文章目录
一、矩阵
1. 矩阵的定义
在数学中,矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合。
2. 矩阵的创建
(1)mat()函数方法
格式1:用字符串创建矩阵;矩阵一般命名用大写如A;中间的数用空格隔开,每行用分号隔开
- 代码:
A = numpy.mat('1 0 0 0;0 1 0 0;-1 2 1 0;1 1 0 1')
print(A)

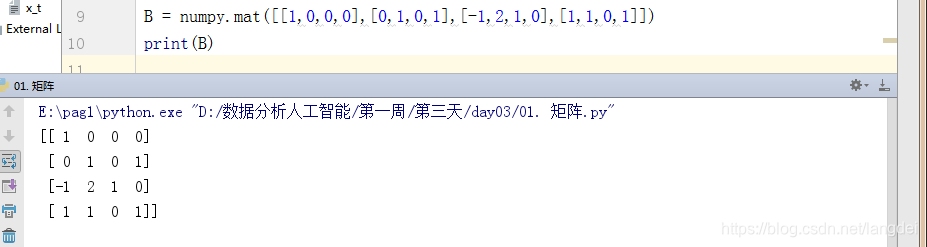
格式2: 列表套列表的写法
- 代码:
B = numpy.mat([[1,0,0,0],[0,1,0,1],[-1,2,1,0],[1,1,0,1]])
print(B)
(2)matrix()函数
和mat的两种写法一样都能创建矩阵
C = numpy.matrix('1 0 0 0;0 1 0 0;-1 2 1 0;1 1 0 1')
D = numpy.matrix([[1,0,0,0],[0,1,0,1],[-1,2,1,0],[1,1,0,1]])
(3)bmat()函数
说明:通过分块矩阵创建big矩阵
① 字符串写法
BIG_MAT1 = numpy.bmat('A B;C D')
print(BIG_MAT1)

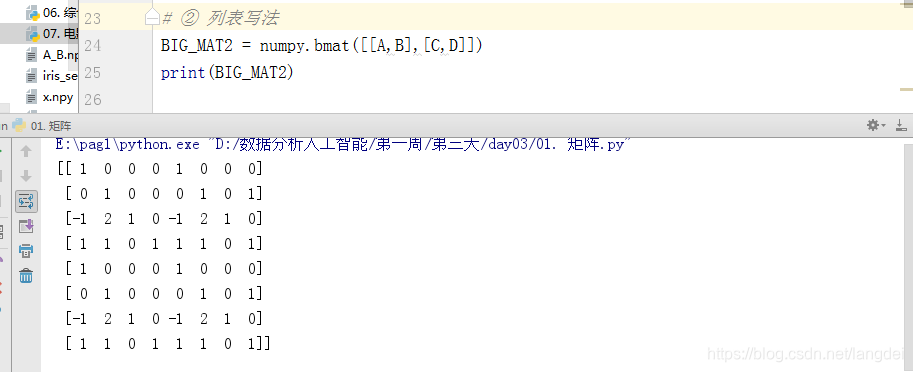
② 列表写法
BIG_MAT2 = numpy.bmat([[A,B],[C,D]])
print(BIG_MAT2)

3. 矩阵的运算
(1)矩阵与数相乘–》数乘:mat*3
A = numpy.mat([[1,1],[1,1]])
print(A*3)

(2)矩阵加减法:A+B
A = numpy.mat([[1,1],[1,1]])
B = numpy.mat([[1,2],[3,4]])
print(A+B)

(3)矩阵相乘:A*B
A = numpy.mat([[1,1],[1,1]])
B = numpy.mat([[1,2],[3,4]])
print(A*B)

(4)矩阵对应元素相乘
A = numpy.mat([[1,1],[1,1]])
B = numpy.mat([[1,2],[3,4]])
E = numpy.multiply(A,B)
print('E:',E)
print('A*B',A*B)

注意:与AB不同的是multiply是对应位置两个元素相乘,而不是AB那样A的每行和B的每列相乘
(5)数组的四则运算

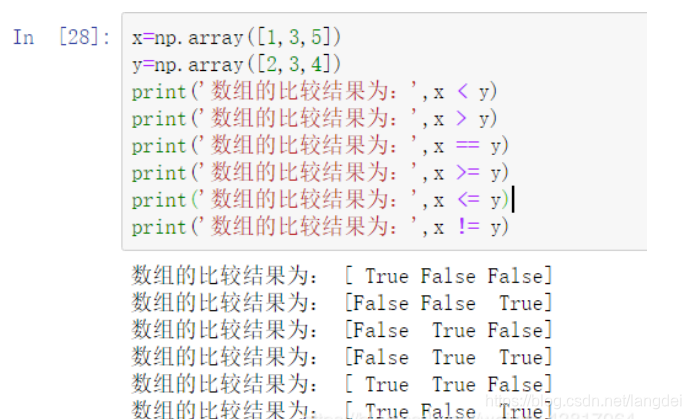
(6)数组的比较运算
在NumPy逻辑运算中,np.all函数表示逻辑and,np.any函数表示逻辑or

4. 矩阵的常用属性
(1)转置----》T
转置:顾名思义就是将行和列互换;行变为对应列
A = numpy.mat([[1,1],[1,1]])
B = numpy.mat([[1,2],[3,4]])
E = numpy.multiply(A,B)
print('E:',E)
print("E的转置:",E.T)

(2)共轭转置矩阵-- 》H 即A(i,j)=A(j,i)
共轭矩阵:即对应的A(i,j)=A(j,i)
A = numpy.mat([[1,1],[1,1]])
B = numpy.mat([[1,2],[3,4]])
E = numpy.multiply(A,B)
print('E:',E)
print('共轭矩阵',E.H)

(3)逆矩阵—》I 即A*B=E(单位矩阵)
逆矩阵:就是A*B=E(单位矩阵)的矩阵
A = numpy.mat([[1,1],[1,1]])
B = numpy.mat([[1,2],[3,4]])
E = numpy.multiply(A,B)
print('E:',E)
print(E.I)

(4)返回自身数据的2维数组的一个视图—》A
A = numpy.mat([[1,1],[1,1]])
B = numpy.mat([[1,2],[3,4]])
E = numpy.multiply(A,B)
print('E:',E)
print(E.A,type(E.A))

5. ufunc函数的广播机制
广播是指不同形状的数组之间执行算数运算的方式。若两个数组的shape不一致,则NumPy会实行广播机制。

原理图:

注意:若是缺少列,则以第一列数为基础来补充;
若是缺少行,则以第一行为基础来补充

- 第一步:先求出对应数列的shape

- 第二步:让所有的shape向最长的看齐
- 第三步:补齐对应的行或列
- 第四步:执行加操作
6. 使用numpy进行数据分析—》文件读写
(1)保存save
注意:使用save()函数保存的是二进制文件,文件的扩展名:.npy
import numpy
x = numpy.array([[1,1,1],[2,2,2],[3,3,3],[4,4,4]])
# 1. 使用save()函数保存的是二进制文件,文件的扩展名:.npy
numpy.save('x',x)

(2)savetxt()保存的是文本文件
x = numpy.array([[1,1,1],[2,2,2],[3,3,3],[4,4,4]])
numpy.savetxt('x_t',x)

(3)savez()函数
注意:savez()函数—可以将多个数组保存成一个文件;文件扩展名:npz
A = numpy.array([[1,2,3],[4,5,6]])
B = numpy.arange(0,1,0.1)
numpy.savez('A_B',A,B)

(4)读取load
load()函数-----》从二进制的文件中读取数据
result = numpy.load('x.npy')
print(result,type(result))

注意:在存的时候可以省略扩展名,但读取时不能省略扩展名,否则报错
(5)loadtxt()函数
loadtxt()函数— 读取文本文件(txt,csv)
result = numpy.loadtxt('x_t')
print(result)

(6)genfromtxt
genfromtxt 保存结构化数据
df = np.dtype([('name',np.str_,128),('nums',np.int32),('local',np.str_,16)])
jobs = np.genfromtxt('tecent_jobs.txt',dtype=df,delimiter=',')
print(jobs['name'])
print(jobs['local'])
print(jobs['nums'],type(jobs['nums']))
total = jobs['nums'][0]+jobs['nums'][1]+jobs['nums'][2]
print(total)

7. 排序问题
(1)直接排序
① sort函数
sort 函数是最常用的排序方法。 arr.sort()
sort 函数也可以指定一个 axis 参数,使得 sort 函数可以沿着指定轴对数据集进行排序。axis=1 为沿横轴排序; axis=0 为沿纵轴排序。
arr = np.array([[4,3,2],[2,1,4]])
print('原始数据:\n',arr)
print(arr.shape,arr.shape[1])
#排序
arr.sort()
print(arr)

按纵轴排序
arr = np.array([[4,3,2],[2,1,4]])
print('原始数据:\n',arr)
arr.sort(axis=0)
print(arr)

(2)间接排序
① argsort()函数
说明:有一个返回值为重新排序后的值的下标(索引)
arr = np.array([2,1,0,5,3])
new_arr = arr.argsort()
print('arr:\n',arr)# [2 1 0 5 3]
print('new_arr:\n',new_arr)# [2 1 0 4 3]

总结:间接排序不更改原始数据的物理结构
缺点:不够直观,优点:不改变原始数据的原结构
② lexsort()函数
说明:按照最后一个传入数据进行排序,返回结果依然是索引下标值
a = np.array([3,2,6,4,5])
b = np.array([50,30,40,20,10])
c = np.array([400,300,600,100,200])
result = np.lexsort((a,b,c))
print(result)#[3 4 1 0 2]
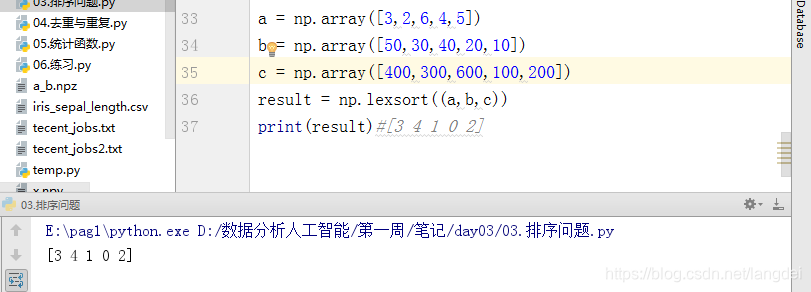
注意:这与你传入的顺序有关,该函数返回的是最后一个矩阵排序后的下标
8. 去重与重复
1. unique()函数
unique()函数的作用是去重,使得矩阵中的数唯一
arr =numpy.array([1,2,3,4,1,2,3,4])
result = numpy.unique(arr)
print(result)

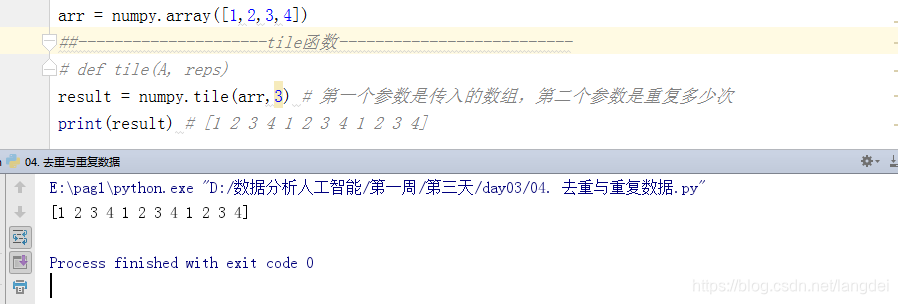
2. tile()函数
tile()函数的作用是重复
注意:第一个参数是传入的数组,第二个参数是重复多少次
- 一维数组:
import numpy arr = numpy.array([1,2,3,4]) result = numpy.tile(arr,3) # 第一个参数是传入的数组,第二个参数是重复多少次 print(result) # [1 2 3 4 1 2 3 4 1 2 3 4]
- 多维数组:
arr = numpy.array([[1,2,3],[4,5,6]])
result = numpy.tile(arr,3) # 第一个参数是传入的数组,第二个参数是重复多少次
print(result)

3. repeat()函数
repeat函数作用也是重复
repeat 函数主要有三个参数,参数“a”是需要重复的数组元素,参数“repeats”是重复 次数,参数“axis”指定沿着哪个轴进行重复,axis = 0 表示按行进行元素重复;axis = 1 表示按列进行元素重复。
-
不指定全部重复
arr = numpy.array([[1,2],[3,4]]) result3 = numpy.repeat(arr,2) print('result3:',result3) # [1 1 2 2 3 3 4 4]
区别:tile函数是对数组整体进行重复操作,而repeat函数是对函数中每个元素进行重复操作 -
按行重复

-
按列重复

9. 统计函数

当 axis=0 时,表示沿着纵轴计算。当 axis=1 时,表示沿着横轴计算。默认时计算一个总值


写法:① numpy.函数名(数组名) ② 数组名.函数名()
案例:

import numpy
iris_arr = numpy.loadtxt('iris_sepal_length.csv')
print('花萼长度为:\n',iris_arr)
# 排序
# 直接排序
iris_arr.sort()
print('排序后的数据集:\n',iris_arr)
# 去重
unique_iris = numpy.unique(iris_arr)
print('iris去重后的数据:\n',unique_iris)
# 统计函数的操作
# 最大值
print('最大值:',numpy.max(iris_arr))
# 最小值
print('最小值:',iris_arr.min())
# 求和
print('求和:',iris_arr.sum()) # 876.5
# 累计和
print("累计和:",iris_arr.cumsum())
# 累计积
print(iris_arr.cumprod())
# 均值
print(iris_arr.mean())
# 标准差
print(iris_arr.std())
# 方差
print(iris_arr.var())
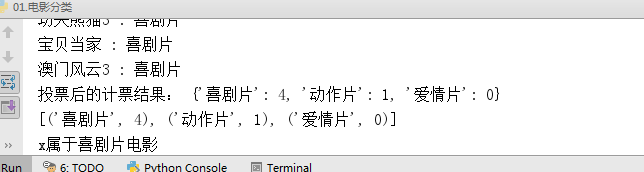
10. 欧氏距离求电影分类
import math
# 定义:一个样本与数据集中的k个样本最相似,
# 如果这k个样本中的大多数属于某一个类别,
# 则该样本也属于这个类别。
#第一步:使用python字典来构造数据集
movie_data = {"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]}
#第二步:计算某一个样本与数据集中的样本的相似度
# (利用欧式距离,值越小越相似)
x = [23,3,17]
result = []
for key,value in movie_data.items():
#计算欧式距离
distance = math.sqrt((value[0] - x[0])**2+(value[1] - x[1])**2+(value[2] - x[2])**2)
print(key,":",value,':',distance)
result.append([key,distance])
print('排序前:\n',result)
# 第三步:按距离的远近进行排序,选取距离最小的k个样本,此处选5
result.sort(key=lambda item:item[1])
print('排序后:',result)
pre_k_data = result[:5]
print(pre_k_data)
#第四步:投票(确定前k个样本属于哪种类型,从而判断x的类别)
types = {'喜剧片':0,'动作片':0,'爱情片':0}
for data in pre_k_data:
name = data[0]
value = movie_data[name]
movie_type = value[3]
print(name,':',movie_type)
types[movie_type] = types[movie_type]+1
print('投票后的计票结果:',types)
final_result = sorted(types.items(),key=lambda item:item[1],reverse=True)
# types.items()---[(k,v),(k,v),(k,v)]
print(final_result)
print('x属于%s电影'%(final_result[0][0]))