舍呢?
如何取舍应该从两者的差异入手
- 因为
LinkedBlockingQueue支持同时入队、出队,理论上来说并发度会更高一些。 - 队列中元素个数比较稳定的情况下可以优先考虑
ArrayBlockingQueue,因为单链表除了会存储元素数据域,还需要额外的空间来存储指针域,所以数组更省空间。 - 队列中元素个数不稳定的情况下优先考虑
LinkedBlockingQueue,因为此时ArrayBlockingQueue可能存在大量的空闲空间 - 如果队列中元素个数较多优先考虑
LinkedBlockingQueue,因为不需要大量连续的内存。
