《流畅的Python》学习笔记(3) —— 序列的骚操作
看了《流畅的Python》第二章,总体感觉很杂乱,好像什么技巧都说,尽力整理,如有不对的地方以后在修改。
1. 序列的总类
在Python中,有许多是序列构成的数据类型,不单是有list类型,只要满足线性表的定义的都是由现成的数据类型可用的。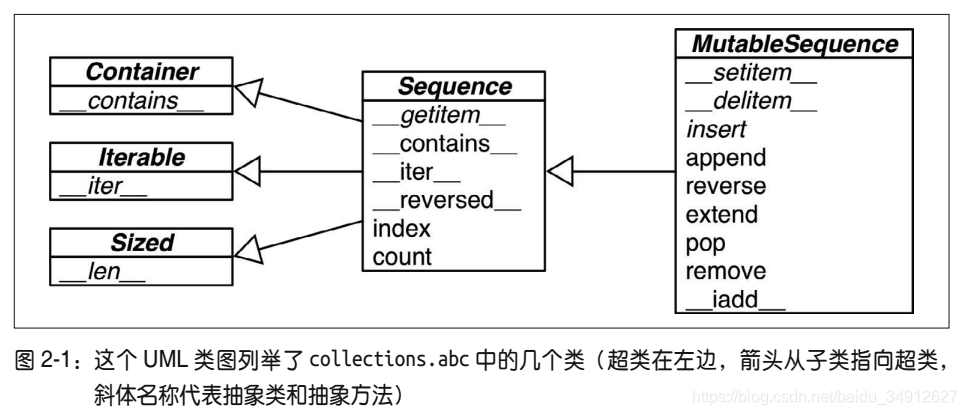
一个序列的数据类继承了迭代器、容器、大小三个基类的,这是类内共有的一些特征。
由于是进阶课程,相信大家对列表的基本使用比较熟悉,所以接下来直接从列表推导和生成器表达式开始
2. 列表推导和生成器表达式
列表推导方法是构建列表的快速方法,而生成器表达式可以用来创造任何类型的序列,包括list,所以他们的功能应该是一个包含的关系。
具体的格式为:
data = [func(item) for ...in ...]
2.1 列表推导
(1)列表推导的好处
经常使用列表推导的好处可以通过比较下面两串代码了解
代码一:
>>> symbols = '$¢£¥€¤'
>>> codes = []
>>> for symbol in symbols:
... codes.append(ord(symbol))
...
>>> codes
[36, 162, 163, 165, 8364, 164]
代码二:
>>> symbols = '$¢£¥€¤'
>>> codes = [ord(symbol) for symbol in symbols]
>>> codes
[36, 162, 163, 165, 8364, 164]
两串代码比较
- 长度:代码一比较长,为三行,而代码二仅一行
- 易读性角度:代码二仅通过一行就能表达三行的内容,简洁明了
值得注意的是:当列表推导的代码超过两行,需要考虑是否用for循环重写
(2)列表推导的几个功能
替代filter和map的功能
>>> symbols = '$¢£¥€¤'
>>> beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
>>> beyond_ascii
[162, 163, 165, 8364, 164]
>>> beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
>>> beyond_ascii
[162, 163, 165, 8364, 164]
笛卡尔积(常用于状态初始化)
积
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> tshirts = [(color, size) for color in colors for size in sizes] ➊
>>> tshirts
[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'),
('white', 'M'), ('white', 'L')]
>>> for color in colors: ➋
... for size in sizes:
... print((color, size))
...
('black', 'S')
('black', 'M')
('black', 'L')
('white', 'S')
('white', 'M')
('white', 'L')
>>> tshirts = [(color, size) for size in sizes ➌
... for color in colors]
>>> tshirts
[('black', 'S'), ('white', 'S'), ('black', 'M'), ('white', 'M'),
('black', 'L'), ('white', 'L')]
2.2 生成器表达式
生成器表达式也常常用于初始化元组、数组或其他类型,而且相比于生成器表达式回事更好的选择,因为它有迭代器方法,可以逐个产生元素。具体格式为
data = (func(item) for item in ...)
与列表推导只在括号有 ‘[ ]’ 变为 '( )'
生成器详细的描述将会在笔记15中。
3. 元组——不仅仅是不可变列表
在一些入门教程中元组称为“不可变列表”,但作者提出了另外一种观点:
用于没有字段名的数据记录
>>> lax_coordinates = (33.9425, -118.408056)
>>> city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014)
>>> traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'),
... ('ESP', 'XDA205856')]
>>> for passport in sorted(traveler_ids):
... print('%s/%s' % passport)
...
BRA/CE342567
ESP/XDA205856
USA/31195855
>>> for country, _ in traveler_ids:
... print(country)
...
USA
BRA
ESP
用作记录的也和拆包这个Python独有的特性息息相关
所谓拆包就是就是把序列每个元素分配到各个新变量中,例如
>>>data = [1, 2, 3]
>>>a, b, c = data
>>>a
1
>>>b
2
>>>c
3
4. 切片(Slides)
4.1切片为什么带前不带后
根本原因是序列都是从0开始的
- 当只有最后一个位置信息时,可以快速看出切片中有几个元素
- 起止位置都可知道时,可以直接用后一个数减去前一个数进行求解切片长度(stop - start)
- 可以把序列切为两个部分
4.2 切片的几个功能
- 对切片赋值
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[2:5] = [20, 30]
>>> l
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del l[5:7]
>>> l
[0, 1, 20, 30, 5, 8, 9]
>>> l[3::2] = [11, 22]
>>> l
[0, 1, 20, 11, 5, 22, 9]
>>> l[2:5] = 100 ➊
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only assign an iterable
>>> l[2:5] = [100]
>>> l
[0, 1, 100, 22, 9]
这一特性在numpy这个常用的数据分析库中使用的很多
可以猜测内部实现可能是通过C语言循环操作
5 内置排序sorted函数和序列排序
这两个排序笔者以前常分不清具体用法,总是认为C++的排序函数灵活性好,但实际上是我们有掌握python的排序方法
5.1 sorted
sorted是python的内置函数,可以排序一些序列类型的数据结构。
这里重点阐述如何使用key这个参数进行排列:
Python的排序不类似C++需要手动写一个返回布尔值的比较函数,而是需要手写一个返回一个比较关键字(key)的函数,最终排序就通过这个关键字进行排序。也就是说把序列的顺序映射到一维数轴上进行排序。比如字典顺序可以用26进制数进行表示,然后对这个26进制数进行大小排序就获得了字典序,这样的好处,笔者认为有:
- 减少设置bool值出现错误的机会
- 用单一值排序速度很快
- 方便编写排序程序
值得注意的是sorted返回的是一个占用新的内存空间的引用变量,不是原地进行排序
5.2 list.sort()
list.sort()与sorted相比是原地排序的,不会产生额外的空间,顺便一提,所有排序都是稳定。
