在本系列的第 18 篇文章中,我详细讲解了从 MS Access 数获取数据,通过 PQ 完成进出存查询的过程。在示例中, stock_movement_details 查询大约 28000+ 行,计算出基于月份的进出存大致耗时 20 秒左右。使用 Excel 实现这样的输出报表有一定难度,从这个角度来说 PQ 是一个巨大的飞跃。但 28000 条的数据耗时 20 秒,性能就比较低了,这引起了我的好奇。经过一番思考和探索,发现了一些可以提高性能的做法。
查看 PQ 查询消耗的时间可以这样做,在 Excel 结果输出表中,右键选择菜单的【刷新】,或者在右边【查询&连接】面板中点击【刷新】按钮,启动数据刷新。如果数据计算和上载耗时比较长,在Excel 状态栏出现 “正在后台执行查询…” 的提示。点击这个提示,可以中断刷新,或者观察查询的耗时。不过这个界面设计的不够友好,如果查询耗时比较短,就很难调出对话框查看; 另外执行完毕后,计时器也不停止,只能用眼睛观察究竟用了多长时间。

查询的过程大体分为三步:
- 数据从数据源加载到 Power Query
- Power Query 处理数据 (transformations)
- 数据上载到 Excel 工作表
当然这个过程消耗的时间还有很多外在因素,比如从数据库加载数据受网络的影响,从本地加载数据也受内存大小和硬盘读写速度的影响。如何确定这个耗时是谁的责任呢?经过搜索,也没有发现很好的方法。网上有介绍 PQ 的 Query Folding – 简单的说,就是 Power Query 与关系型数据库、OData 等数据源连接的时候,会考虑将一些数据处理 (transformation) 传回数据源进行处理,从而提高速度。能执行 Query Folding 的数据源包括:
- Relational sources (SQL Server, Oracle, …). They support most Power Query functionality.
- OData sources (such as a SharePoint list for example and the Azure Marketplace)
- Active Directory
- Exchange
- HDFS, Folder.Files and Folder.Contents (for basic operations on paths)
SQL Server 数据库的 SQL Server Managment Studio 提供了 SQL Server Profiler 工具,所以为了比较和观察,我立即将数据源切换到 SQL Server,执行相同的计算后,发现在 MS Access 中原来需要 20 秒的操作缩短到 2 秒左右。这说明 Query Folding 在提高新能方面确实起了作用,有 SQL Server 参与计算的功劳。根据文章的介绍,我也近距离观察了 Power Query query folding 的一些细节。folding 在英文中主要是弯曲、折叠的意思,也有 mix an ingredient with another ingredient 的意思,所以我将其翻译为混合查询,不一定正确。
在查询编辑器中,选择右边步骤,右键菜单有查看本机查询菜单项,如果菜单为灰色,表示本步骤是 Power Query 做的处理,如果不是灰色,表示该步骤由 PQ 送回数据源(比如数据库)进行处理。比如,我们选择 ExpandedCols 这一步骤,查看本机查询:
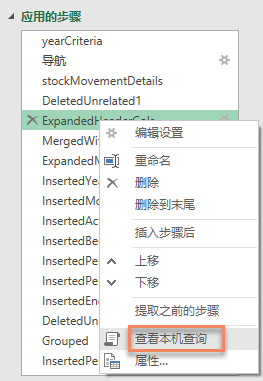
可以看到这一步骤的操作实际上是一个 SQL 语句:

下面我们进入 SQL Server Management Studio 来观察这一过程。通过菜单 【工具】- 【SQL Server Profiler】打开 一个新的 Profiler:

在 SQL Server Profiler 中,首先切换到事件选择面板。因为我们只要监控 sql 语句,所以只需要保留 SQL: BatchCompleted 事件即可,减少 log 输出方便我们在后面查看日志快速定位。

在 Excel 中,对查询进行刷新操作,不要执行太多操作,以免干扰 SQL Server Profiler 日志内容。刷新后回到 SQL Server Profiler 界面, 停止 Trace。
没有运行之前,Profiler 的界面如下:

刷新之后,Profiler 界面如下:

在这个界面可以观察完整过程,比如 SQL Server 执行了哪些 SQL 语句,每一步骤消耗了多长时间。
不使用 Query Folding
- 如果在查询中使用了
Table.Buffer函数对查询表进行缓存,则不会启动 query folding 功能,可以对数据源调用Table.Buffer函数,然后在 SQL Server Profiler 中测试看看两种方法的 sql 语句有什么不同。 - 如果在查询中使用了自定义的 SQL 语句,则不会启动 query folding 功能
其他还有一些不会启动 query folding 的场景,个人觉得没有必要刻意去记。有兴趣的话请参考我在本文的参考部分列出的文章,里面有具体说明。
一些观察的结论
- SQL Server 数据库启用 query folding 能提高性能,因为 SQL Server 作为专门的数据库,在服务器端运行,肯定比客户端的 Power Query 有更高性能
- MS Access 数据库如果对数据源调用
Table.Buffer,反而性能下降得非常厉害,不知道什么原因。在工作表刷新数据的过程中,Windows 任务管理器显示有两个与 Power Query 相关的进程,但耗用内存不大,也没有在计算的过程中占用更大的内存。 - 连接 csv 文件中的数据,PQ 处理的耗时也没有比 MS Access 更慢,说明 PQ 本身的处理性能还是可以的。
- 按网上的说法,在循环中(比如
List.Generate函数)使用Table.Buffer能提高性能,未测试。
