问题:选出蜀国中五虎将
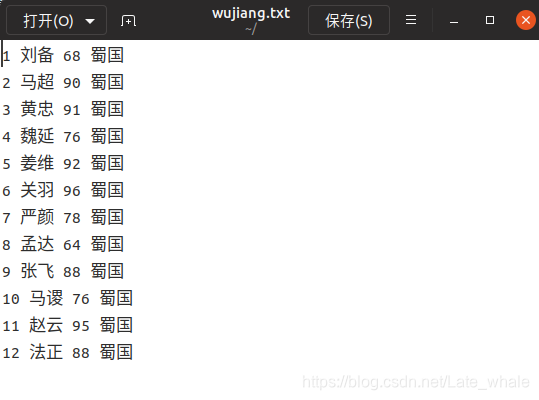
原始数据如下:
序号 姓名 武力值 国家
1 刘备 68 蜀国
2 马超 90 蜀国
3 黄忠 91 蜀国
4 魏延 76 蜀国
5 姜维 92 蜀国
6 关羽 96 蜀国
7 严颜 78 蜀国
8 孟达 64 蜀国
9 张飞 88 蜀国
10马谡 76 蜀国
11 赵云 95 蜀国
12 法正 88 蜀国
预期结果如下:
6 关羽 96 蜀国
11 赵云 95 蜀国
5 姜维 92 蜀国
3 黄忠 91 蜀国
2 马超 90 蜀国
新建数据文件
步骤
导入必要的包,因为用到的是pyspark,最好导入findspark,可以避免一些看不懂的错误
初始化sparkcontext,local为本地工作方式,topapp为随意取的名字

从hdfs上读取文件,并输出第一行看数据结构方便后面操作

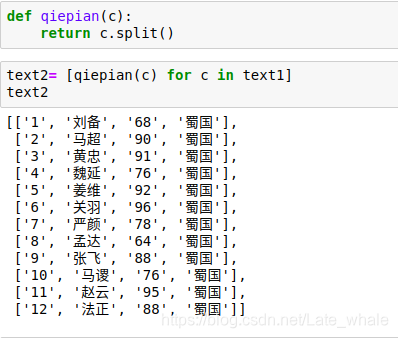
将text转化为list对象(rdd调用collect后变为list对象)

自定义函数,将list数据按空格切开
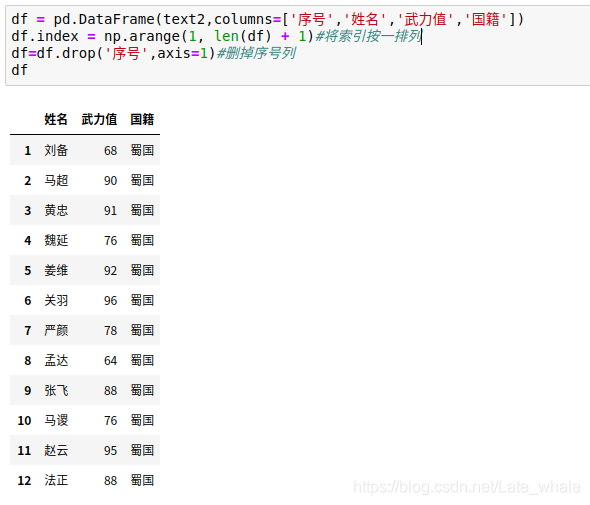
将text2转化为dataframe对象,
将武将按武力值排序。
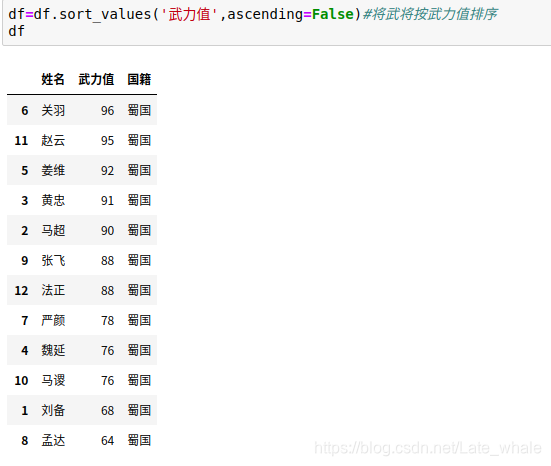
取出武力值top5,如果想取10,则是head(10)。
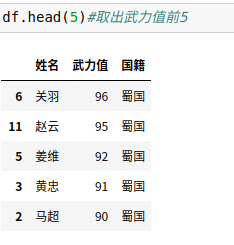
将dataframe转化为spark dataframe,并将结果存入hdfs

在命令行中查看结果(一长串为自动生成的名字)

