本教程仅供学习,不会提供任何可直接使用的模型和程序
使用深度学习框架Keras
python版本3.6
验证码主要是用于智能区分人机。而爬虫一部分得工作就是模拟人得行为去浏览。
自然就站在了对立面
今天带大家练习得是还在广泛使用的,定长型字符验证码
这个是支付宝得官网的登录验证码
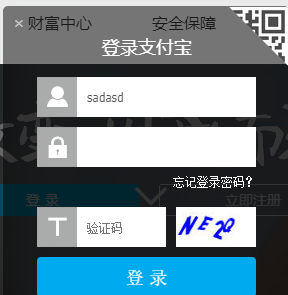
而我们需要做的就是

自动化的识别验证码内容
既然使用到了深度学习,就需要先准备训练集
因为我这边已经有一个模型了,所以准备训练集的过程会简单很多,(但是大多数情况需要手动标注而且量需要数千上W才会有较好的效果或)

链接:https://pan.baidu.com/s/1Czw6sMjr3a7zqrrvvQ5JAg
提取码:27ks
站内下载地址
下载验证码的爬虫python代码,可以参考
'''
支付宝验证码下载程序
'''
import requests
import time
import uuid
savePath = 'E:/captcha/alipay/'
for i in range(1, 5000):
print(i)
t = time.time()
url = 'https://authem14.alipay.com/login/imgcode.htm?sessionID=2296f49bfd4f29b1da26053b0eedfcb3&t=' + str(t)
session = requests.Session()
session.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/531.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Connection": "keep-alive"
}
response = session.get(url)
imgName = str(uuid.uuid1()) + '.jpg'
with open(savePath + imgName, "wb") as f:
f.write(response.content)
开始训练
修改配置
首先是准备代码
代码的话是我之前准备的一个小工程
https://github.com/cycz/EasyCaptcha
有用的话帮忙star一下

找到这一个代码ImmutableCaptcha.py(这个是训练代码)
准备好python环境(包括tensorflow2.0以下,keras)
修改代码中几个配置就可以进行训练

修改验证码可能出现字符

验证码文件夹路径
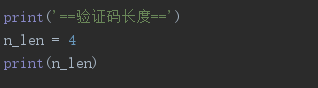
验证码长度
这里验证码是四位的就填写4

模型名称和保存路径
这里我测试的验证码大概只有5000张
所以15轮就足以
如果成功率一直上不去
可以将轮次调大到几十上百轮
运行代码

看到这个就是已经成功的开始训练
给讲讲如何看这个输出
- Epoch 1/15
这个是总轮次 以及目前多少轮
- 256/5012
这个是一共多少样本和每批次训练多少,这里设定的是256(这个设大设小对模型学习也有一定影响)
- loss: 19.5090 - c1_loss: 5.3098 - c2_loss: 4.4721 - c3_loss: 4.7025 - c4_loss: 5.0247
这一块有4个loss,每个loss都是损失值(这个数值越小越好,深度学习训练的过程,就是为了将损失值接近0)
- c1_acc: 0.0195 - c2_acc: 0.0352 - c3_acc: 0.0156 - c4_acc: 0.0547
四个acc 就是分别是4位验证码的训练集识别成功率

经过15轮的训练,训练集成功率已经非常高了。
因为这里没有设置验证集,所以不代表模型的效果也会非常好
样本比较多的可以适当调整一下,分出一部分做验证集,防止模型过拟合
更多深度学习的知识样本调参,还是非常丰富的,大家可以自己了解
使用模型示例
找到这一个代码ImmutableCaptcha_loadModel.py(这个是训练代码)
这个是调用模型的一个样例
修改配置
![[(img-bBTSLeuy-1580725737326)(./images/1580725390930.png)]](https://img-blog.csdnimg.cn/20200203183927443.png)

均要和训练时保持一致

读取模型路径
使用程序运行

输入图片的路径、即可输出识别的内容
可见训练集内容还是比较准确
训练集外的还是差了一点点
推测是训练集少了一些的原因

弄成这样的接口供其他程序调用呢
这就需要其他web框架的配合
点个赞 下回分析
