文章目录
一、线程和进程之间的对比
1.代码解析
import os
import time
#创建子线程
pid = os.fork()
print('Hello World')
#判断是子线程
if pid == 0:
print('s_fork:{},f_fork:{}'.format(os.getpid(),os.getppid()))
else:
print('f_fork:{}'.format(os.getpid()))
进一步解释:
主进程os.fork()创建一个子进程,此时先执行主进程,pid不为0,执行else后的语句;
再执行创建的子进程,pid返回值为0,所以执行if后的语句。
关于os.fork()的详细解释:
os.fork()函数是用来新建进程。但它只在POSIX系统上可用,在windows版的Python中,os模块没有定义os.fork()函数。
os.fork()函数创建进程的过程是这样的:
程序每次执行时,操作系统都会创建一个新进程来运行程序指令。进程还可调用os.fork(),要求操作系统新建一个进程。父进程是调用os.fork()函数的进程,父进程所创建的进程叫子进程。每个进程都有一个不重复的进程ID号称为pid,它对进程进行标识。子进程与父进程完全相同,子进程从父进程继承了多个值的拷贝,如全局变量和环境变量。两个进程的唯一区别是fork的返回值。子进程接收返回值0,而父进程接收子进程的pid作为返回值。一个现有进程可以调用fork()函数创建一个新进程,由fork创建的新进程被称为子进程(child process)。fork()函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。对于程序,只要判断fork的返回值,就知道自己是处于父进程还是子进程中。
更进一步的解释可参考https://www.jianshu.com/p/e8f5b828cce0。
2.线程、进程对比
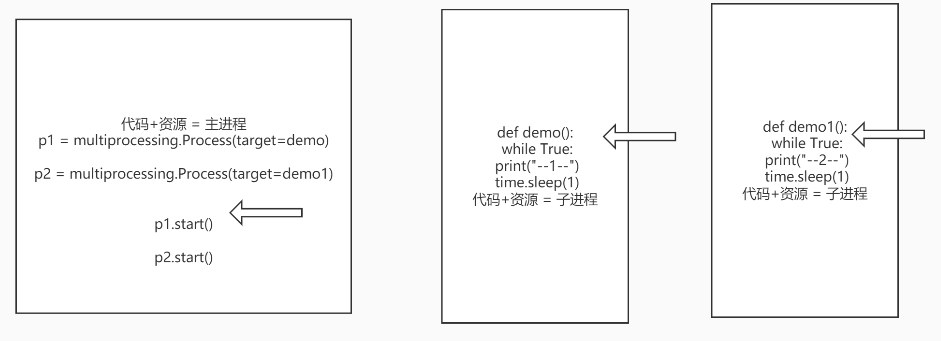
- 进程:
当执行p.start()时,主进程复制一份代码到子进程,执行多任务;
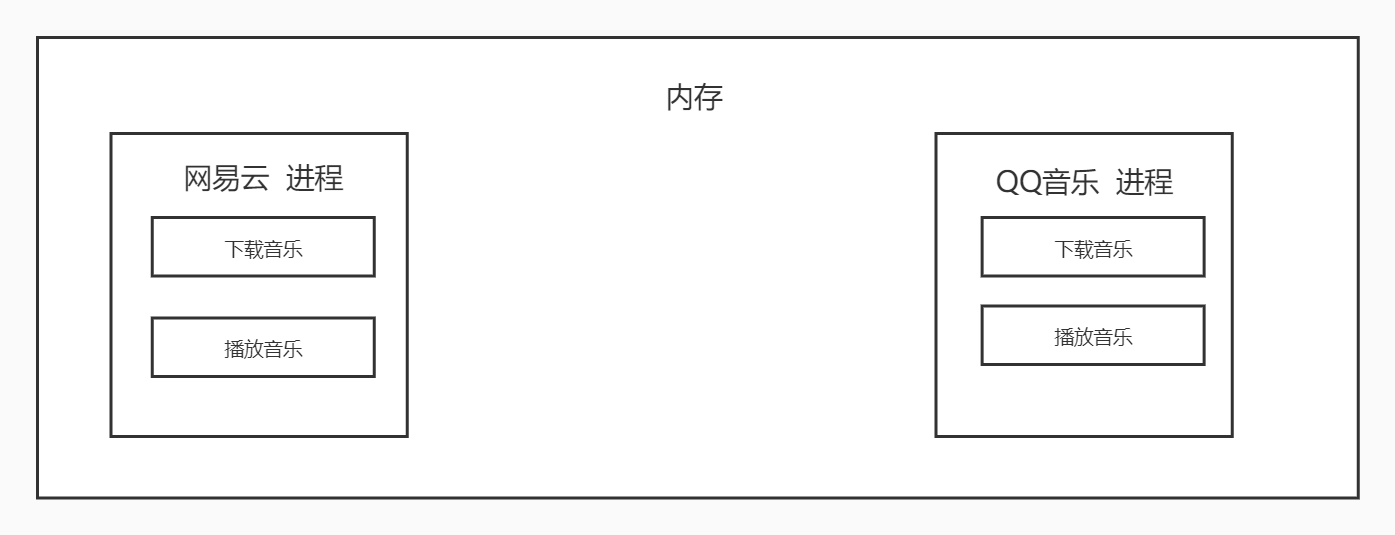
能够完成多任务,例如一台电脑上可以同时运行多个QQ。
补充:
不一定是多少个子进程就复制多少份代码,如果各个进程之间不修改公有变量,则可以共享一份代码,涉及到写时拷贝。
- 线程:
当执行t.start()时,多个子线程共同执行一份代码;
能够完成多任务,例如一个QQ中的多个聊天窗口。
根本区别:
进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位。
进程之间切换开销很大,线程之间切换开销很小。
线程可以看作一个轻量级的进程,同一类线程共享代码和数据空间。
二、进程间通信-Queue
进程间不能直接通信,要想实现两个进程间的通信,可以增加一个中间变量,如通过文件,一个进程写,另一个读,但是这种方式效率很低,一般通过队列Queue进行。
队列的特点是先进先出。
from multiprocessing import Queue
# 创建队列,最多存放3条数据
q = Queue(3)
# 存数据
q.put(1)
q.put('Corley')
q.put([11,22])
print('finished')
打印
finished
再尝试
from multiprocessing import Queue
# 创建队列,最多存放3条数据
q = Queue(3)
# 存数据
q.put(1)
q.put('Corley')
q.put([11,22])
q.put({'name':'Corley'})
print('finished')
显示
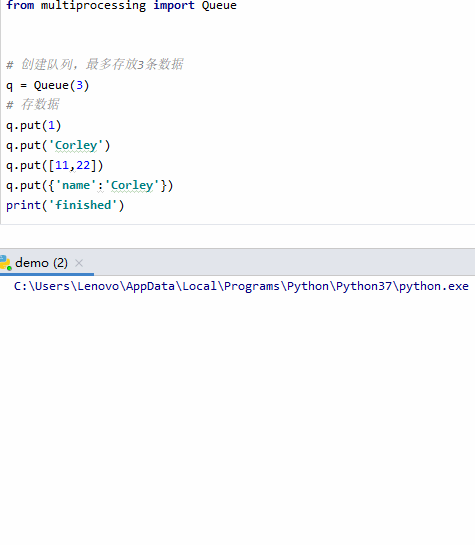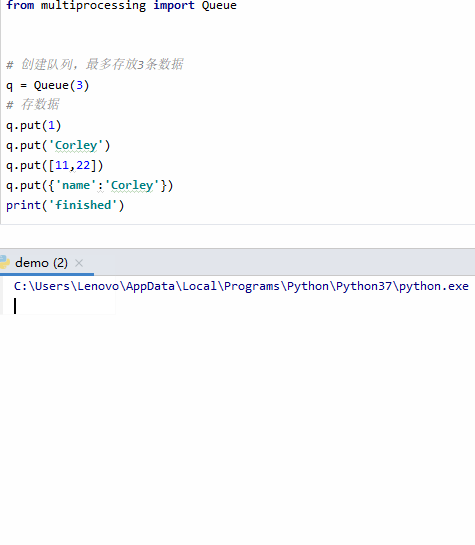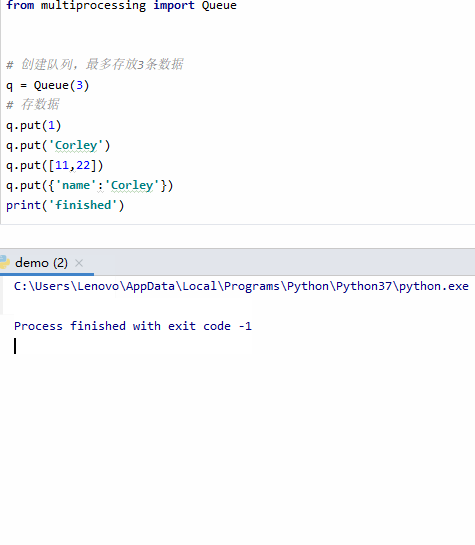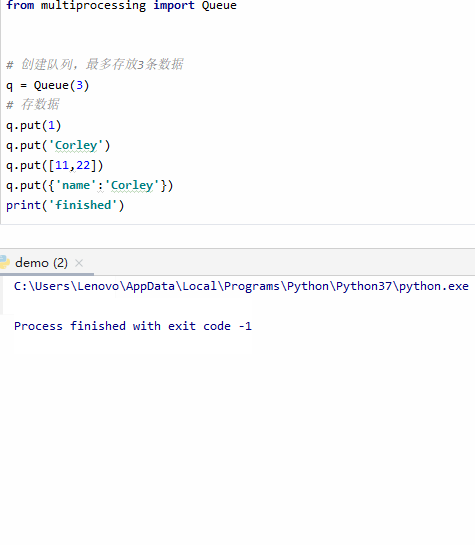
显然,当超过3条数据时会发生堵塞,只能强制停止。
改进代码:
from multiprocessing import Queue
# 创建队列,最多存放3条数据
q = Queue(3)
# 存数据
q.put(1)
q.put('Corley')
q.put([11,22])
# 直接抛出异常
q.put_nowait({'name':'Corley'})
print('finished')
打印
Traceback (most recent call last):
File "xxx/demo.py", line 11, in <module>
q.put_nowait({'name':'Corley'})
File "xxxx\Python\Python37\lib\multiprocessing\queues.py", line 129, in put_nowait
return self.put(obj, False)
File "xxxx\Python\Python37\lib\multiprocessing\queues.py", line 83, in put
raise Full
queue.Full
显示队列已满,不能再添加元素。
取数据:
from multiprocessing import Queue
# 创建队列,最多存放3条数据
q = Queue(3)
# 存数据
q.put(1)
q.put('Corley')
q.put([11,22])
print(q.get())
print(q.get())
print(q.get())
print('finished')
打印
1
Corley
[11, 22]
finished
按照先进先出的顺序取数据。
再尝试:
from multiprocessing import Queue
# 创建队列,最多存放3条数据
q = Queue(3)
# 存数据
q.put(1)
q.put('Corley')
q.put([11,22])
print(q.get())
print(q.get())
print(q.get())
# 堵塞
print(q.get())
print('finished')
显示:

显然,数据取完后再取也会发生堵塞。
改进代码:
from multiprocessing import Queue
# 创建队列,最多存放3条数据
q = Queue(3)
# 存数据
q.put(1)
q.put('Corley')
q.put([11,22])
print(q.get())
print(q.get())
print(q.get())
# 堵塞,直接抛出异常
print(q.get_nowait())
print('finished')
打印
Traceback (most recent call last):
1
Corley
[11, 22]
File "xxx/demo.py", line 14, in <module>
print(q.get_nowait())
File "xxxx\Python\Python37\lib\multiprocessing\queues.py", line 126, in get_nowait
return self.get(False)
File "xxxx\Python\Python37\lib\multiprocessing\queues.py", line 107, in get
raise Empty
_queue.Empty
显示队列为空。
其他方法使用:
from multiprocessing import Queue
# 创建队列,最多存放3条数据
q = Queue(3)
# 存数据
q.put(1)
q.put('Corley')
# 判断队列是否为满
print(q.full())
q.put([11,22])
print(q.qsize())
print(q.get())
print(q.get())
print(q.get())
print(q.empty())
print('finished')
打印
False
3
1
Corley
[11, 22]
True
finished
队列在进程通信方面的实现原理如下:
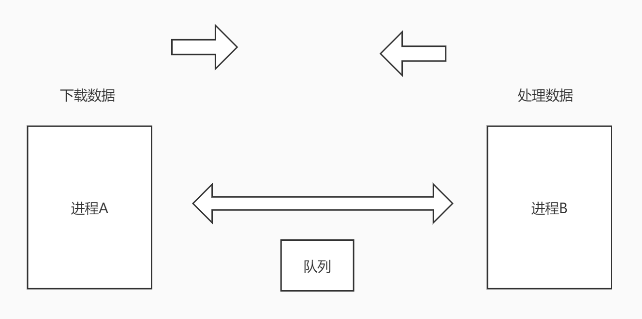
下载和处理数据实现了分离,在一定程度上实现了解耦。
队列用于进程通信尝试:
import multiprocessing
def download(q):
'''下载数据'''
lis = [11, 22, 33]
for item in lis:
q.put(item)
print('Download complete and save to queue')
def analyse(q):
'''分析数据'''
analyse_data = list()
while True:
data = q.get()
analyse_data.append(data)
if q.empty():
break
print(analyse_data)
def main():
# 创建队列
q = multiprocessing.Queue()
p1 = multiprocessing.Process(target=download, args=(q,))
p2 = multiprocessing.Process(target=analyse, args=(q,))
p1.start()
p2.start()
if __name__ == '__main__':
main()
打印
Download complete and save to queue
[11, 22, 33]
三、多进程共享全局变量
进程之间共享变量尝试:
import multiprocessing
a = 1
def demo1():
global a
a += 1
def demo2():
# 打印出的值为2,则是共享的
print(a)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=demo1)
p2 = multiprocessing.Process(target=demo2)
p1.start()
p2.start()
打印
1
打印出的结果为1,说明进程之间全局变量是不共享的,与线程不同。
用普通队列尝试:
import multiprocessing
from queue import Queue
def demo1(q):
q.put('a')
def demo2(q):
data = q.get()
print(data)
if __name__ == '__main__':
q = Queue()
p1 = multiprocessing.Process(target=demo1, args=(q,))
p2 = multiprocessing.Process(target=demo2, args=(q,))
p1.start()
p2.start()
打印
Traceback (most recent call last):
File "xxx/demo.py", line 93, in <module>
p1.start()
File "xxxx\Python\Python37\lib\multiprocessing\process.py", line 112, in start
self._popen = self._Popen(self)
File "xxxx\Python\Python37\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "xxxx\Python\Python37\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "xxxx\Python\Python37\lib\multiprocessing\popen_spawn_win32.py", line 89, in __init__
reduction.dump(process_obj, to_child)
File "xxxx\Python\Python37\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
TypeError: can't pickle _thread.lock objects
报错,属于类型错误。
改进–线程调用run()方法即可达到效果:
import multiprocessing
from queue import Queue
def demo1(q):
q.put('a')
def demo2(q):
data = q.get()
print(data)
if __name__ == '__main__':
q = Queue()
p1 = multiprocessing.Process(target=demo1, args=(q,))
p2 = multiprocessing.Process(target=demo2, args=(q,))
p1.run()
p2.run()
打印
a
此时正常运行得到结果,但是已经不属于多进程了,因为调用的不是run()方法,所以普通队列不能实现真正的线程间通信,要实现跨线程通信,需要使用multiprocessing.Queue。
缺失参数异常处理尝试:
import multiprocessing
def demo1(q):
try:
q.put('a')
except Exception as e:
print(e.args[0])
def demo2(q):
try:
data = q.get()
print(data)
except Exception as e:
print(e.args[0])
if __name__ == '__main__':
q = multiprocessing.Queue()
try:
p1 = multiprocessing.Process(target=demo1)
p2 = multiprocessing.Process(target=demo2)
p1.start()
p2.start()
except Exception as e:
print(e.args[0])
打印
Process Process-1:
Traceback (most recent call last):
File "xxxx\Python\Python37\lib\multiprocessing\process.py", line 297, in _bootstrap
self.run()
File "xxxx\Python\Python37\lib\multiprocessing\process.py", line 99, in run
self._target(*self._args, **self._kwargs)
TypeError: demo1() missing 1 required positional argument: 'q'
Process Process-2:
Traceback (most recent call last):
File "xxxx\Python\Python37\lib\multiprocessing\process.py", line 297, in _bootstrap
self.run()
File "xxxx\Python\Python37\lib\multiprocessing\process.py", line 99, in run
self._target(*self._args, **self._kwargs)
TypeError: demo2() missing 1 required positional argument: 'q'
显然,此时报错的位置不是在自己写的代码中,而是在Python自己的lib\multiprocessing\process.py中报错,属于Process类的参数错误。
四、进程池
1.进程池介绍
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态生成多个进程,但是如果是上百甚至上千个目标,手动的去创建的进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool类。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求,但是如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
原理如下图所示:

尝试:
from multiprocessing import Pool
import os, time, random
def work(msg):
t_start = time.time()
print('%s开始执行,进程号为%d' % (msg, os.getpid()))
time.sleep(random.random() * 2)
t_stop = time.time()
print(msg, "执行完成,耗时%0.2f seconds" % (t_stop - t_start))
def demo():
pass
if __name__ == '__main__':
po = Pool(3) # 定义一个进程池,包含3个进程
for i in range(0, 10):
# 添加任务,有10个任务
po.apply_async(work, (i,))
print("--start--")
# 关闭进程池,不再接收新的任务请求
po.close()
# 等待子进程执行完成,主进程再结束
po.join()
print("--end--")
显示:

易知,最开始有0、1、2三个进程执行,0执行完成后3开始执行,1执行完成后4开始执行,3执行完成后5开始执行,一直循环,直到所有进程完成。
修改进程池参数–包含4个进程:
from multiprocessing import Pool
import os, time, random
def work(msg):
t_start = time.time()
print('%s开始执行,进程号为%d' % (msg, os.getpid()))
time.sleep(random.random() * 2)
t_stop = time.time()
print(msg, "执行完成,耗时%0.2f seconds" % (t_stop - t_start))
def demo():
pass
if __name__ == '__main__':
po = Pool(4) # 定义一个进程池,包含3个进程
for i in range(0, 10):
# 添加任务,有10个任务
po.apply_async(work, (i,))
print("--start--")
# 关闭进程池,不再接收新的任务请求
po.close()
# 等待子进程执行完成,主进程再结束
po.join()
print("--end--")
显示:
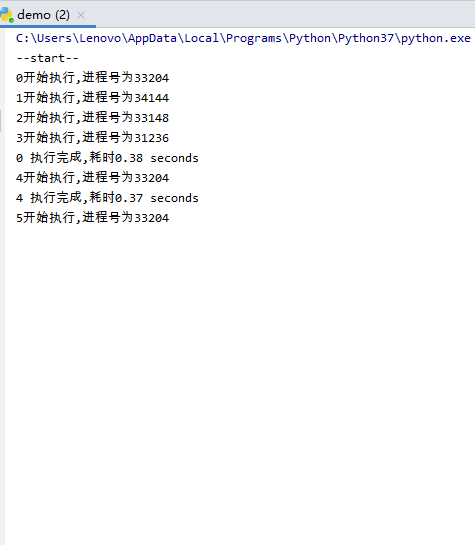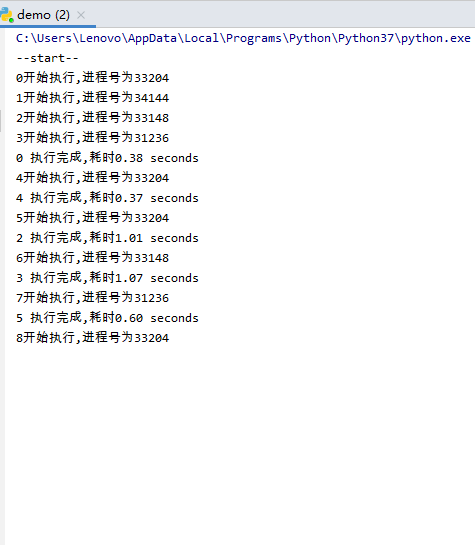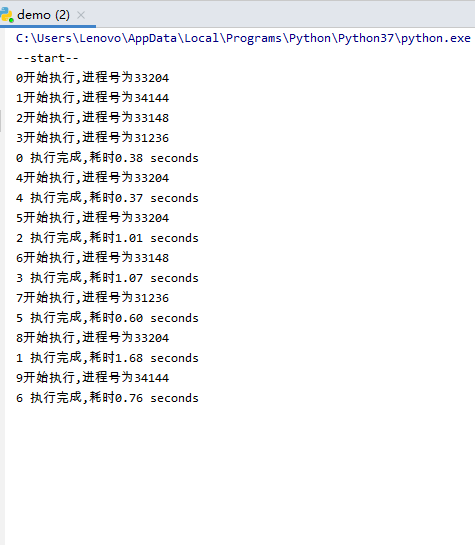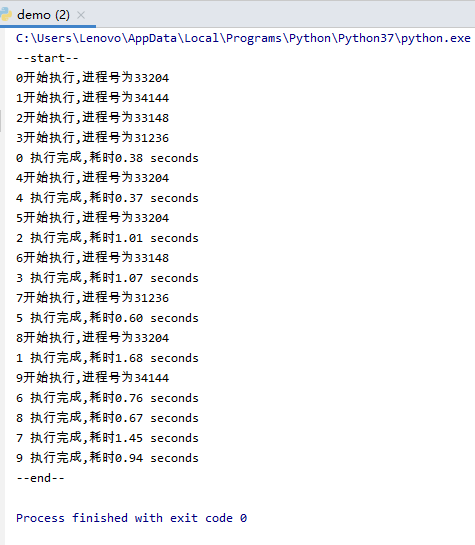
显然,进程池有4个进程时,执行效率更高,因为同时有4个进程在执行。
po.close()执行后不能再添加任务:
from multiprocessing import Pool
import os, time, random
def work(msg):
t_start = time.time()
print('%s开始执行,进程号为%d' % (msg, os.getpid()))
time.sleep(random.random() * 2)
t_stop = time.time()
print(msg, "执行完成,耗时%0.2f seconds" % (t_stop - t_start))
def demo():
pass
if __name__ == '__main__':
po = Pool(4) # 定义一个进程池,包含3个进程
for i in range(0, 10):
# 添加任务,有10个任务
po.apply_async(work, (i,))
print("--start--")
# 关闭进程池,不再接收新的任务请求
po.close()
po.apply_async(demo)
# 等待子进程执行完成,主进程再结束
po.join()
print("--end--")
打印
--start--
Traceback (most recent call last):
File "xxx/demo.py", line 151, in <module>
po.apply_async(demo)
File "xxxx\Python\Python37\lib\multiprocessing\pool.py", line 362, in apply_async
raise ValueError("Pool not running")
ValueError: Pool not running
要添加任务,必须要在po.close()之前添加。
2.进程池中进程间的通信
用multiprocessing.Queue进行尝试:
import multiprocessing
def demo1(q):
q.put('a')
def demo2(q):
data = q.get()
print(data)
if __name__ == '__main__':
q = multiprocessing.Queue()
po = multiprocessing.Pool()
po.apply_async(demo1,(q,))
po.apply_async(demo2, (q,))
po.close()
po.join()
打印
打印为空,即没有实现进程池的进程间通信。
进行测试:
import multiprocessing
def demo1(q):
print(1)
q.put('a')
def demo2(q):
print(2)
data = q.get()
print(data)
if __name__ == '__main__':
q = multiprocessing.Queue()
po = multiprocessing.Pool()
po.apply_async(demo1,(q,))
po.apply_async(demo2, (q,))
po.close()
po.join()
打印
还是为空,进一步进行异常处理:
import multiprocessing
def demo1(q):
try:
q.put('a')
except Exception as e:
print(e.args[0])
def demo2(q):
try:
data = q.get()
print(data)
except Exception as e:
print(e.args[0])
if __name__ == '__main__':
q = multiprocessing.Queue()
po = multiprocessing.Pool()
po.apply_async(demo1,(q,))
po.apply_async(demo2, (q,))
po.close()
po.join()
打印
还是为空,显然可得,demo1()和demo2()两个函数根本没有执行,所以进程池的进程间通信不能用multiprocessing.Queue,要用multiprocessing.Manager().Queue。
再次尝试:
import multiprocessing
def demo1(q):
try:
q.put('a')
except Exception as e:
print(e.args[0])
def demo2(q):
try:
data = q.get()
print(data)
except Exception as e:
print(e.args[0])
if __name__ == '__main__':
q = multiprocessing.Manager().Queue()
po = multiprocessing.Pool()
po.apply_async(demo1,(q,))
po.apply_async(demo2, (q,))
po.close()
po.join()
打印
a
此时正常运行。
进程池里的进程,如果出现异常,不会主动抛出,所以在用进程池实现多任务时尽量增加异常处理try...except...。
总结:
现在有3种队列:
(1)queue.Queue:
不能完成进程之间的通信;
(2)multiprocessing.Queue:
实现进程间的通信;
(3)multiprocessing.Manager().Queue:
实现进程池间的进程通信。
五、应用–多任务文件夹复制
实现思路:
- 获取用户要复制的文件夹名
- 创建新的文件夹
- 获取文件夹中所有待拷贝的文件名字
- 创建进程池
- 添加拷贝任务
代码初步实现:
import multiprocessing
import os
def copy_file(index,file_name,new_folder,old_folder):
'''文件拷贝'''
print('%2d:File to Copy:%s' % (index + 1,file_name))
# 读取旧文件
old_file = open(old_folder + '/' + file_name,'rb')
content = old_file.read()
old_file.close()
# 保存到新的文件夹
# new_file = open(new_folder + '/' + file_name, 'wb')
# new_file.write(content)
# new_file.close()
with open(new_folder + '/' + file_name, 'wb') as f:
f.write(content)
print('%2d:File %s Copy Finished' % (index + 1,file_name))
def main():
# 获取用户要复制的文件夹名
old_folder = input('Inout Directory Name:')
# 创建新的文件夹
new_folder = old_folder + '--copy'
if not os.path.exists(new_folder):
os.mkdir(new_folder)
# 获取文件夹中所有待拷贝的文件名字
file_list = os.listdir(old_folder)
# 创建进程池
po = multiprocessing.Pool(5)
# 添加拷贝任务
for index,file_name in enumerate(file_list):
po.apply_async(copy_file,args=(index,file_name,new_folder,old_folder))
po.close()
po.join()
if __name__ == '__main__':
main()
打印
Inout Directory Name:test
2:File to Copy:_collections_abc.py
1:File to Copy:_bootlocale.py
5:File to Copy:_dummy_thread.py
3:File to Copy:_compat_pickle.py
4:File to Copy:_compression.py
2:File _collections_abc.py Copy Finished
6:File to Copy:_markupbase.py
5:File _dummy_thread.py Copy Finished
1:File _bootlocale.py Copy Finished
3:File _compat_pickle.py Copy Finished
4:File _compression.py Copy Finished
6:File _markupbase.py Copy Finished
7:File to Copy:_osx_support.py
8:File to Copy:_pydecimal.py
7:File _osx_support.py Copy Finished
9:File to Copy:_pyio.py
8:File _pydecimal.py Copy Finished
10:File to Copy:_py_abc.py
11:File to Copy:__future__.py
9:File _pyio.py Copy Finished
11:File __future__.py Copy Finished
12:File to Copy:__phello__.foo.py
10:File _py_abc.py Copy Finished
12:File __phello__.foo.py Copy Finished
进一步扩展–增加进度显示
import multiprocessing
import os
import random
import time
def copy_file(index,file_name,new_folder,old_folder,q):
'''文件拷贝'''
print('%2d:File to Copy:%s' % (index + 1,file_name))
# 读取旧文件
old_file = open(old_folder + '/' + file_name,'rb')
content = old_file.read()
old_file.close()
# 保存到新的文件夹
# new_file = open(new_folder + '/' + file_name, 'wb')
# new_file.write(content)
# new_file.close()
with open(new_folder + '/' + file_name, 'wb') as f:
f.write(content)
q.put(file_name)
print('%2d:File %s Copy Finished' % (index + 1,file_name))
time.sleep(random.random() * 5)
def main():
# 获取用户要复制的文件夹名
old_folder = input('Inout Directory Name:')
# 创建新的文件夹
new_folder = old_folder + '--copy'
if not os.path.exists(new_folder):
os.mkdir(new_folder)
# 获取文件夹中所有待拷贝的文件名字
file_list = os.listdir(old_folder)
# 创建进程池
po = multiprocessing.Pool(5)
# 创建队列
q = multiprocessing.Manager().Queue()
# 添加拷贝任务
for index,file_name in enumerate(file_list):
po.apply_async(copy_file,args=(index,file_name,new_folder,old_folder,q))
po.close()
# 增加进度条
file_count = len(file_list)
copy_count = 0
while True:
q.get()
copy_count += 1
print('Copy Process:%2.2f%%' % (copy_count / file_count * 100.0))
# 退出循环
if copy_count >= file_count:
break
po.join()
if __name__ == '__main__':
main()
显示

