转载请标明原创:https://me.csdn.net/jxysgzs
一、必要的前言
本篇我想给大家讲一下在dao层中继承的JpaRepository与JpaSpecificationExecutor的底层代码,因为有些同学应该喜欢深究一些底层的知识,如果你只追求使用,可以不用看这一篇了,直接看下一篇即可,本篇项目与其他篇章没有任何连接。
二、创建新的项目
为了不影响主项目的教学,咱们创建一个新的项目,这里我节奏快一点,毕竟已经有经验了,希望大家跟得上。
1.创建springboot项目,导入相关依赖
以下是导入的包,注意,这里我们多导入了一个测试类的包。
<!-- springData的启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- 测试工具的启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- druid连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
2.配置application.properties文件并创建一个新的数据库
创建一个空数据库,ssm

配置application.properties文件
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/ssm?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=你的密码
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
#ddl-auto:create----每次运行该程序,没有表格会新建表格,表内有数据会清空
#
#ddl-auto:create-drop----每次程序结束的时候会清空表
#
#ddl-auto:update----每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
#
#ddl-auto:validate----运行程序会校验数据与数据库的字段类型是否相同,不同会报错
spring.jpa.hibernate.ddl-auto=update
#控制台输出sql语句
spring.jpa.show-sql=true
3.添加pojo包,创建Users.class文件
添加Users.class
package cn.jxys.pojo;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name="t_users")
public class Users {
@Id
/*主键生成策略
TABLE:使用一个特定的数据库表格来保存主键。
SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
IDENTITY:主键由数据库自动生成(主要是自动增长型)
AUTO:主键由程序控制。*/
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="id")
private Integer id;
@Column(name="name")
private String name;
@Column(name="age")
private Integer age;
@Column(name="adress")
private String adress;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAdress() {
return adress;
}
public void setAdress(String adress) {
this.adress = adress;
}
@Override
public String toString() {
return "Users [id=" + id + ", name=" + name + ", age=" + age + ", adress=" + adress + "]";
}
}
三、Repository接口
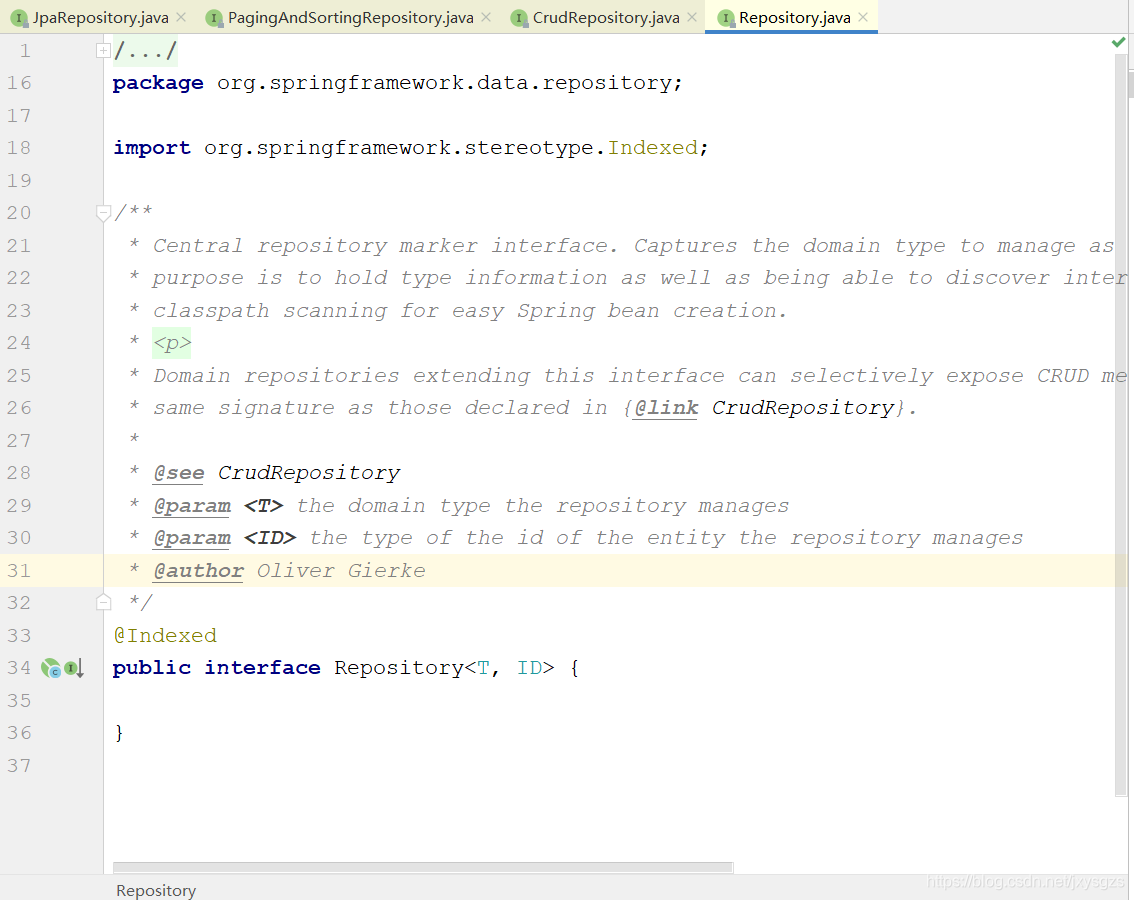
Repository是在jpa封装的工具接口中最顶级的接口,他里面并没有任何的的抽象方法供我们使用,但是他定义了一系列的标准,包括上一篇中我们使用的自定义抽象接口功能。
测试一下
这里我们先启动一下项目,让项目为我们创建好一个名叫t_users的表,并且在表中添加一些数据

1.创建dao层
创建UsersRepositoryByName.java文件,该类继承Repository接口
package cn.jxys.dao;
import java.util.List;
import org.springframework.data.repository.Repository;
import cn.jxys.pojo.Users;
/**
* 模拟Sql语句接口最终端父类
* @author a2417
*
*/
public interface UsersRepositoryByName extends Repository<Users, Integer> {
//findBy(关键字)+属性名称(属性名称)+查询条件(首字母大写)Equals判断相等
List<Users> findByName(String name);
List<Users> findByNameAndAge(String name,Integer age);
List<Users> findByNameLike(String name);
}
2.创建测试类
测试类大家应该会创建吧,实在不会开一下junit去,很快就能明白
package test;
import java.util.List;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import cn.jxys.App;
import cn.jxys.dao.UsersRepositoryByName;
import cn.jxys.pojo.Users;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes=App.class)
public class UsersTest {
@Autowired
private UsersRepositoryByName usersRepositoryByName;
@Test
public void findByNameTest(){
List<Users> list=this.usersRepositoryByName.findByName("李健");
System.out.println(list.toString());
}
}
3.运行测试findByNameTest方法
双击选中之后,右键启动哦!
四、CrudRepository接口
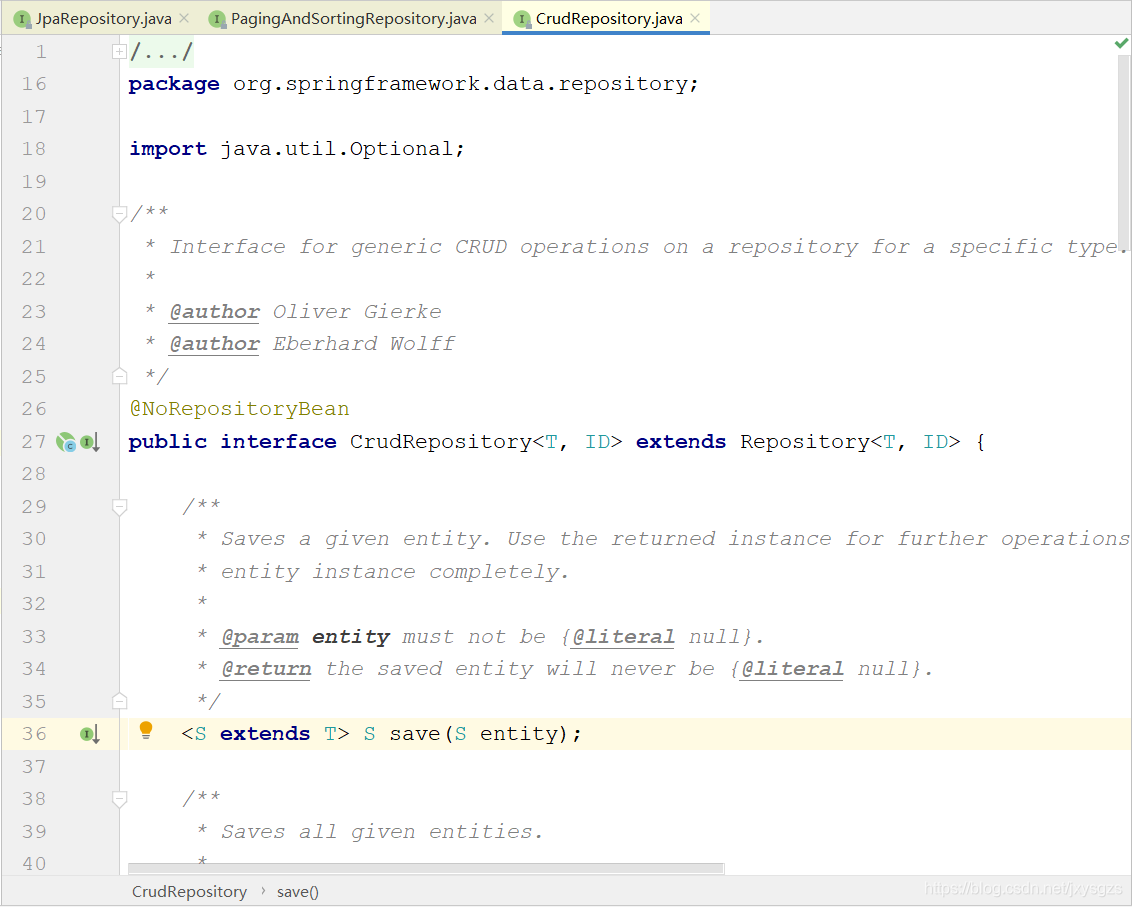
该接口便是首先继承了Repository接口,从名称可以看出,该接口增加了一些基本的增删改查方法,值得注意的是@NoRepositoryBean,该注解定义了该接口不会被Spring容器注册成bean,所以我们是不能直接使用他的,固需要继承一下。
1.在dao层中新增一个接口,名叫UsersRepositoryCrudRepository,继承CrudRepository接口。
package cn.jxys.dao;
import org.springframework.data.repository.CrudRepository;
import cn.jxys.pojo.Users;
/**
* 基本增删改查操作接口,集成了Repository
*
*/
public interface UsersRepositoryCrudRepository extends CrudRepository<Users,Integer> {
}
2.修改测试类
package test;
import java.util.List;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import cn.jxys.App;
import cn.jxys.dao.UsersRepositoryByName;
import cn.jxys.dao.UsersRepositoryCrudRepository;
import cn.jxys.pojo.Users;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes=App.class)
public class UsersTest {
@Autowired
private UsersRepositoryByName usersRepositoryByName;
@Autowired
private UsersRepositoryCrudRepository usersRepositoryCrudRepository;
@Test
public void findByNameTest(){
List<Users> list=this.usersRepositoryByName.findByName("李健");
System.out.println(list.toString());
}
@Test//插入操作
public void crudRepository(){
Users user=new Users();
user.setAdress("中国");
user.setAge(18);
user.setName("赵四");
this.usersRepositoryCrudRepository.save(user);
}
@Test//修改操作
public void crudUpdataRepository(){
Users user=new Users();
user.setId(6);
user.setAdress("承德");
user.setAge(19);
user.setName("赵四");
this.usersRepositoryCrudRepository.save(user);
}
}
3测试
这里我们定义了两个方法,一个新增,一个修改,跟我们第一篇中写的一样,只有一个save方法实现的。
运行crudRepository方法:

运行crudUpdataRepository方法:

五、PagingAndSortingRepository接口
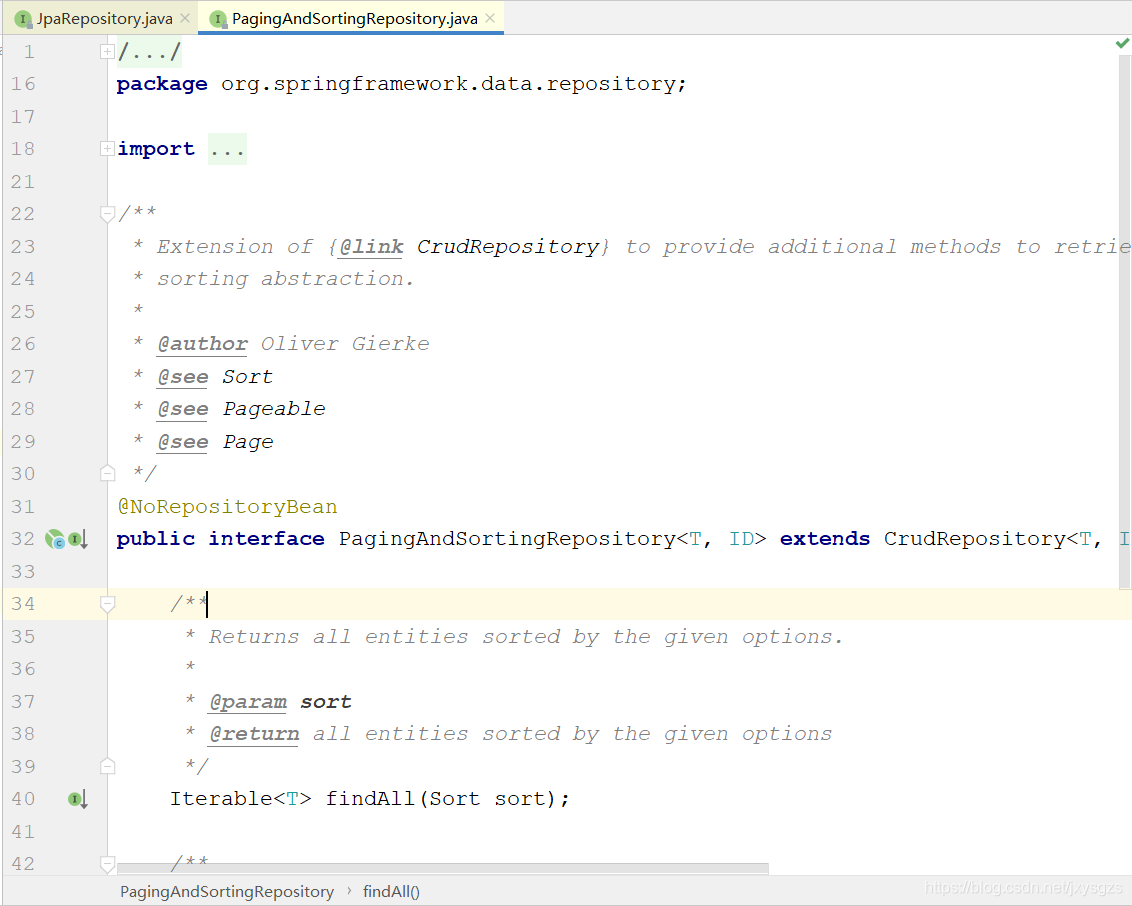
该接口继承了CrudRepository接口并且也具有@NoRepositoryBean注解,该接口主要提供了一些分页及排序所需要的方法。其实我们到目前还未讲解排序的使用,这里说这些主要是让大家理解jpa的设计,对于后面的使用会很有帮助。
1.在dao层中添加新接口名叫UsersPagingAndSortingRepository,继承PagingAndSortingRepository接口
package cn.jxys.dao;
import org.springframework.data.repository.PagingAndSortingRepository;
import cn.jxys.pojo.Users;
/**
* 排序查询和分页查询的接口,集成了CrudRepositroy
*
*/
public interface UsersPagingAndSortingRepository extends PagingAndSortingRepository<Users, Integer> {
}
2.修改测试文件
package test;
import java.util.List;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.domain.Sort.Direction;
import org.springframework.data.domain.Sort.Order;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import cn.jxys.App;
import cn.jxys.dao.UsersPagingAndSortingRepository;
import cn.jxys.dao.UsersRepositoryByName;
import cn.jxys.dao.UsersRepositoryCrudRepository;
import cn.jxys.pojo.Users;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes=App.class)
public class UsersTest {
@Autowired
private UsersRepositoryByName usersRepositoryByName;
@Autowired
private UsersRepositoryCrudRepository usersRepositoryCrudRepository;
@Autowired
private UsersPagingAndSortingRepository usersPagingAndSortingRepository;
@Test
public void findByNameTest(){
List<Users> list=this.usersRepositoryByName.findByName("李健");
System.out.println(list.toString());
}
@Test//插入操作
public void crudRepository(){
Users user=new Users();
user.setAdress("中国");
user.setAge(18);
user.setName("赵四");
this.usersRepositoryCrudRepository.save(user);
}
@Test//修改操作
public void crudUpdataRepository(){
Users user=new Users();
user.setId(6);
user.setAdress("承德");
user.setAge(19);
user.setName("赵四");
this.usersRepositoryCrudRepository.save(user);
}
/**
* 排序测试
*/
@Test
public void testPagingAndSortingRepository(){
//Order 定义排序规则
//参数一:排序方式:Direction.DESC倒叙
//参数二:按照哪个字段来排序
Order order=new Order(Direction.DESC,"id");
//Sort对象封装了排序规则
Sort sort=new Sort(order);
List<Users> list=(List<Users>) this.usersPagingAndSortingRepository.findAll(sort);
for(Users user:list){
System.out.println(user.toString());
}
}
/**
* 分页测试
*/
@Test
public void testPagingAndSortingRepositoryPaging(){
//Pageable 封装了分页的参数,当前页,每页显示的条数,注意:它的当前页是从0开始的。
//PageRequest(0, 2) Page:当前页 。 size:每页显示的条数
Pageable pageable=new PageRequest(0, 2);
Page<Users> page=this.usersPagingAndSortingRepository.findAll(pageable);
System.out.println("总条数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
System.out.println("总...数:"+page.getNumberOfElements());
List<Users> list =page.getContent();
for(Users user:list){
System.out.println(user.toString());
}
}
/**
* 排序加分页测试
*/
@Test
public void testPagingAndSortingRepositoryPagingSort(){
//Order 定义排序规则
Order order=new Order(Direction.DESC,"id");
//Sort对象封装了排序规则
Sort sort=new Sort(order);
//Pageable 封装了分页的参数,当前页,每页显示的条数,注意:它的当前页是从0开始的。
//PageRequest(0, 2) Page:当前页 。 size:每页显示的条数
Pageable pageable=new PageRequest(0, 2, sort);
Page<Users> page=this.usersPagingAndSortingRepository.findAll(pageable);
System.out.println("总条数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
System.out.println("总...数:"+page.getNumberOfElements());
List<Users> list =page.getContent();
for(Users user:list){
System.out.println(user.toString());
}
}
}
这里我们添加了排序(testPagingAndSortingRepository())、分页(testPagingAndSortingRepositoryPaging())、排序加分页(testPagingAndSortingRepositoryPagingSort)这三个方法,这也是为了让大家看明白。具体里面有很多新东西但都很简单,我给大家写好了注释,大家应该可以看的明白。
运行排序(testPagingAndSortingRepository())方法:
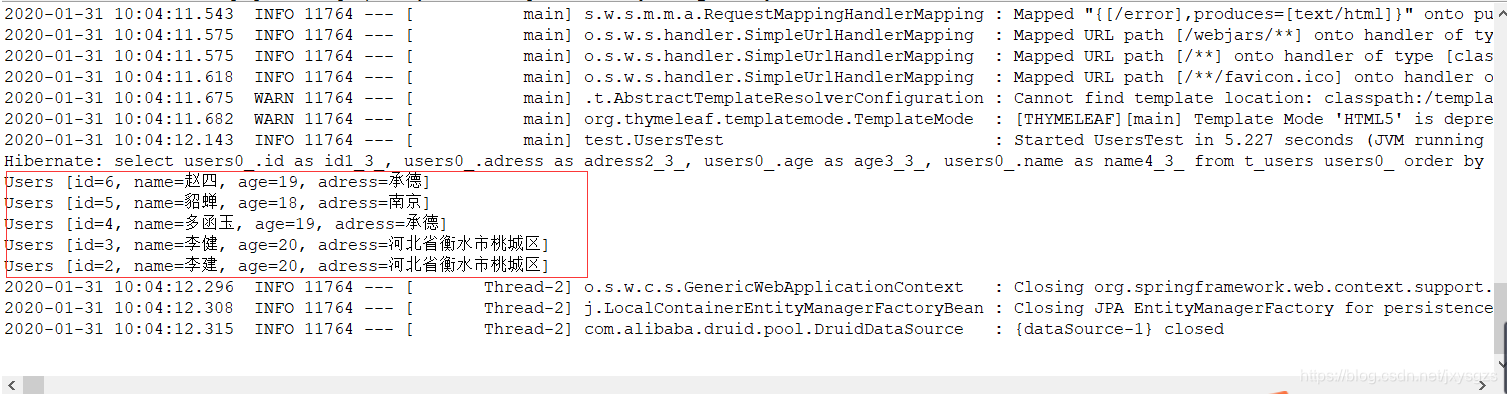
运行分页(testPagingAndSortingRepositoryPaging())方法:
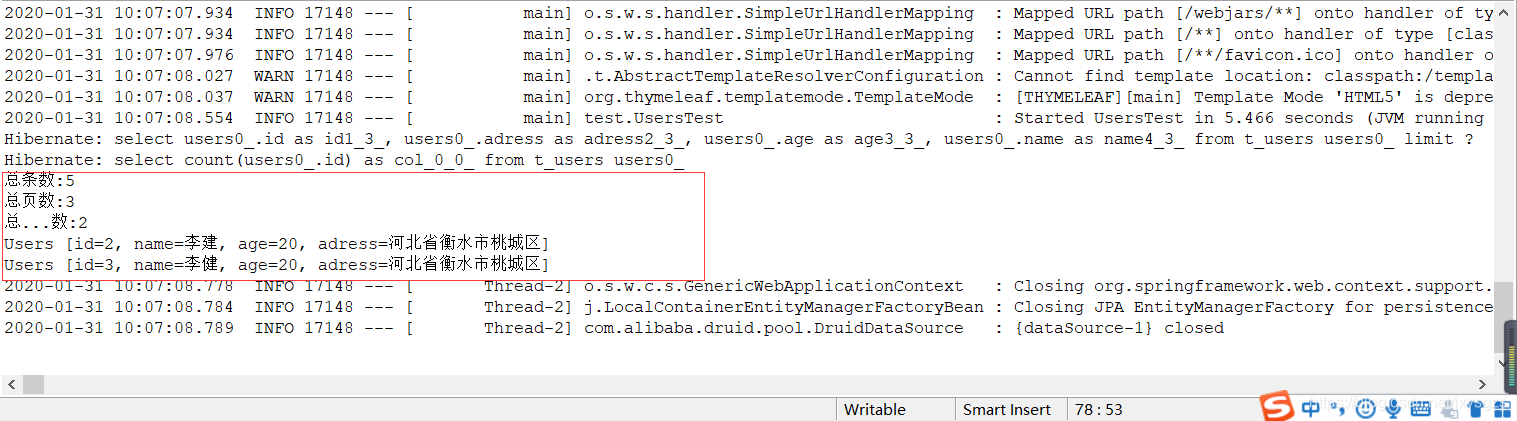
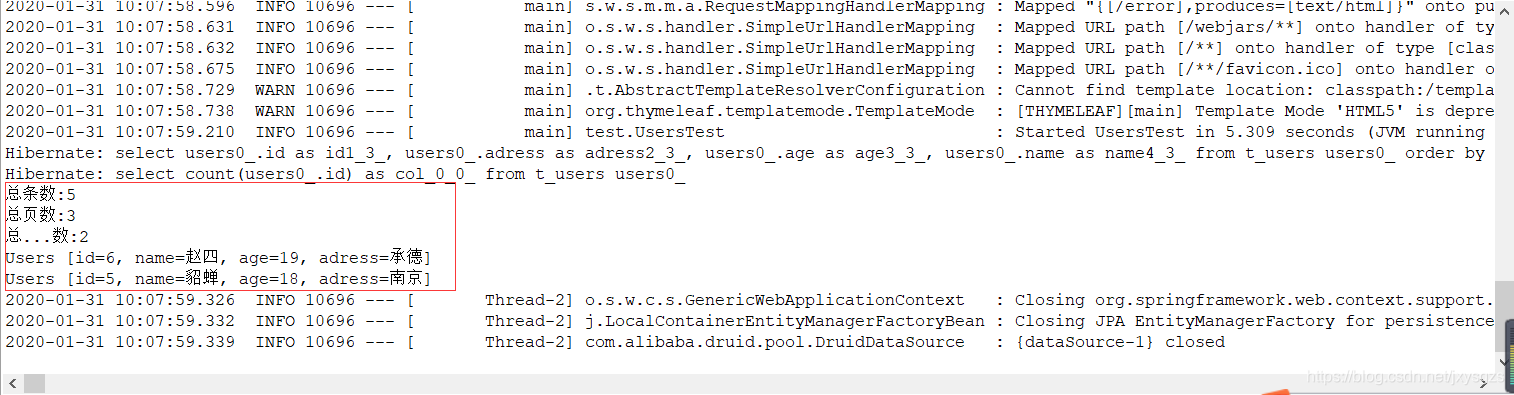
运行排序加分页(testPagingAndSortingRepositoryPagingSort)方法:
五、JpaRepository接口
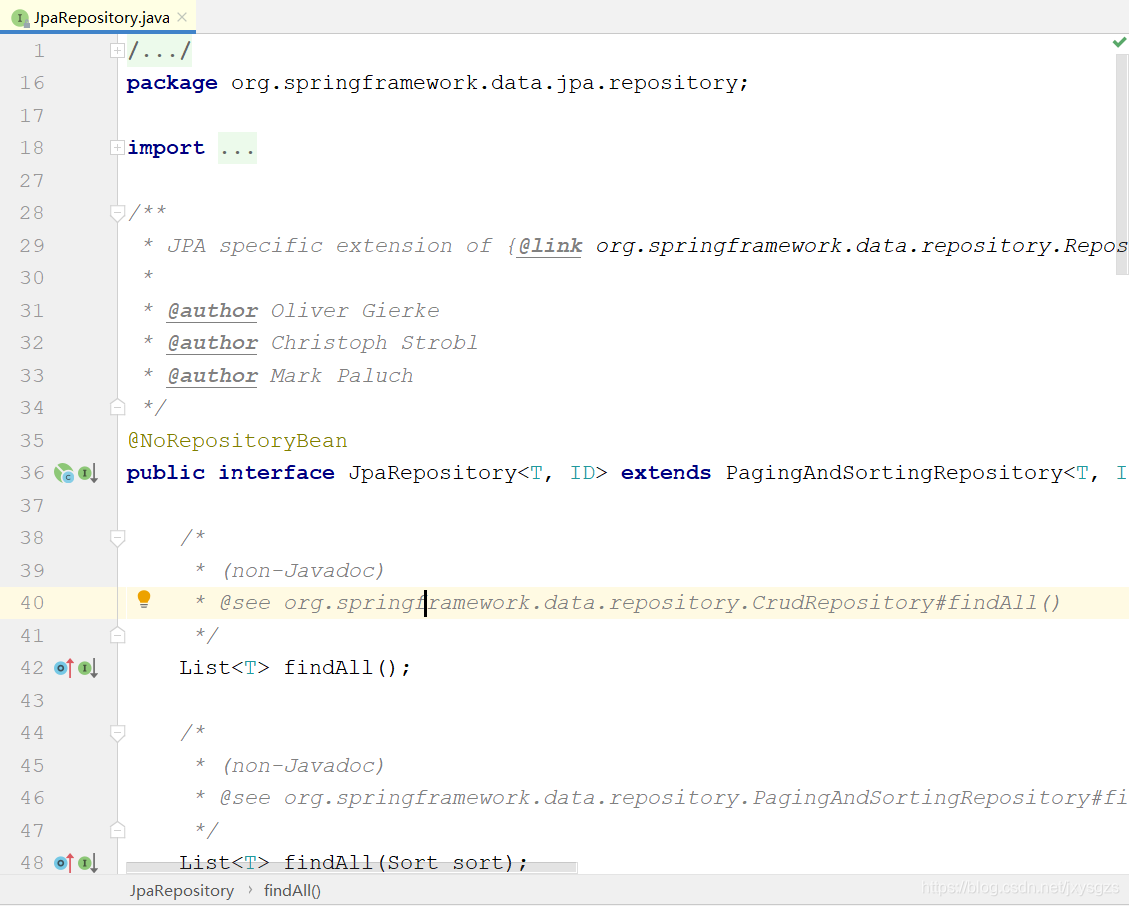
看到这个接口是不是有点熟悉,这个就是我们之前一直使用的JpaRepository。它是继承自PagingAndSortingRepository接口,拥有前面所有接口的功能,但是自己并没有提供太多有意义的功能,看情况使用即可,这里就暂时不写dome了。

如上图可见,这就是我们JpaRepository继承关系。我们平常使用直接使用JpaRepository即可,毕竟这个才是最全面最好用的。
五、JpaSpecificationExecutor接口
看完上面的JpaRepository继承关系,总感觉少点什么,没错,看似各种功能都齐全了,其实还少了一点点,那就按条件分页排序查询,上面讲到了分页排序,并不能按照指定条件进行查询,而JpaRepository接口中也没有新增这种方法,所以就有了JpaSpecificationExecutor接口。我们需要将JpaSpecificationExecutor接口于JpaRepository接口并行使用,即可完成单表的全部CURD操作。
/*
* Copyright 2008-2017 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.data.jpa.repository;
import java.util.List;
import java.util.Optional;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.lang.Nullable;
/**
* Interface to allow execution of {@link Specification}s based on the JPA criteria API.
*
* @author Oliver Gierke
* @author Christoph Strobl
*/
public interface JpaSpecificationExecutor<T> {
/**
* Returns a single entity matching the given {@link Specification} or {@link Optional#empty()} if none found.
*
* @param spec can be {@literal null}.
* @return never {@literal null}.
* @throws org.springframework.dao.IncorrectResultSizeDataAccessException if more than one entity found.
*/
Optional<T> findOne(@Nullable Specification<T> spec);
/**
* Returns all entities matching the given {@link Specification}.
*
* @param spec can be {@literal null}.
* @return never {@literal null}.
*/
List<T> findAll(@Nullable Specification<T> spec);
/**
* Returns a {@link Page} of entities matching the given {@link Specification}.
*
* @param spec can be {@literal null}.
* @param pageable must not be {@literal null}.
* @return never {@literal null}.
*/
Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);
/**
* Returns all entities matching the given {@link Specification} and {@link Sort}.
*
* @param spec can be {@literal null}.
* @param sort must not be {@literal null}.
* @return never {@literal null}.
*/
List<T> findAll(@Nullable Specification<T> spec, Sort sort);
/**
* Returns the number of instances that the given {@link Specification} will return.
*
* @param spec the {@link Specification} to count instances for. Can be {@literal null}.
* @return the number of instances.
*/
long count(@Nullable Specification<T> spec);
}
JpaSpecificationExecutor接口中只定义了这5个方法,但是恰恰是我们所需要的,具体的例子我暂时先不写了,比较主要是讲一下jpa的基本构成与继承关系。我会后面的篇幅中在我们之前的项目里为大家更清晰的讲解jpa的使用。
因为本教程是给新手看的,固我就先讲到这个深度,至于JPA的底层实现,启动原理,源码分析还是等大家日积月累在去看看吧。
