HTTP协议简述
- HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写.它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果.最终发布了一系列的RFC,RFC1945定义了HTTP/1.0版本,其中最著名的就是RFC2616,RFC2616定义了今天普遍使用的一个版本–HTTP 1.1.
- HTTP协议是用于www服务器传输超文本到本地浏览器的传送协议.它可以使浏览器更加高效,使网络传输减少,不仅保证计算机正确快速地传输超文本内容,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等.
- HTTP是一个面向事务的应用层协议,由请求和相应构成,是一个标准的客户端服务器模型.
- HTTP是一个无状态的协议.
HTTP协议的主要特点
1.支持面向事务的客户端/服务器模式.
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径.请求方法常用的有GET、HEAD、POST.每种方法规定了客户与服务器联系的类型不同.由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快.
3.灵活:HTTP允许传输任意类型的数据对象,正在传输的类型由Content-Type加以标记.
4.无连接:无连接的含义是限制每次连接只处理一个请求.服务器处理完客户的请求,并受到客户的应答后,即断开连接.采用这种方式可以节省传输时间.
5.无状态:HTTP协议是无状态协议.无状态是指协议对于事务处理没有记忆能力.缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大.另一方面,在服务器不需要先前信息时它的应答就较快.
请求一个万维网文档需要的时间

HTTP/1.1协议使用持续连接(persistent connection)
万维网服务器在发送响应后仍然在一段时间内保持这条连接,使同一个客户(浏览器)和该服务器可以继续在这条连接上传送后续的 HTTP 请求报文和响应报文.
这并不局限于传送同一个页面上链接的文档,而是只要这些文档都在同一个服务器上就行.
目前一些流行的浏览器(例如,IE 6.0)的默认设置就是使用 HTTP/1.1.
非流水线方式:客户在收到前一个响应后才能发出下一个请求.这比非持续连接的两倍 RTT 的开销节省了建立 TCP 连接所需的一个 RTT 时间.但服务器在发送完一个对象后,其 TCP 连接就处于空闲状态,浪费了服务器资源.
流水线方式:客户在收到 HTTP 的响应报文之前就能够接着发送新的请求报文.一个接一个的请求报文到达服务器后,服务器就可连续发回响应报文.使用流水线方式时,客户访问所有的对象只需花费一个 RTT时间,使 TCP 连接中的空闲时间减少,提高了下载文档效率.
代理服务器
代理服务器(proxy server)又称为万维网高速缓存(Web cache),它代表浏览器发出HTTP请求.
万维网高速缓存把最近的一些请求和相应暂存在本地磁盘中.
当与暂时存放的请求相同的新请求到达时,万维网高速缓存就把暂存的响应发送出去,而不需要按 URL 的地址再去互联网访问该资源.
使用高速缓存可减少访问互联网服务器的时延
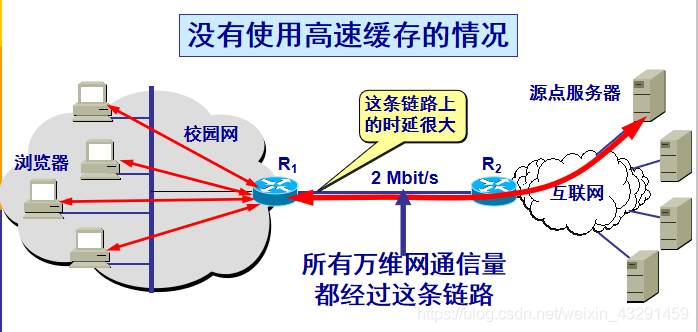
使用高速缓存的情况
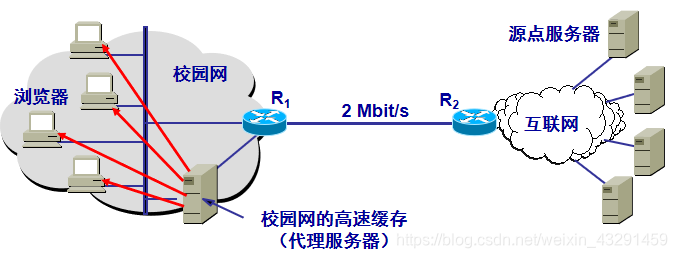
1.浏览器访问互联网的服务器时,要先与校园网的高速缓存建立TCP连接,并向高速缓存发出HTTP请求报文.
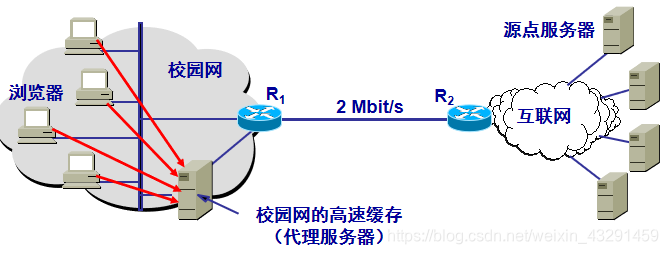
2.若高速缓存已经存放了所请求的对象,则将此对象放入HTTP响应报文中返回给浏览器.
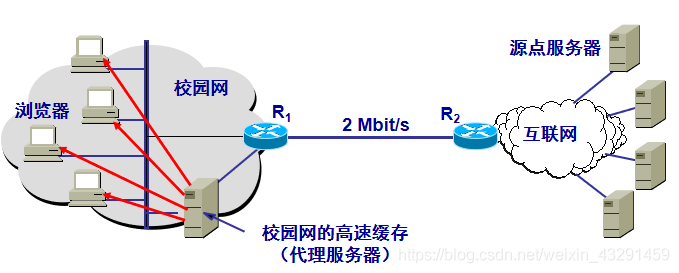
3.否则,高速缓存就代表发出请求的用户浏览器,与互联网上的源点服务器建立TCP连接,并发送HTTP请求报文.
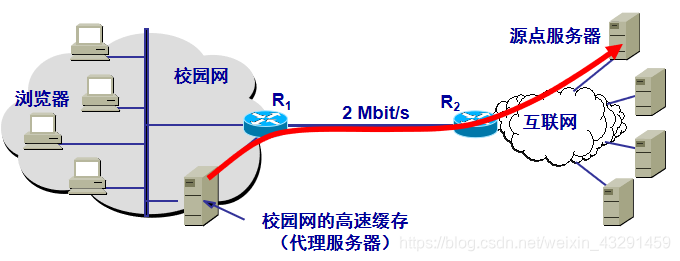
4.源点服务器将所请求的对象放在HTTP响应报文中返回给校园网的高速缓存.
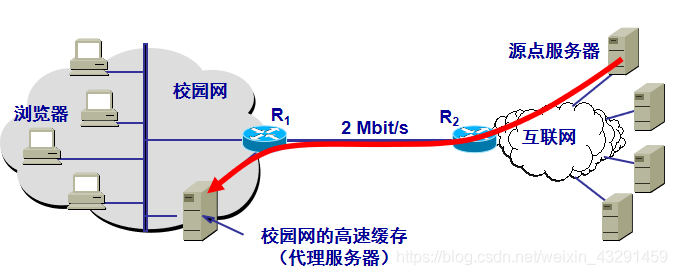
5.高速缓存收到此对象后,先复制在其本地存储器中(为今后使用),然后再将该对象放在HTTP响应报文中,通过已建立的TCP连接,返回给请求该对象的浏览器.
HTTP的报文结构
HTTP是面向文本的,报文中的没一个字段都是一些ASCII码,各字段的长度是不确定的.
HTTP有两类报文:请求报文和响应报文.
HTTP请求报文
请求报文由三个部分组成:开始行,首部行,实体主体.
在请求报文总,开始行就是请求行.
(1)请求行:请求行由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔.例如,GET /index.html HTTP/1.1.
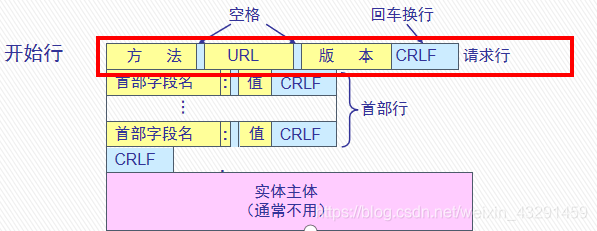
请求方法是对所请求的对象进行的操作,实际上也就是一些命令,包括GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT.最常用的有GET和POST方法.
GET:当客户端要从服务器中读取文档时,使用GET方法.GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端.使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制.例如:/index.jsp?id=100&op=bind.
POST:当客户端给服务器提供信息较多时可以使用POST方法.POST方法,将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据.
HTTP请求报文的一些方法
| 方法(操作) | 意义 |
|---|---|
| OPTION | 请求一些选项的信息 |
| GET | 请求读取由 URL所标志的信息 |
| HEAD | 请求读取由 URL所标志的信息的首部 |
| POST | 给服务器添加信息(例如,注释) |
| PUT | 在指明的 URL下存储一个文档 |
| DELETE | 删除指明的 URL所标志的资源 |
| TRACE | 用来进行环回测试的请求报文 |
| CONNECT | 用于代理服务器 |
URL:所请求资源的URL
版本:HTTP的版本

(2)请求首部:请求首部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔.请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
User-Agent:产生请求的浏览器类型.
Accept:客户端可识别的内容类型列表.
Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机.

(3)空行:最后一个请求首部行之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求首部。.
(4)实体主体:实体主体不在GET方法中使用,而是在POST方法中使用.POST方法适用于需要客户填写表单的场合.与请求数据相关的最常使用的请求头是Content-Type和Content-Length.

HTTP响应报文
响应报文由三个部分组成:状态行,消息首部,响应正文.
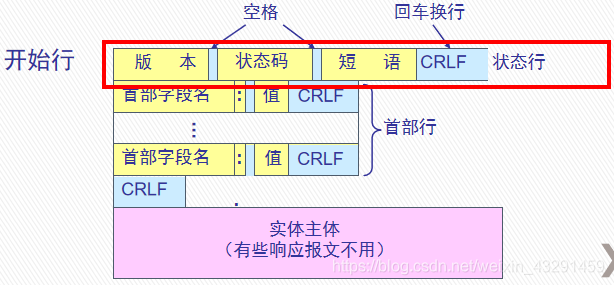
状态行:包括三项内容,即 HTTP 的版本,状态码,以及解释状态码的简单短语.
HTTP-Version表示服务器HTTP协议的版本;
Status-Code表示服务器发回的响应状态代码;
Reason-Phrase表示状态代码的文本描述.
状态码由三位数组成,第一个数字定义了响应的类别,且有五种可能取值.
1xx:指示信息–表示请求已接收,继续处理.
2xx:成功–表示请求已被成功接收、理解、接受.
3xx:重定向–要完成请求必须进行更进一步的操作.
4xx:客户端错误–请求有语法错误或请求无法实现.
5xx:服务器端错误–服务器未能实现合法的请求.

常见状态代码、状态描述的说明如下.
200 OK:客户端请求成功.
400 Bad Request:客户端请求有语法错误,不能被服务器所理解.
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用.
403 Forbidden:服务器收到请求,但是拒绝提供服务.
404 Not Found:请求资源不存在,举个例子:输入了错误的URL.
500 Internal Server Error:服务器发生不可预期的错误.
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常.
⏩⏭⏯ 在服务器上存放用户的信息 ◀⏪⏮
<font color=’'FF0000>万维网站使用Cookie来跟踪用户.
Cookie表示在HTTP服务器和客户之间传递的状态信息.
使用 Cookie 的网站服务器为用户产生一个唯一的识别码.利用此识别码,网站就能够跟踪该用户在该网站的活动.
HTTP报文分析
浏览web页面经过如下三个过程:
DNS解析:得到主机的IP地址.
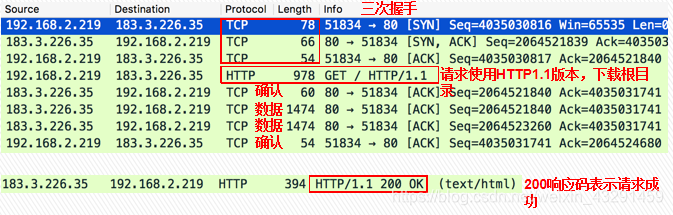
TCP三次握手连接建立,Web浏览器与Web服务器建立一个TCP连接.
HTTP交互: 使用已建立好的TCP连接来发送请求“GET/HTTP/1.1”.该请求报文用命令“GET”,及文件(只写“/”是因为没有指定额外的文件名),还有协议的版本(“HTTP/1.1”).
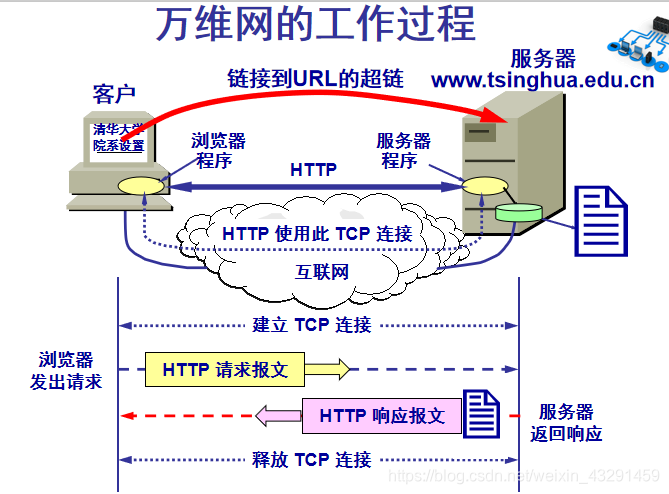
**用户点击 URL http://www.tsinghua.edu.cn/chn/yxsz/index.htm 后所发生的事件 **
(1) 浏览器分析超链指向页面的 URL.
(2) 浏览器向 DNS 请求解析 www.tsinghua.edu.cn 的 IP 地址.
(3) 域名系统 DNS 解析出清华大学服务器的 IP 地址.
(4) 浏览器与服务器建立 TCP 连接.
(5) 浏览器发出取文件命令:GET /chn/yxsz/index.htm.
(6) 服务器给出响应,把文件 index.htm 发给浏览器.
(7) TCP 连接释放.
(8) 浏览器显示“清华大学院系设置”文件 index.htm 中的所有文本.
HTTP报文
HTTP请求报文
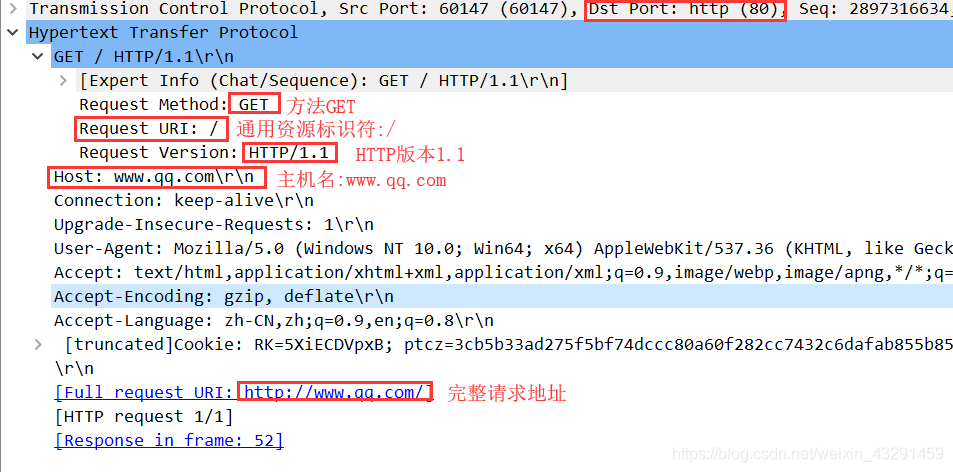
代码分析:
GET / HTTP/1.1\r\n 请求行 //请求目标
Host: www.qq.com 首部行 //目标所在的主机
URI: //资源定位符
Version:HTTP/1.1 //版本号
Connection: keep-alive //保持连接
Accept:text/html
User-Agent: Mozilla/5.0 (Windows NT) //用户代理浏览器类型
Accept-Encoding: gzip,deflate //可接受编码,文件格式
Accept-Language: zh-CN //语言中文
HTTP响应报文

由状态栏的200代码可知,www.qq.com,IP地址183.3.226.35成功接收到本地发送的请求报文,向IP地址为192.168.2.219的本地发送响应报文,把文件发送给浏览器.
代码分析:
HTTP/1.1 200 OK //状态行,成功
Date:Sat, 16 Nov 2019 11:13:32 GMT //响应信息创建的时间
Content-Type:image/gif //内容类型:图像
Connection: keep-alive //保持连接
Expires:Web,31 Oct 2018 13:34:48 //超时时间
Cache-Control: max-age=0
Content-Encoding: gzip //内容编码
Server: squid/3.5.24 //服务器
Line-based text data: text/html //对所传文本信息(基于html)的描述
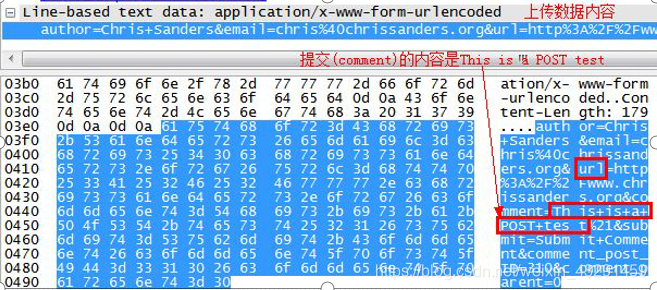
使用HTTP上传数据
用户向网站发表评论:
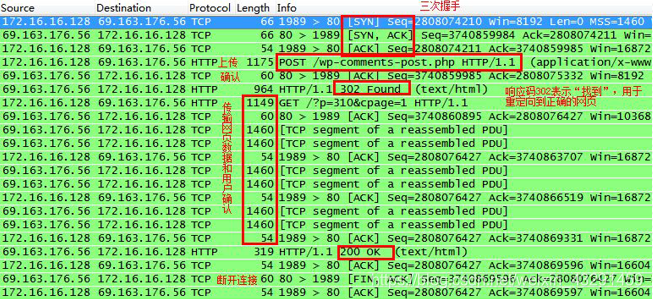
HTTP POST命令
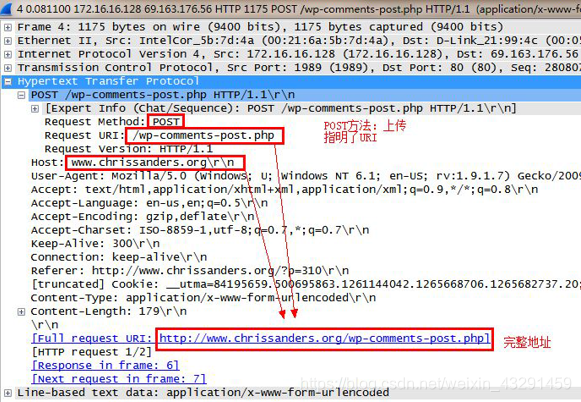
POST内容