一、大型DMP系统设计思路
1. DMP系统的全称叫作数据管理平台(Data Management Platform),目前广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)等领域。通常来说DMP系统会通过处理海量的互联网访问数据以及机器学习算法,给一个用户标注上各种各样的标签。然后在做个性化推荐和广告投放的时候,再利用这些这些标签去做实际的广告排序、推荐等工作。无论是Google的搜索广告、淘宝里千人千面的商品信息,还是抖音里面的信息流推荐,背后都会有一个DMP系统。如下所示:

在一个DMP系统的搭建中,对于外部使用DMP的系统或者用户来说,可以简单地把DMP看成是一个键-值对(Key-Value)数据库。广告系统或者推荐系统可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息。这些信息中有些是用户的人口属性信息(Demographic),比如性别、年龄;有些是具体的行为(Behavior),比如用户最近看过的商品是什么,用户的手机型号是什么;有一些是通过算法系统计算出来的兴趣(Interests),比如用户喜欢健身、听音乐;还有一些则是完全通过机器学习算法得出的用户向量,给后面的推荐算法或者广告算法作为数据输入。
基于上面的特性,对于这个KV数据库,性能期望也很清楚,那就是:低响应时间(Low Response Time)、高可用性(High Availability)、高并发(High Concurrency)、海量数据(Big Data),同时需要付得起对应的成本(Affordable Cost)。如果用数字来衡量这些指标,那么这些期望就会具体化成下面这些要求:
(1)低响应时间:一般的广告系统留给整个广告投放决策的时间也就是10ms左右,所以对于访问DMP获取用户数据,预期的响应时间都在1ms之内。
(2)高可用性:DMP常常用在广告系统里面,DMP系统出问题往往就意味着整个的广告收入在不可用的时间就没了,所以对于可用性的追求可谓是没有上限的。
(3)高并发:以广告系统为例,如果每天需要响应100亿次的广告请求,那么每秒的并发请求数就在100亿/ (86400) ~= 12K次左右,所以DMP需要支持高并发。
(4)数据量:如果产品针对中国市场,那么需要有10亿个Key,对应的假设每个用户有500个标签,标签有对应的分数。标签和分数都用一个4字节(Bytes)的整数来表示,那么一共需要10亿×500×(4 + 4) Bytes = 400 TB的数据了。
(5)低成本:广告系统的收入通常用CPM(Cost Per Mille),也就是千次曝光来统计。如果千次曝光的利润是0.10,那么每天100亿次的曝光就是100万美元的利润。这个利润听起来非常高了,但是反过来算一下会发现,DMP每1000次请求的成本不能超过0.10。最好只有$0.01甚至更低,才能尽可能多赚到一点广告利润。
虽然从外部看起来,DMP 特别简单,就是一个 KV 数据库,但是生成这个数据库需要做的事情更多。为了能够生成这个KV数据库,需要有一个在客户端或者Web端的数据采集模块,不断采集用户的行为,向后端的服务器发送数据。服务器端接收到数据,就要把这份数据放到一个数据管道(Data Pipeline)里面。数据管道的下游,需要实际将数据落地到数据仓库(Data Warehouse),把所有的这些数据结构化地存储起来。后续就可以通过程序去分析这部分日志,生成报表或者或者利用数据运行各种机器学习算法。除了数据仓库之外,还会有一个实时数据处理模块(Realtime Data Processing),也放在数据管道的下游。它同样会读取数据管道里面的数据,去进行各种实时计算,然后把需要的结果写入到DMP的KV数据库里面去。如下所示:


2. 对于KV数据库、数据管道以及数据仓库这三个不同的数据存储的需求,技术方案并非可以全用MongoDB这一种数据库。它的优点虽然很多,例如不需要预先数据Schema,访问速度很快,能够无限水平扩展等,似乎作为KV数据库可以把MongoDB当作DMP里面的KV数据库;除此之外MongoDB 还能水平扩展跑MQL,可以把它当作数据仓库至于数据管道,只要能够不断往MongoDB里面插入新的数据就好了。从运维的角度来说,只需要维护一种数据库,技术栈也变得简单了。
看起来,MongoDB这个选择非常完美。但是,所有的软件系统都有它的适用场景,想通过一种解决方案适用三个差异非常大的应用场景,显然既不合理又不现实。对于数据管道来说需要的是高吞吐量,它的并发量虽然和KV数据库差不多,但是在响应时间上要求就没有那么严格,1-2秒甚至再多几秒的延时都是可以接受的。而且和KV数据库不太一样,数据管道的数据读写都是顺序读写,没有大量的随机读写的需求。
数据仓库就更不一样了,数据仓库的数据读取的量要比管道大得多。管道的数据读取就是当时写入的数据,例如一天有10TB日志数据,管道只会写入10TB。但是数据仓库的数据分析任务要读取的数据量就大多了。一方面可能要分析一周、一个月乃至一个季度的数据,这样一次分析要读取的数据可不只10TB,而是100TB乃至1PB。平台一天在数据仓库上跑的分析任务也不是1个,而是成千上万个,所以数据的读取量是巨大的。另一方面,存储在数据仓库里面的数据,也不像数据管道一样存放几个小时、最多一天的数据,而是往往要存上3个月甚至是1年的数据。所以,数据仓库需要的是1PB乃至5PB这样的存储空间。
KV 数据库、数据管道和数据仓库的应用场景比较如下所示,可以看到这三种场景都用MongoDB是不行的:

在KV数据库的场景下,需要支持高并发,那么MongoDB需要把更多的数据放在内存里面,但是这样存储成本就会特别高了。在数据管道的场景下,需要的是大量的顺序读写,而MongoDB则是一个文档数据库系统,并没有为顺序写入和吞吐量做过优化,看起来也不太适用。而在数据仓库的场景下,主要的数据读取是顺序读取,并且需要海量的存储,MongoDB这样的文档式数据库也没有为海量的顺序读做过优化,仍然不是一个最佳的解决方案,而且文档数据库里总是会有很多冗余的字段的元数据,还会浪费更多的存储空间。
因此,对于KV数据库,最佳的选择方案自然是使用SSD硬盘,选择AeroSpike或Cassandra这样的KV数据库。高并发的随机访问并不适合HDD的机械硬盘,而400TB的数据如果用内存的话,成本又会显得太高。
对于数据管道,最佳选择自然是Kafka。因为追求的是吞吐率,采用了Zero-Copy和DMA机制的Kafka最大化了作为数据管道的吞吐率。而且数据管道的读写都是顺序读写,所以也不需要对随机读写提供支持,用上HDD硬盘就好了。
到了数据仓库,存放的数据量更大了,在硬件层面使用HDD硬盘成了一个必选项,否则存储成本就会差上10倍。这么大量的数据在存储上需要定义清楚Schema,使得每个字段都不需要额外存储元数据,能够通过Avro/Thrift/ProtoBuffer这样的二进制序列化的方式存储下来,或者直接使用Hive这样明确了字段定义的数据仓库产品。很明显MongoDB那样不限制Schema的数据结构,在这个情况下并不好用。
3. 对于DMP系统中的数据库,如果现在自己写一个最简单的关系型数据库,最简单最直观的想法是用CSV文件格式,一个文件就是一个数据表,文件里面的每一行就是这个表里面的一条记录。如果要修改数据库里面的某一条记录,那么要先找到这一行,然后直接去修改这一行的数据,读取数据也是一样,要找到这样数据最笨的办法自然是一行行读,也就是遍历整个CSV文件。
不过这样的话,相当于随便读取任何一条数据都要扫描全表,太浪费硬盘的吞吐量了,可以试试给这个CSV文件加一个索引,比如给数据的行号加一个索引,在数据库原理或者算法和数据结构中,通过B+树多半是可以来建立这样一个索引的。索引里面没有一整行的数据,只有一个映射关系,这个映射关系可以让行号直接从硬盘的某个位置去读。所以索引比起数据小很多,可以把索引加载到内存里面,即使不在内存里面,要找数据的时候快速遍历一下整个索引,也不需要读太多的数据。
加了索引之后要读取特定的数据,就不用去扫描整个数据表文件了,直接从特定的硬盘位置就可以读到想要的行。索引不仅可以索引行号,还可以索引某个字段,可以创建很多个不同的独立的索引,写SQL的时候where子句后面的查询条件可以用到这些索引。不过这样的话,写入数据的时候就会麻烦一些,不仅要在数据表里面写入数据,对于所有的索引也都需要进行更新。这个时候,写入一条数据就要触发好几个随机写入的更新。如下所示:

在这样一个数据模型下,查询操作很灵活。无论是根据哪个字段查询,只要有索引就可以通过一次随机读,很快地读到对应的数据。但是这个灵活性也带来了一个很大的问题,那就是无论干点什么,都有大量的随机读写请求。而随机读写请求,如果请求最终是要落到HDD硬盘的话,就很难做到高并发了,毕竟HDD硬盘只有100左右的QPS。而这个随时添加索引,可以根据任意字段进行查询,这样的灵活性又是DMP系统里面不太需要的。DMP的KV数据库主要的应用场景,是根据主键的随机查询,不需要根据其他字段进行筛选查询。
数据管道的需求是只要不断追加写入和顺序读取就好了。即使进行数据分析的数据仓库,通常也不是根据字段进行数据筛选,而是全量扫描数据进行分析汇总。后面的两个场景大不让程序去扫描全表或者追加写入,但是在KV数据库上,上面这个最简单的关系型数据库的设计,就会面临大量的随机写入和随机读取的挑战。所以在实际的大型系统中,大家都会使用专门的分布式KV数据库来满足这个需求。
4. 作为一个分布式的KV数据库,Cassandra的键一般被称为Row Key。其实就是一个16到36个字节的字符串。每一个Row Key对应的值其实是一个哈希表,里面可以用键值对再存入很多需要的数据。Cassandra本身不像关系型数据库那样有严格的Schema,在数据库创建的一开始就定义好了有哪些列(Column)。但是它设计了一个叫作列族(Column Family,HBase中也有)的概念,把需要经常放在一起使用的字段放在同一个列族里面。比如DMP里面的人口属性信息,可以把它当成是一个列族;用户的兴趣信息可以是另外一个列族。
这样既保持了不需要严格的Schema这样的灵活性,也保留了可以把常常一起使用的数据存放在一起的空间局部性。往Cassandra的里面读写数据其实特别简单,就好像是在一个巨大的分布式的哈希表里面写数据。指定一个Row Key,然后插入或者更新这个Row Key的数据就好了。
Cassandra解决随机写入数据的解决方案,简单来说叫作“不随机写,只顺序写”。对Cassandra 数据库的写操作通常包含两个动作:
(1)往磁盘上写入一条提交日志(Commit Log)。
(2)直接在内存的数据结构上去更新数据。后面这个在内存的数据结构里面的数据更新,只有在提交日志写成功之后才会进行。写入提交日志都是顺序写(Sequential Write),而不是随机写(Random Write),这样最大化了写入的吞吐量。如下所示:

内存的空间比较有限,一旦内存里面的数据量或者条目超过一定的限额,Cassandra就会把内存里面的数据结构dump到硬盘上,这个Dump的操作也是顺序写而不是随机写。除了Dump的数据结构文件,Cassandra还会根据row key来生成一个索引文件,方便后续基于索引来进行快速查询。随着硬盘上的Dump出来的文件越来越多,Cassandra会在后台进行文件的对比合并,在很多别的KV数据库系统里面也有类似这种的合并动作,比如AeroSpike或者Google的BigTable,这些操作一般称之为Compaction。合并动作同样是顺序读取多个文件,在内存里面合并完成,再Dump出一个新的文件,整个操作过程中在硬盘层面仍然是顺序读写。
当要从Cassandra读数据的时候,会从内存里面找数据再从硬盘读数据,然后把两部分的数据合并成最终结果。这些硬盘上的文件,在内存里面会有对应的Cache,只有在Cache里面找不到,才会去请求硬盘里面的数据。如果不得不访问硬盘,因为硬盘里面可能Dump了很多个不同时间点的内存数据的快照,所以找数据的时候也是按照时间从新的往旧的里面找。
这就带来另外一个问题,可能要查询很多个Dump文件,才能找到想要的数据。所以Cassandra在这一点上又做了一个优化,那就是它会为每一个Dump的文件里面所有Row Key生成一个BloomFilter,然后把这个BloomFilter放在内存里面。这样如果想要查询的Row Key在数据文件里面不存在,那么99%以上的情况下它会被内存里的BloomFilter过滤掉,而不需要访问硬盘。这样只有当数据在内存里面没有,并且在硬盘的某个特定文件上的时候,才会触发一次对于硬盘的读请求。如下所示:
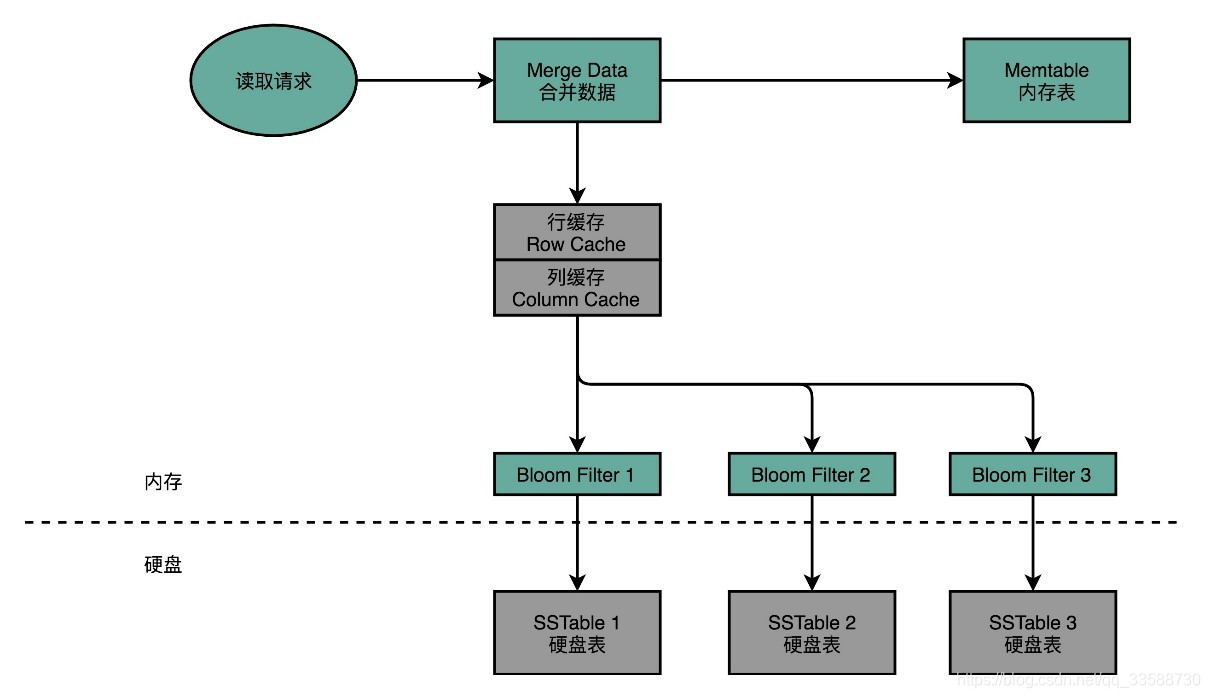
5. Cassandra的读写设计充分考虑了硬件本身的特性。在写入数据进行持久化上,Cassandra没有任何的随机写请求,无论是Commit Log还是Dump全部都是顺序写。在数据读的请求上,最新写入的数据都会更新到内存,如果要读取这些数据会优先从内存读到,这相当于是使用了LRU的缓存机制。只有在万般无奈的情况下,才会有对于硬盘的随机读请求。即使在这样的情况下,Cassandra也在文件之前加了一层BloomFilter,把本来因为Dump文件带来的需要多次读硬盘的问题,简化成多次内存读和一次硬盘读。
这些设计使得Cassandra即使是在HDD硬盘上,也能有不错的访问性能。因为所有的写入都是顺序写或者写入到内存,所以写入可以做到高并发。HDD硬盘的吞吐率还是不错的,每秒可以写入100MB以上的数据,如果一条数据只有1KB,那么10万的WPS(Writes per seconds)也是能够做到的。这足够支撑DMP期望的写入压力了。而对于数据的读就有一些挑战了。如果数据读请求有很强的局部性,那内存就能搞定DMP需要的访问量,但是问题就出在局部性上,DMP的数据访问分布其实是缺少局部性的。DMP里面的Row Key都是用户的唯一标识符,普通用户的上网时刻和时长并没有局部性,不能把某些用户的数据放在内存里面,其他用户的不放。
因为缺少了时间局部性,内存的缓存能够起到的作用就很小了,大部分请求最终还是要落到HDD硬盘的随机读上。但是HDD硬盘的随机读性能太差了,也就是100QPS左右,而如果全都放内存那就太贵了,成本在HDD硬盘100倍以上。而SSD的出现缓解了这个问题,它的价格在HDD硬盘的10倍,但是随机读的访问能力在HDD硬盘的百倍以上。同样的价格的SSD硬盘容量则是内存的几十倍,能够用较低的成本存下互联网用户信息。不夸张地说,过去十年的大数据、高并发、千人千面,有一半的功劳应该归在让SSD容量不断上升、价格不断下降的硬盘产业上。
而Cassandra的写入机制完美匹配了SSD硬盘的优缺点。在数据写入层面,Cassandra的数据写入都是Commit Log的顺序写入,也就是不断地在硬盘上往后追加内容,而不是去修改现有的文件内容。一旦内存里面的数据超过一定的阈值,Cassandra又会完整地Dump一个新文件到文件系统上,这同样是一个追加写入。数据的对比和紧凑化(Compaction),同样是读取现有的多个文件然后写一个新的文件出来。写入操作只追加不修改的特性,正好天然地符合SSD硬盘只能按块进行擦除写入的操作。在这样的写入模式下,Cassandra用到的SSD硬盘,不需要频繁地进行后台的Compaction,能够最大化SSD硬盘的使用寿命。这也是为什么Cassandra在SSD硬盘普及之后,能够获得进一步快速发展。
二、Disruptor高性能思想
6. 最在意极限性能的并不是互联网公司,而是高频交易公司。Disruptor就是由一家专门做高频交易的公司LMAX开源出来的。有意思的是Disruptor的开发语言并不是很多人心目中最容易做到性能极限的C/C++,而是性能受限于JVM的Java。其实只要通晓硬件层面的原理,即使是像Java这样的高级语言,也能够把CPU的性能发挥到极限。例如下面的代码,Disruptor在RingBufferPad这个类里面定义了p1,p2一直到p7这样7个long类型的变量:
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
在看到这段代码的第一反应是,变量名取得不规范,p1-p7这样的变量名没有明确的意义。但其实这些变量名取得恰如其分,因为这些变量就是没有实际意义,只是帮助进行缓存行填充(Padding Cache Line),使得能够尽可能地用上CPU高速缓存(CPU Cache)。内存的访问速度其实是远远慢于CPU的,想要追求极限性能,需要尽可能地多从CPU Cache里面拿数据,而不是从内存里面拿数据。
CPU Cache装载内存里面的数不是一个个字段加载的,而是加载一整个缓存行。例如如果定义了一个长度为64的long类型的数组,那么数据从内存加载到CPU Cache里面的时候,不是一个个数组元素加载的,而是一次性加载固定长度的一个缓存行。现在64位Intel CPU的计算机缓存行通常是64个字节(Bytes)。一个long类型的数据需要8个字节,所以一下子会加载8个long类型的数据,也就是说一次加载数组里面连续的8个数值,这样的加载方式使得遍历数组元素的时候会很快,因为后面连续7次的数据访问都会命中缓存,不需要重新从内存里面去读取数据。
但是,在不使用数组而是使用单独的变量的时候,这里就会出现问题了。在Disruptor的RingBuffer(环形缓冲区)的代码里面,定义了一个RingBufferFields类,里面有indexMask和其他几个变量,用来存放RingBuffer的内部状态信息。如下所示:
......
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad
{
......
private final long indexMask;
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
......
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
......
protected long p1, p2, p3, p4, p5, p6, p7;
......
}
CPU在加载数据的时候,自然也会把这个数据从内存加载到高速缓存里面来。不过这个时候,高速缓存里面除了这个数据,还会加载这个数据前后定义的其他变量,这个时候问题就来了,Disruptor是一个多线程的服务器框架,在这个数据前后定义的其他变量可能会被多个不同的线程去更新数据、读取数据,这些写入以及读取的请求会来自于不同的CPU Core。于是为了保证数据的同步更新,不得不把CPU Cache里面的数据重新写回到内存里面去,或者重新从内存里面加载数据。如下所示:

这些CPU Cache的写回和加载都不是以一个变量作为单位的,这些动作都是以整个Cache Line作为单位的。所以,当INITIAL_CURSOR_VALUE前后的那些变量被写回到内存的时候,这个字段自己也写回到了内存,这个常量的缓存也就失效了。当要再次读取这个值的时候,要再重新从内存读取,这也就意味着读取速度大大变慢了。
面临这样一个情况,Disruptor里发明了一个神奇的代码技巧,就是缓存行填充。Disruptor在RingBufferFields里面定义的变量的前后,分别定义了7个long类型的变量。前面的7个来自继承的RingBufferPad类,后面的7个则是直接定义在RingBuffer类里面。这14个变量没有任何实际的用途,既不会去读他们,也不会去写他们。而RingBufferFields里面定义的这些变量都是final的,第一次写入之后不会再进行修改。所以一旦它被加载到CPU Cache之后,只要被频繁地读取访问,就不会再被换出Cache了。这也就意味着,对于这个值的读取速度,会一直是CPU Cache的访问速度,而不是内存的访问速度。如下所示:

本来对于类里面定义的单独变量,不容易享受到CPU Cache的速度,因为这些字段虽然在内存层面会分配到一起,但是实际应用的时候往往没有什么关联。于是就会出现多个CPU Core访问的情况下,数据频繁在CPU Cache和内存里面来来回回的情况。而Disruptor很取巧地在需要频繁高速访问的变量,也就是RingBufferFields里的indexMask这些字段前后,各定义了7个没有任何作用和读写请求的long类型的变量。这样无论在内存的什么位置上,这些变量所在的Cache Line都不会有任何写更新的请求,就可以始终在Cache Line里面读到indexMark等字段的值,而不需要从内存里面去读取数据,也就大大加速了Disruptor的性能。
7. 有点类似于Kafka,Disruptor整个框架其实就是一个高速的生产者-消费者模型(Producer-Consumer)下的队列。生产者不停地往队列里面生产新的需要处理的任务,而消费者不停地从队列里面处理掉这些任务。如下所示:

如果要实现一个队列,最合适的数据结构应该是链表。只要维护好链表的头和尾,就能很容易实现一个队列。生产者只要不断地往链表的尾部不断插入新的节点,而消费者只需要不断从头部取出最老的节点进行处理就好了。实际上,Java自己的基础库里面就有LinkedBlockingQueue这样的队列库,可以直接用在生产者-消费者模式上。如下所示:

不过,Disruptor里面并没有用LinkedBlockingQueue,而是使用了一个RingBuffer这样的数据结构,这个RingBuffer的底层实现则是一个固定长度的数组。比起链表形式的实现,数组的数据在内存里面会存在空间局部性,数组的连续多个元素会一并加载到CPU Cache里面来,所以访问遍历的速度会更快。而链表里面各个节点的数据,多半不会出现在相邻的内存空间,自然也就享受不到整个Cache Line加载后数据连续从高速缓存里面被访问到的优势。除此之外,数据的遍历访问还有一个很大的优势,就是CPU层面的分支预测会很准确。这可以更有效利用CPU里的多级流水线,程序就会跑得更快。
8. 利用CPU高速缓存只是Disruptor快的一个因素,另一个因素就是“无锁”,即尽可能发挥CPU本身的高速处理性能。Disruptor作为一个高性能的生产者-消费者队列系统,一个核心的设计就是通过RingBuffer实现一个无锁队列。Java里面的基础库里有像LinkedBlockingQueue这样的队列库,但是这个队列库比起Disruptor里用的RingBuffer要慢上很多。慢的第一个原因是因为链表的数据在内存里面的布局对于高速缓存并不友好,而RingBuffer所使用的数组则不然。如下所示:

LinkedBlockingQueue慢,有另外一个重要的因素,那就是它对于锁的依赖。在生产者-消费者模式里,可能有多个消费者与多个生产者。多个生产者都要往队列的尾指针里面添加新的任务,就会产生多个线程的竞争,于是生产者就需要拿到对于队列尾部的锁。同样在多个消费者去消费队列头的时候,也会产生竞争,同样消费者也要拿到锁。只有一个生产者或者一个消费者,也依然还是有锁竞争的问题。
一般来说,在生产者-消费者模式下,消费者要比生产者快,不然的话队列会产生积压,队列里面的任务会越堆越多。一方面越来越多的任务没有能够及时完成;另一方面内存也会放不下。虽然生产者-消费者模型下都有一个队列来作为缓冲区,但是大部分情况下这个缓冲区里面是空的。也就是说即使只有一个生产者和一个消费者,这个生产者指向的队列尾和消费者指向的队列头是同一个节点,于是这两个生产者和消费者之间一样会产生锁竞争。
在LinkedBlockingQueue上,这个锁机制是通过ReentrantLock这个Java基础库来实现的。这个锁是一个用Java在JVM上直接实现的加锁机制,这个锁机制需要由JVM来进行裁决。这个锁的争夺,会把没有拿到锁的线程挂起等待,也就需要经过一次上下文切换(Context Switch),这里上下文切换要做的和CPU异常和中断里的是一样的。上下文切换的过程,需要把当前执行线程的寄存器等信息保存到线程栈里面,而这个过程也意味着,已经加载到高速缓存里的指令或数据又回到了主内存里面,会进一步拖慢性能。例如下面的代码,把一个long类型的counter从0自增到5亿,一种方式是没有任何锁,另外一个方式是每次自增的时候都要去取一个锁。如下所示:
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockBenchmark{
public static void runIncrement()
{
long counter = 0;
long max = 500000000L;
long start = System.currentTimeMillis();
while (counter < max) {
counter++;
}
long end = System.currentTimeMillis();
System.out.println("Time spent is " + (end-start) + "ms without lock");
}
public static void runIncrementWithLock()
{
Lock lock = new ReentrantLock();
long counter = 0;
long max = 500000000L;
long start = System.currentTimeMillis();
while (counter < max) {
if (lock.tryLock()){
counter++;
lock.unlock();
}
}
long end = System.currentTimeMillis();
System.out.println("Time spent is " + (end-start) + "ms with lock");
}
public static void main(String[] args) {
runIncrement();
runIncrementWithLock();
}
}
两个方式执行所需要的时间分别是207毫秒和9603毫秒,性能差出了将近50倍。结果如下所示:
Time spent is 207ms without lock
Time spent is 9603ms with lock
9. 加锁很慢,所以Disruptor的解决方案就是“无锁”,这个“无锁”指的是没有操作系统层面的锁。实际上Disruptor还是利用了一个CPU硬件支持的指令称之为CAS(Compare And Swap,比较和交换),在Intel CPU里这个对应的指令就是cmpxchg。Disruptor中的RingBuffer实现和直接在链表的头和尾加锁不同,它创建了一个Sequence对象,用来指向当前的RingBuffer的头和尾。这个头和尾的标识不是通过一个指针来实现的,而是通过一个序号,这也是为什么对应源码里面的类名叫Sequence。如下所示:

在这个RingBuffer当中,进行生产者和消费者之间的资源协调,采用的是对比序号的方式。当生产者想要往队列里加入新数据的时候,它会把当前的生产者的Sequence序号,加上需要加入的新数据的数量,然后和实际的消费者所在的位置进行对比,看看队列里是不是有足够的空间加入这些数据,而不会覆盖掉消费者还没有处理完的数据。在Sequence的代码里面,就是通过compareAndSet这个方法,并且最终调用到了UNSAFE.compareAndSwapLong,也就是直接使用了CAS指令。如下所示:
public boolean compareAndSet(final long expectedValue, final long newValue)
{
return UNSAFE.compareAndSwapLong(this, VALUE_OFFSET, expectedValue, newValue);
}
public long addAndGet(final long increment)
{
long currentValue;
long newValue;
do
{
currentValue = get();
newValue = currentValue + increment;
}
while (!compareAndSet(currentValue, newValue));
return newValue;
}
这个CAS指令,也就是比较和交换的操作,并不是基础库里的一个函数,也不是操作系统里面实现的一个系统调用,而是一个CPU硬件支持的机器指令,就是Intel CPU上的cmpxchg这个指令。如下所示:
compxchg [ax] (隐式参数,EAX累加器), [bx] (源操作数地址), [cx] (目标操作数地址)cmpxchg指令一共有三个操作数,第一个操作数不在指令里面出现,是一个隐式的操作数,也就是EAX累加寄存器里面的值。第二个操作数就是源操作数,并且指令会对比这个操作数和上面的累加寄存器里面的值,如果值是相同的,那CPU会把ZF(也就是条件码寄存器里面零标志位的值)设置为1,然后再把第三个操作数(也就是目标操作数)设置到源操作数的地址上;如果不相等的话,就会把源操作数里面的值设置到累加器寄存器里面。这个过程的伪代码如下所示:
IF [ax]< == [bx] THEN [ZF] = 1, [bx] = [cx]
ELSE [ZF] = 0, [ax] = [bx]
单个指令是原子的,这也就意味着在使用CAS操作的时候不再需要单独进行加锁,直接调用就可以了。没有了锁CPU这部高速跑车就像在赛道上行驶,不会遇到需要上下文切换这样的红灯而停下来,虽然会遇到像CAS这样复杂的机器指令,就好像赛道上会有U型弯一样,不过不用完全停下来等待,CPU运行起来仍然会快很多。证明CAS操作速度快的代码如下所示:
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockBenchmark {
public static void runIncrementAtomic()
{
AtomicLong counter = new AtomicLong(0);
long max = 500000000L;
long start = System.currentTimeMillis();
while (counter.incrementAndGet() < max) {
}
long end = System.currentTimeMillis();
System.out.println("Time spent is " + (end-start) + "ms with cas");
}
public static void main(String[] args) {
runIncrementAtomic();
}
}
运行结果如下所示:
Time spent is 3867ms with cas和上面其他代码的counter自增一样,只不过这一次自增采用了AtomicLong这个Java类,里面的incrementAndGet最终到了CPU指令层面,在实现的时候用的就是CAS操作。可以看到它所花费的时间,虽然要比没有任何锁的操作慢上一个数量级,但是比起使用ReentrantLock这样的操作系统锁的机制,还是减少了一半以上的时间。通过CAS这样的操作,去进行序号的自增和对比,使CPU不需要获取操作系统的锁,而是能够继续顺序地执行CPU指令。没有上下文切换、没有操作系统锁,自然程序就跑得快了。不过因为采用了CAS这样忙等待(Busy-Wait)的方式,会使得CPU始终满负荷运转。
