文章目录
- 博客说明:
- 基础知识
- 001.Hello,World
- 002.CircularStatement
- 003.ConditionalStatement
- 004.range
- 005.lambda
- 006.random
- 007.time
- 008.re
- raw string 原生字符串
- re.match(pattern, string, flags=0)
- 强化理解一:贪心模式与懒惰模式
- 强化理解二:实例补充
- 视野拓展:查看官方的开发文档
- re.search(pattern, string, flags=0)
- re.sub(pattern, repl, string, count=0, flags=0)
- re.subn(pattern, repl, string, count=0, flags=0)
- re.compile(pattern[, flags])
- re.escape(string)
- findall(pattern, string, flags=0)
- 强化理解之优先级问题
- re.finditer(pattern, string, flags=0)
- re.split(pattern, string[, maxsplit=0, flags=0])
- re模式
- 贪婪模式与惰性匹配
- group(s)
- 常见字符类
- 正则表达的常见应用(模型)
- 009.(not) in
- 010.is
- 011.stack
- 012.queue
- 013.列表生成式
- 014.package
- 015.搜索算法
- 016.最短路径
- 017.矩阵
- 018.排序
- 019.查找
- 020.eval
- 021.待定
- 模板代码
- 项目实战
博客说明:
只是一些python语言的基础应用及其技巧,不断更新、记录,并制作对应目录、索引。
目标是1000例,不断更新补全,如有需要可提前说明相关知识点。
基础知识
001.Hello,World
print "Hello,World!"
print "Hi,Python2!"
print ("Hello,World!")
print ("Hi,Python3!")
# python2.7可以输出python3版本,但反过来不行
Python2.7能够正常输出py2、py3
Python3.7无法正常输出py2,版本不兼容
002.CircularStatement
for i in range(10):
print(i,"Hello,For Circular.")
简单for循环之range示范
# 列表单、双引号都可以使用
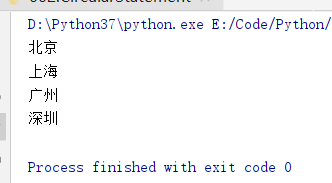
cities = ['北京','上海',"广州","深圳"]
for eachCity in cities:
print (eachCity)
简单for循环之输出列表
# 直接通过迭代器遍历元素
py = "python"
for character in py:
print(character)
print()#默认会输出空行
# 通过列表的索引遍历元素
for i in range(len(py)):
print(i,py[i])
print("\nlen(py)=",len(py))
简单for循环之字符串
# 简单foreach循环,需要Python3
def foreach(function, iterator):
for item in iterator:
function(item)
return
def printItself(it):
print(it,end=" ")
return
# 在这里,试着比较直接使用print与使用printItself的效果
my_tuple = (1, 2, 3, [4, 5], 6)
my_dictionary = {"Apple": "Red",
"Banana": "Yellow",
"Pear": "Green"
}
foreach(printItself, my_tuple)
# 1 2 3 [4, 5] 6 #注释行为对应的输出结果,下同
print()
foreach(print, my_tuple)
# 1
# 2
# 3
# [4, 5]
# 6
foreach(print, range(len(my_tuple)))
# 0
# 1
# 2
# 3
# 4
print()
foreach(print, my_dictionary)
foreach(print, my_dictionary.keys())
# 上二个语句等价,输出相同
# Apple
# Banana
# Pear
foreach(print, my_dictionary.values())
# Red
# Yellow
# Green
print()
print(my_dictionary)
# {'Apple': 'Red', 'Banana': 'Yellow', 'Pear': 'Green'}
print(my_dictionary.keys())
# dict_keys(['Apple', 'Banana', 'Pear'])
print(my_dictionary.values())
# dict_values(['Red', 'Yellow', 'Green'])
print()
foreach(printItself, range(len(my_dictionary)))
# 0 1 2
print()
foreach(printItself,my_dictionary.keys())
# Apple Banana Pear
print()
foreach(printItself,my_dictionary.values())
# Red Yellow Green
print("\n")
foreach(print,my_dictionary)
print()
foreach(print,my_dictionary.keys())
# 上二个语句等价,输出相同
# Apple
# Banana
# Pear
print()
foreach(print,my_dictionary.values())
# Red
# Yellow
# Green
print()
for item in my_dictionary.items():
print(item)
# ('Apple', 'Red')
# ('Banana', 'Yellow')
# ('Pear', 'Green')
for it in my_dictionary:
print(it,":",my_dictionary[it])
# Apple: Red
# Banana: Yellow
# Pear: Green
# 值得说明的是:dict[key]=value(讲究与之对应),当key值为数值时还可以采用以下途径
for i in range(len(my_dictionary)):
print(i)
# print(my_dictionary[i])#key值不是数值时,找不到对应项会报错
# 0
# 1
# 2
自定义foreach循环之输出元祖
自定义foreach循环之输出字典
003.ConditionalStatement
# -*- coding: UTF-8 -*-
# python 数组用法
# array.array(typecode,[initializer])
# --typecode:元素类型代码;
# initializer:初始化器,若数组为空,则省略初始化器
import array
num = array.array('H',[1]*21)
# print("len(num)=",len(num))
# print(num)
len = len(num)
for i in range(len):
if 0==i or i==1:
num[i] = 0
continue
j = i
while i*j<len:
if(num[j*i]):
num[j*i] = 0
j+=1
# for i in range(len):
# print(i,num[i])
# print(num)
# 以上实现的是一个简单的质数筛法,PrimeNumber
for i in range(len):
if i<2:
print(i,"既不是质数,也不是偶数。")
elif num[i] and i%2:
print(i,"是质数,且是奇质数")
elif num[i] and 0==i%2:
print(i, "是质数,且是偶质数")
elif not(num[i]) and not(i%2):
print(i, "非质数,且是偶数")
else: # not(num[i]) and (i%2)
print(i, "非质数,且是奇数")
条件语句,以及质数筛法
while i*j<len:
statement
该语句完全可以换成另外一种写法(殊途同归)
while True:
statement
if i*j>=len:
break
# 官方文档
https://docs.python.org/2/library/array.html
Python数组类型的说明符
004.range
# range(10)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# range(5,10)
# [5, 6, 7, 8, 9]
# range(0,10,3)
# [0, 3, 6, 9]
# range(1,10,3)
# [1, 4, 7]
# range(1,10,10)
# [1,]
# range(1,10,-2)
# [1,]
# range(2,-10,-1)
# [2,1,0,-1,-2,-3,-4,-5,-6,-7,-8,-9]
# range(-2,-10,-1)
# [-2,-3,-4,-5,-6,-7,-8,-9]
# range(2,10,-1)、range(-2,10,-1)、range(2,-10,1)
# 以上三个容器都为空
# 语法 range(start, stop[, step])
# range(a,b,c)
# a不写时默认为0,从a开始;生成到b(故通常b>=a);c为步距
# range 默认生成正数方向,若a>b即b<a时将会往左生成负数,步距c也应要改为负数
# 即 不要求start和stop有什么直接的大小关系
# 测试
for i in range(10):
print(i,end=" ")
print()
range(start, stop[, step])
print(sum(range(1,101)))
面试问题:一行代码求和[0,100],并输出结果
005.lambda
lambda
map
filter
reduce
sum
006.random
007.time
008.re
# -*- coding:utf-8 -*-
# re 正则表达式
import re
# raw string 原生字符串
s1 = "abc\nop"
s2 = r"abc\nop"
print("s1=",s1)
print("s2=",s2)# 逗号隔开的输出会默认输出一个空格以分开
print(s2,s2) # 再次验证该空格
raw string 原生字符串
# -*- coding:utf-8 -*-
# re 正则表达式
import re
# patter 正则表达式
# string 待匹配的母字符串
# flags 标志位:是否区分大小写、是否多行匹配
text = 'This is a student,named MY from SJTU University.'
# re.match(pattern, string, flags=0)
# 定死了必须从开头的首元素位置(索引为0)开始匹配
res = re.match('This',text)# 默认flag为0,完全匹配模式(严格大小写、字符配对)
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('this',text)
# None
print(res)
res = re.match('this',text,re.I)# 置 flags 为 re.I后忽略大小写;爬虫数据清洗通常使用多行匹配且不区分大小写的匹配模式
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('is',text) # None,re.match()非开头即是匹配得到也不能够配对
print(res)
res = re.match('(.*)is',text)
# "."匹配任意字符(默认为贪婪模式、尽可能多地匹配) + "*"匹配前一个字符0次或多次 = 若存在,则往前取任意多字符直到起始位置(全部取)
# <re.Match object; span=(0, 7), match='This is'>
print(res)
res = re.match('(.*) is',text)# ' is'往前全部取、包括正则表达式子串本身(贪婪、会尽可能多匹配),上一个是'is'往前全部取,两者运行结果一样
# <re.Match object; span=(0, 7), match='This is'>
print(res)
res = re.match('(.*) is ',text)# ' is '往前全部取(包括正则表达式子串本身、贪婪模式会尽可能多匹配)
# <re.Match object; span=(0, 8), match='This is '>
print(res)
res = re.match('(.*?)is',text)# ‘?'匹配前一个元素0次或1次,默认懒惰模式、尽可能少匹配、故不含包括正则表达式子串,此例子中即不含'is'
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('(.*?) is',text)
# <re.Match object; span=(0, 5), match='This '># 注意区分这句与上一句,一个空格引起差异
print(res)
res = re.match('(.*?)is ',text)
# <re.Match object; span=(0, 7), match='This is'>
print(res)
res = re.match('(.*?) is ',text) # 由上述三句可知'?'懒惰模式无法舍弃空格
# <re.Match object; span=(0, 8), match='This is '>
print(res)
re.match(pattern, string, flags=0)
# -*- coding:utf-8 -*-
# re 正则表达式
import re
str = 'This is the last one'
res = re.match('(.*) is (.*?).*',str,re.M | re.I)
print(res)
res = re.match('(.*) is (.*?)(.*)',str,re.M | re.I)
print(res)
res = re.match('(.*) is (.*).*',str,re.M | re.I)
print(res)
res = re.match('(.*) is (.*)',str,re.M | re.I)
print(res)
# 以上四个运行结果同为 <re.Match object; span=(0, 20), match='This is the last one'>
res = re.match('(.*) is (.*?)',str,re.M | re.I)
print(res)
# <re.Match object; span=(0, 8), match='This is '>
# 由上可知,'.*'贪心匹配、元素有则取之
# 由上可知,'.*?'懒惰匹配、满足正则子串即可(注意:空格也要匹配)
# 数据清洗通常使用多行匹配 re.M 且不区分大小写 re.I 的匹配模式
强化理解一:贪心模式与懒惰模式
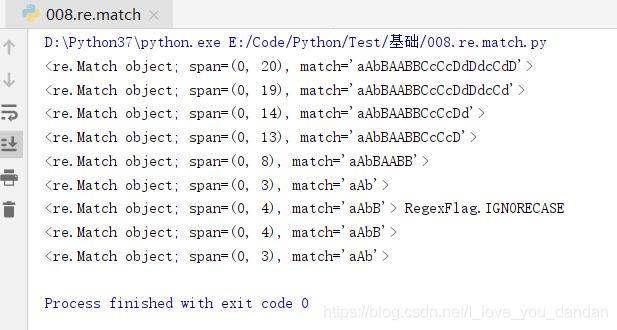
text = "aAbBAABBCcCcDdDdcCdD"
print( re.match("a.*d",text,re.I))
# <re.Match object; span=(0, 20), match='aAbBAABBCcCcDdDdcCdD'>
print( re.match("a.*d",text))
# <re.Match object; span=(0, 19), match='aAbBAABBCcCcDdDdcCd'>
print( re.match("a.*?d",text))
# <re.Match object; span=(0, 14), match='aAbBAABBCcCcDd'>
print( re.match("a.*?d",text,re.I))
# <re.Match object; span=(0, 13), match='aAbBAABBCcCcD'>
print( re.match("a.*b",text,re.I))
print( re.match("a.*?b",text,re.I))
print( re.match("a.*?B",text),re.I)
print( re.match("a.*?B",text))
print( re.match("a.*?b",text))
# 上边四句的输出结果依次对应如下:
# <re.Match object; span=(0, 8), match='aAbBAABB'>
# <re.Match object; span=(0, 3), match='aAb'>
# <re.Match object; span=(0, 4), match='aAbB'> RegexFlag.IGNORECASE
# <re.Match object; span=(0, 4), match='aAbB'>
# <re.Match object; span=(0, 3), match='aAb'>
强化理解二:实例补充
贪心尽可能多、从原母字符串原长逐渐剔减,
惰性则正则字串刚好满足条件即可
由此两个强化理解的实例可知,re.match的正则表达式为字符串,需要使用单或双引号格式,但有无小括号并不影响re.match的匹配。
剩下的诸如特殊表达式序列、字符集、以花括号指定匹配次数、顺/逆序肯/否定环视等知识点,多多敲码、多看官方文档。
视野拓展:查看官方的开发文档
# -*- coding:utf-8 -*-
import re
text = 'This is a text written by MY ,' \
'from SheHui University on 2019/11/06 at 00:39.'
res = re.search(r'(\d)',text,re.I)
# <re.Match object; span=(69, 70), match='2'>
# \d 同 [0-9] 匹配任意(单个)十进制数
print(res)
res = re.search(r'(\D)',text,re.I|re.M)
# <re.Match object; span=(0, 1), match='T'>
# \D 同 [^0-9] 匹配任意(单个)非数字字符
# 注意:符号^在方括号内
print(res)
res = re.search(r'(\d).*',text,re.I|re.M)
# <re.Match object; span=(69, 89), match='2019/11/06 at 00:39.'>
print(res)
# res = re.search(r'.*(\d)',text,re.I)
# res = re.search(r'.*(\D).*',text,re.I)
# res = re.search(r'.*(\D)',text,re.I)
res = re.search(r'(\D).*',text,re.I|re.M)
# 上边被注释掉的3句,运行结果与此句相同
# <re.Match object; span=(0, 88), match='This is a text written by a student named MY from>
print(res)
res = re.search(r'(\w)',text,re.I|re.M)
# <re.Match object; span=(0, 1), match='T'>
# \w 同 [a-zA-Z0-9]
print(res)
res = re.search(r'(\W)',text,re.I|re.M)
# <re.Match object; span=(4, 5), match=' '>
# \W 同 [^a-zA-Z0-9]
print(res)
res = re.search(r'(\W).*',text,re.I|re.M)
# <re.Match object; span=(4, 76), match=' is a text written by MY ,from SheHui University >
print(res)
res = re.search(r'(\w)(.*)',text,re.I|re.M)
# <re.Match object; span=(0, 76), match='This is a text written by MY ,from SheHui Univers>
print(res)
re.search(pattern, string, flags=0)
# -*- coding:utf-8 -*-
# re 正则表达式
# patter 正则表达式
# 用于替换的字符串
# string 要被替换的母字符串
# count 替换次数,默认为0表示无穷多次
# flags 标志位:是否区分大小写、是否多行匹配
# re.sub(pattern, repl, string, count=0, flags=0)
import re
# 单纯替换
text = '1+1=2'
res = re.sub(r'=',r'>',text,0,re.I)
print(text)
print(res)
print('------------0------------')
# 去除注释(无用信息、这在爬虫中往往用于数据清理)
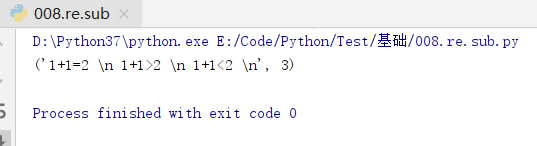
text = '1+1=2 # 这是客观真理 \n' \
' 1+1>2 # 这是团结的力量 \n' \
' 1+1<2 # 这是内斗结果 \n'
res = re.sub(r'#.*$',r'',text,0,re.M)
print(text)
print('------------1----------')
print(res)
print('------------2----------')
res = re.sub(r'#.*$',r'',text,0,re.M)
print(res)
print('------------3----------')
res = re.sub(r'#.*$',r'',text,0,re.M|re.S)
print(res)
print('----------4------------')
res = re.sub(r'#.*$',r'',text,1,re.M)
print(res)
print('----------5------------')
res = re.sub(r'#.*$',r'',text,2,re.M) # 多行模式,去掉注释(替换)次数为 2
print(res)
print('----------6------------')
res = re.sub(r'#.*$',r'',text,3,re.M)
print(res)
print('----------7------------')
res = re.sub(r'#.*$',r'',text,2)# 不出标志说明是多行模式的话,$ 仅仅匹配末尾
print(res)
print('----------8------------')
res = re.sub(r'#.*$',r'',text,2,re.X)
print(res)
# 详细模式的多行将忽略空白字符和注释,故替换失败
# re.find()查找默认对多行模式生效
print('----------9------------')
res = re.findall('#',text)
print(res)
re.sub(pattern, repl, string, count=0, flags=0)
# -*- coding:utf-8 -*-
# re.subn(pattern, repl, string, count=0, flags=0)
import re
text = '1+1=2 # 这是客观真理 \n' \
' 1+1>2 # 这是团结的力量 \n' \
' 1+1<2 # 这是内斗结果 \n'
res = re.subn(r'#.*$',r'',text,0,re.M)
print(res)
# subn 与 sub 这两个函数用法完全一样,只是前者返回元组,后者返回字符串
re.subn(pattern, repl, string, count=0, flags=0)
扫描二维码关注公众号,回复:
8936919 查看本文章

# -*- coding:utf-8 -*-
# re 正则表达式
# patter 正则表达式(定义字符串如何构成)
# flags 标志位:是否区分大小写、是否多行匹配
# re.compile(pattern[, flags])
import re
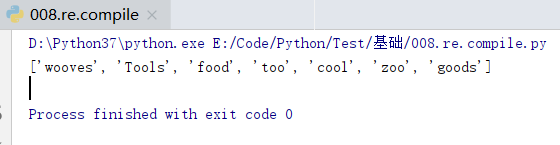
words = 'wooves Tools food too cool hello zoo \n goods'
ret = re.compile(r'\w*oo\w*') # 编译生成查找含有oo字母元素的单词的正则表达模式对象 obj对象可以直接调用re的方法
print(re.findall(ret,words)) # re.findall() 默认多行查找
print((ret.findall(words))) # 这是第二种有效的等价写法
# 正则模式的对象obj可以直接调用re的任何方法
re.compile(pattern[, flags])
# -*- coding:utf-8 -*-
import re
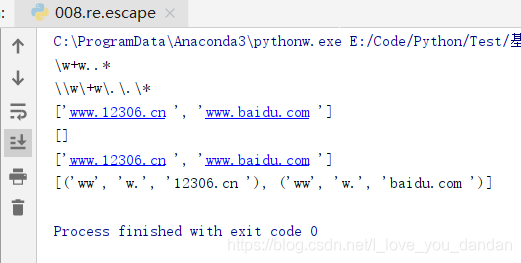
# re.escape(string)
# string 为需要转义的字符串(常作为正则表达字串)
str = 'www.12306.cn \n' \
'www.baidu.com '
pat = '\w+w..*'
ret = re.escape(pat)
print( pat)
print( ret)
# findall(pattern, string, flags=0)
print( re.findall(pat,str))
print( re.findall(ret,str))
print( re.findall(r'\w+w..*',str))
print( re.findall(r'(\w+)(w.)(.*)',str))
# 输出依次为
# \w+w..*
# \\w\+w\.\.\*
# ['www.12306.cn ', 'www.baidu.com ']
# []
# ['www.12306.cn ', 'www.baidu.com ']
# [('ww', 'w.', '12306.cn '), ('ww', 'w.', 'baidu.com ')]
# escape “逃离”->“偏离原有意图”
# 不再是 raw string 原生字符串、可以可以表示转义
# 而是 硬生生的字符本身、别无组合之后的其他意思
re.escape(string)
# -*- coding:utf-8 -*-
# re 正则表达式
# findall(string[, pos[, endpos]])
import re
res = re.findall(r"\d", "图书馆2019年11月的阅读次数为 99万") # 返回的是不可修改的元组
print(res) # ['2', '0', '1', '9', '1', '1', '9', '9']
res = re.findall(r"(\d+)", "图书馆2019年11月的阅读次数为 99万,点赞数:3200")
print(res) # ['2019', '11', '99', '3200']
res = re.findall(r"(\D+)", "图书馆2019年11月的阅读次数为 99万,点赞数:3200")
print(res) # ['2019', '11', '99', '3200']
for i in res:
print(i)
print('--------分割线---------')
# words = ['wooves','Tools','food','too','cool','hello','zoo']
words = 'wooves Tools food too cool hello zoo \n goods'
print("1 ",re.findall(r'Oo',words))
print('2 ',re.findall(r'Oo',words,re.I))
print('3 ',re.findall(r'(\w+)(Oo)(\w*)',words,re.I))
# 方式3 正则表达式全部被括号分割包围时,结果为元组内部嵌套了列表
# 方式4 将按照元祖形式输出符合匹配条件的“单词”(即含有元素“oo”、不区分大小写)
print('4 ',re.findall(r'\w+Oo\w*',words,re.I))
print('5 ',re.findall(r'\w+(Oo\w*)',words,re.I))
# 当正则表达式只是部分还有括号时,仅输出 括号部分对应的元祖(字符串)
print('6 ',re.findall(r'(\wOo)w*',words,re.I))
print('7 ',re.findall(r'(\wOo).*',words,re.I))
print('8 ',re.findall(r'(\wOo)(.*)',words,re.I))
print('9 ',re.findall(r'\wOo.*',words,re.I))
print('10 ',re.findall(r'\w+oo\w.*',words))
print('11 ',re.findall(r'\w+oo\w.*',words,re.S))
# re.S 模式下 '.'可以匹配任意字符,包括默认不允许的回车‘\n’换行符
findall(pattern, string, flags=0)
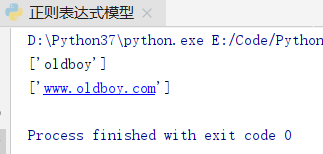
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret) # ['oldboy']
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret) # ['www.oldboy.com']
# findall会优先把匹配结果组里内容返回,这也正是上边只输出部分括号对应的正则匹配结果的原因
# 如果想要完整的正则匹配结果,使用 ‘?:’取消优先级权限即可
强化理解之优先级问题
# -*- coding:utf-8 -*-
# re 正则表达式
# patter 正则表达式(定义字符串如何构成)
# string 待查找的母字符串
# flags 标志位:是否区分大小写、是否多行匹配
# re.finditer(pattern, string, flags=0)
import re
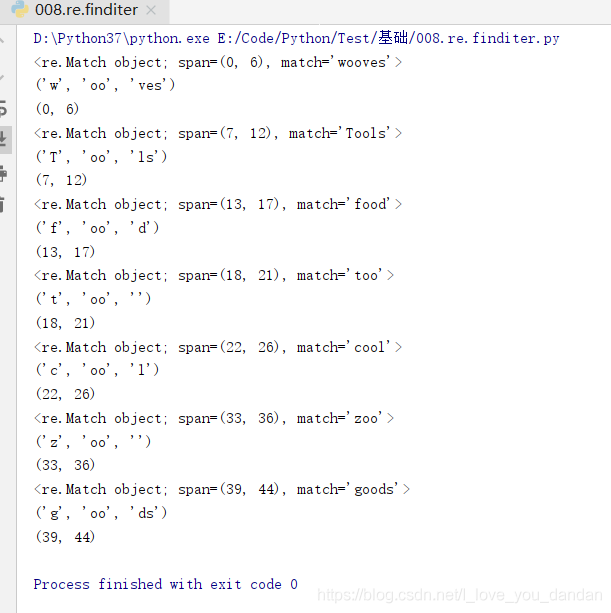
words = 'wooves Tools food too cool hello zoo \n goods'
ret = re.compile(r'(\w*)(oo)(\w*)') # 编译生成查找含有oo字母元素的单词的正则表达模式对象
res = re.finditer(ret,words)
for i in res:
print(i)
print(i.groups())# 所有分组;正则表达模式有了括号才有分组,否则为空
print(i.span())# 生产的区间始终是“左闭右开”格式
# 需要注意的是,re.finditer()与re.find()一样,只输出有括号的部分
# 但区别是 前者生成列表,后者生成元组
re.finditer(pattern, string, flags=0)
# -*- coding:utf-8 -*-
# re 正则表达式
# patter 正则表达式(用于替换的字符串)
# string 作为分隔素材的母字符串
# maxsplit 用于指定最大分割次数,不指定则默认为0表示无穷大、将全部分割
# flags 标志位:是否区分大小写、是否多行匹配
# re.split(pattern, string[, maxsplit=0, flags=0])
# 返回列表
import re
words = 'wooves Tools food too cool hello zoo \n goods'
res = re.split(r'\W',words)
print(res)
res = re.split(r'\s',words)
print(res)
res = re.split(r'\s+',words) # 这才是正确去除所有空白符 [\t\n\r\f\v] 因为 *与+ 表示贪心模式(?要看情况)
print(res)
res[1]='123' # 成功修改,故返回的是列表而不是元组
print(res)
text = '?a_b!2@'
res = re.split(r'\w+',text) # 由该句可知:\w除了匹配字母和数字,还匹配下划线(标识符命名规则……)
print(res)
print(re.split('a','1A1a2A3',re.I)) # ['1A1', '2A3']
print(re.split('a','1A1a2A3',0,re.I))# ['1', '1', '2', '3']
# 请注意使用格式这个大坑,否则将会导致re.I无法忽略字母的大小写
re.split(pattern, string[, maxsplit=0, flags=0])
\w 匹配字母数字及下划线,即:\w = [a-zA-Z0-9] + '_'
\W 匹配f非字母数字下划线,即: \W = [^a-zA-Z0-9] + '_'
\s 匹配任意空白字符,即: \s = [\t\n\r\f\v]
\S 匹配任意非空字符,即: \S = [^\t\n\r\f\v]
\d 匹配任意十进制数数字,即: \d = [0-9]
\D 匹配任意非数字字符,即: \D = [^0-9]
\A 只在字符串首部开始匹配
\b 匹配位于开始或结尾的空字符串
\B 匹配不位于开始或结尾的空字符串
\Z 匹配字符串结束,如果存在换行,只匹配换行前的结束字符串
\z 匹配字符串结束
\G 匹配最后匹配完成的位置
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开头
$ 匹配字符串的末尾
. 匹配任意字符,除了换行符,re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符
[....] 用来表示一组字符,单独列出:[amk]匹配a,m或k
[^...] 不在[]中的字符:[^abc]匹配除了a,b,c之外的字符
* 匹配0个或多个的表达式
+ 匹配1个或者多个的表达式
? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
{n} 精确匹配n前面的表示
{m,m} 匹配n到m次由前面的正则表达式定义片段,贪婪模式
a|b 匹配a或者b
() 匹配括号内的表达式,也表示一个组
re模式
前面的*,+,?等都是贪婪匹配,也就是尽可能匹配:
“从整个字符串逐减1个末尾元素直至满足条件……”
后面加?号使其变成惰性匹配:
“从字符串的第一个元素开始,逐增1个首部元素直至满足条件……”
贪婪模式与惰性匹配
res = re.search(r"\d+", "图书馆2019年11月的阅读次数为 99万").group() # 只匹配第一组数字
print(res) # 2019
res = re.search(r"\d+", "图书馆2019年11月的阅读次数为 99万")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# () 由此可知group存在的条件是正则匹配使用了小括号
res = re.search(r"(\d+)", "图书馆2019年11月的阅读次数为 99万")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# ('2019',)
res = re.search(r"(\d)(\d+)", "图书馆2019年11月的阅读次数为 99万")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# ('2', '019')
res = re.search(r"(\d+)(\d)", "图书馆2019年11月的阅读次数为 99万")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# ('201', '9')
res = re.search(r"(\d)(\d+)(\d)(\D)", "图书馆2019年11月的阅读次数为 99万")
# print(res) # <re.Match object; span=(3, 8), match='2019年'>
print(res.groups())# ('2', '01', '9', '年')
res = re.search(r"(\d+)(.*)", "图书馆2019年11月的阅读次数为 99万,点赞数:3200")
print(res) # <re.Match object; span=(3, 30), match='2019年11月的阅读次数为 99万,点赞数:3200'>
print(res.groups()) # ('2019', '年11月的阅读次数为 99万,点赞数:3200')
print(res.group(0))
print(res.group(1))
print(res.group(2))# 超出索引将会输出空列表,不报异常
group(s)
# -*- coding:utf-8 -*-
import re
a = "123abc456"
res = re.search("([0-9]*)([a-z]*)([0-9]*)",a) #123abc456,返回整体
print(res.groups())
for i in range(1+len(res.groups())):
print(res.group(i))
# 由此可见,group(i)参数i并非像索引那般范围被限定在了[0,len)左闭右开区间
# 而是[0,len]双闭合,即能够取到参数len
# 另外,值得注意的是 group 与 groups不是拼写错误,而是规定……
# 注意融会贯通,当只需要各个列表元素时,使用以下的写法
print("----------------我是分割线----------------")
for i in res.groups():
print(i)
特别补充说明:
一般情况下,group()和groups()方法 仅与re.match()或re.search() 共同使用,不涉及其他 re的操作。
虽然re.findall()与re.finditer()在它们的正则表达式存在圆括号时,也可以使用,但由于返回的是列表数据类型,直接调用会更加方便、高效。
(任意长)词组:
ret = re.compile(r'\w+',re.I)
匹配到任意一个字母或单词(不区分大小写)、中文(单个汉字或连续的多个汉字)、或连续的阿拉伯数字,也可为此三者直接相连的组合体
及一反三:
r'\w+abc\w*'表示含有字母abc(必须完全匹配abc)的单词/字符串
(任意长)数字:
ret = re.compile(r'\d+')
匹配到任意数字(串)
(任意长)空白字符:
r'\s+'或r'\s*' 可用于数据清洗
举一反三:
re.split(r'\s+',text,0,re.S|re.X)文本按照空白字符全部分割
re.sub(r'\s+',r'',text,0,re.S|re.X))文本所有空白字符一律删除
(多行)注释去除
re.sub(r'#.*$',r'',text,0,re.M)
(多行)数据删除
re.sub(r'.*?<p>',r'',text),re.S|re.X)
<p>标签之前全部删除 可等效改为r'.*<p>'或r'.+<p>'或r'.+?<p>'
举一反三:
r'<p>.*'或r'<p>.+' 表示匹配<p>标签之后全部数据
说明:<p>标签本身也在数据范围之内(贪婪模式)
常见字符类
正则表达的常见应用(模型)
详情请看项目实战部分:04 数据清洗
009.(not) in
010.is
011.stack
012.queue
013.列表生成式
def fizzBuzz(n):
return ['Fizz' * (not i % 3) + 'Buzz' * (not i % 5) or str(i) for i in range(1, n+1)]
print(fizzBuzz(30))
面试问题:FizzBuzz数列
014.package
015.搜索算法
find
BFS(广度优先)
DFS(深度优先)
016.最短路径
017.矩阵
支持多维数组 #### NumPy
018.排序
019.查找
020.eval
def fizzBuzz(n):
return ['Fizz' * (not i % 3) + 'Buzz' * (not i % 5) or str(i) for i in range(1, n+1)]
n = input('input n:')
res = fizzBuzz(eval(n)) # str(n)将报错
print(res)
eval()与str()
021.待定
模板代码
001.ProgrammingParadigm
# -*- coding: UTF-8 -*-
# 范式编程(函数式编程)
def main():
my_dict = {'子': '鼠', '丑': '牛', '寅': '虎', '卯': '兔',
'辰': '龙', '巳': '蛇', '午': '马', '未': '羊',
'申': '猴', '酉': '鸡', '戌': '狗', '亥': '猪'}
prinfDictKeys(my_dict)
printDictValues(my_dict)
printDict(my_dict)
def prinfDictKeys(dict):
for key in dict.keys():
print(key, end=" ")
print()
def printDictValues(dict):
for value in dict.values():
print(value, end=" ")
print()
def printDict(dict):
for key in dict:
print(key,":",dict[key],end='\t\t')
if __name__ == '__main__':
main()
范式编程(函数式编程)
# 上边构造的字典my_dict有另外一种等价写法
my_dict = dict(子='鼠', 丑='牛', 寅='虎', 卯='兔', 辰='龙', 巳='蛇', 午='马', 未='羊', 申='猴', 酉='鸡', 戌='狗', 亥='猪')
002.Object-Oriented Programming
OOP面向对象编程
Python中,类即对象;对比JavaScript;以及原始印象中的C++的类与对象
003.待定
项目实战
001.Python绘图
Python应用范围广泛,正是因为它的第三方库非常的丰富。今天来介绍一些和绘图有关的第三方库。
第一种是绘图工具
hmap-图像直方图的库。
imgSeek-使用视觉相似性搜索图像集合的项目。
Nude.py-色情图片识别的库。
pagan-基于输入字符串和散列的复古识别(Avatar)生成。
pillow-Pillow由PIL而来,是一个图像处理库。
pyBarcode-在Python中创建条形码而不需要PIL。
pygram-像Instagram的图像过滤器。
python-qrcode-一个纯Python QR码生成器。
Quads-基于四叉树的计算机艺术。
scikit-image-用于(科学)图像处理的Python库。
thumbor-一个小型图像服务,具有剪裁,尺寸重设和翻转功能。
wand-MagickWand的Python绑定,ImageMagick的C API。
turtle-海龟渲染器,使用Turtle库画图也叫海龟作图(留言贡献)
第二种就是数据可视化的绘图库
Altair-使用Altair,您可以花费更多时间了解您的数据及其含义。Altair的API简单,友好和一致,建立在强大的Vega-Lite JSON规范之上。这种优雅的简洁性以最少的代码产生了美丽而有效的可视化。
Bokeh-Python的交互式网络绘图。
ggplot-与ggplot2相同的API。
Matplotlib-一个Python 2D绘图库,用以绘制一些高质量的数学二维图形。
Pygal-一个Python SVG图表创建者。
PyGraphviz-Graphviz的Python接口。
PyQtGraph-交互式和实时2D/3D/图像绘图和科学/工程小部件。
Seaborn-使用Matplotlib的统计数据可视化。
VisPy-基于OpenGL的高性能科学可视化。
002.文件操作
# -*- coding:utf-8 -*-
import csv
csvfile = open('csv_test','w',newline='')
writer = csv.writer(csvfile)
writer.writerow(['name','age','sex','phone'])
data = [('bbc','18','M','7458025'),
('cnn','17','F','9969966'),
('CCTV','12','M','1100901')]
writer.writerow(data)
csvfile.close()
CSV文件
注意事项:py文件名不能起成“csv”
否则将会导致如下错误:
“AttributeError: module 'csv' has no attribute 'writer'”
## 003.涉及网络(上传、下载)
004.数据清洗 (字符串操作)
知识点详情请往回查看基础知识部分:008 re 正则表达式
正则表达式
str = "1234567"
print( str[0:5:] )# 左闭右开区间,元素下标 从min到max-1(右边是指中间位置)
print( str[2:10:] )# 右边超出可当作len值
print( str[::])# 原串
print( str[6::])# 左边若是超过len-1则为空串,右边不写默认 len
print(str[2]," ",str[-2])# 单个点索引不可超出范围[0,len)或[0,len-1]
print( str[-2::])# 左边为负数-则表示从倒数第i个数开始往右
print( str[:-2:])# 左边不写默认为0,右边为负数-截取至i-1(即:依旧是左闭右开)
print( str[2:-2:])# 345
print( str[-4:-2:])# 45
print( str[::-1])# 反序字串,相邻索引值差为1
print( str[::-2])# 反序字串,按照相邻索引值差为2截取部分
print( str[::-4])# 反序字串# 反序字串,按照相邻索引值差为4截取部分
print( str[3::-1])# 4321 逆序,索引i在左、正数,取str[i]左侧、含str[i]
print( str[:3:-1])# 765 逆序,索引i在右、正数,取str[i]右侧、不含str[i]
print( str[:-3:-1])# 76 逆序,索引i在右、负数,取str[len-i]右侧、不含str[len-i]
print( str[-3::-1])# 54321 逆序,索引i在右、负数,取str[len-i]左侧、含str[len-i]
print( str[-2:-4:-1])# 65
print( str[-2:2:-1])# 654
三个参数“左起点a:右起点b:顺序及步距标志c”。
a、b可正可负,正则从左往右数、负则自右往左数、区间始终是左闭右开区间。
c通常省略默认正序步距为1或者置c为-1表示逆序步距为1,也可修改步距大小(可正可负)。
字符串截取
str = "abcABCaBcD"
print( str.replace('c','E'))# abEABCaBED 大小写敏感
print( str) # abcABCaBcD 由此可知,替换生成了新对象、原字串不受影响
print( str.replace('Bc','E'))# abEABCaBED 替换并不要求元素的位数相同
print( str.replace('Bc',' '))# abEABCaB D 替换成空格
print( str.replace('Bc',''))# abEABCaBED 替换成空串时默认为删除该(片段)元素
print( str.replace('Bc',' '))# abEABCaB D 替换成空格
字符串替换
# 字串查找
str = "AbCdABCDabcdABCD"
print( str.find('A'))# 默认从索引0开始往右查找
print( str.find('A',2))# 从索引2即第三个数开始往右查找
print( str.find('c',2,10))# 在索引范围 [2,10)开始查找,左闭右开区间
print( str.find('c',2,11))# 在索引范围 [2,10)开始查找
# 找到,返回对应索引(单个数值);找不到,返回 -1
# index与find等效果,不过找不到时会报异常而不是返回-1
字符串查找
# 字串分割
str = "ABCDABCDABCD"
print( str.split('A'))# 返回元组(元组的元素不可更改)
print( str.split('A',2))# 分割成 i+1份(i为数字参数)在最左边分割,左侧将会产生空串
print( str.split('B',2))# 分割成 i+1份(i为数字参数),分割时去除分隔符
print( str.split('D',2))# 在最右边元素产生分割无效,有且仅有此种情况保留分隔符
# 字串的分割和替换是数据清洗的基本
字符串分割
str = '123123'
all = []
for i in range(0,len(str),1): # 开始的索引位置 i
for j in range(1,len(str)+1,1):# 子串长度 j ,而且还是字符串截取的有区间点(左闭右开)
# print("i=", i, " ", "j=", j)
if i>=j:
continue
all.append( str[i:j:])
print( all)
print( set( all)) # 可以直接输出,也可以赋成新的列表
print( all) # 并不对列表的原始数据造成影响
字符串生成所有非空子串
# -*- coding:utf-8 -*-#
Html_content = """<html><head><title> Python</title></head>
<p class="title"><b>Beautiful Soup的学习</b></p>
<p class="study">学习网址:http://blog.csdn.net/huangzhang_123
<a href="www.xxx.com" class="abc" id="try1">web开发</a>,
<a href=" www.ccc.com " class="bcd" id="try2">网络爬虫</a> and
<a href=" www.aaa.com " class="efg" id="try3">人工智能</a>;
</p>
<p class="other">...</p>"""
from bs4 import BeautifulSoup # 引入beautifulsoup
soup = BeautifulSoup(Html_content,'html5lib') #
print(1,soup.head) # 头部原样
print(soup.head.getText()) # 头部数据(即内容)
print(2,soup.title) # 标题原样
print(soup.title.getText()) # 标题数据
print(3,soup.body.b) # 可直接指定标签类别
print(soup.body.b.getText()) # 标签数据
print(4,soup.a) # 获取指定标签的第一个
print(soup.a.getText()) # 标签内容
print(soup.a['class']) # 标签属性值,若有多个时,同样是返回列表
print(5,soup.find_all('a')) # findall返回的是列表list
for i in soup.find_all('a'): # list的没一个元素是一个标签原样
print(i) # 标签原样
print(i.getText()) # 标签内容
print(7,soup.select('#try3')) # id
print(soup.select('.efg')) # class
print(soup.select('a[class="efg"]')) # 属性
# CSS选择器,可以通过以下3种方式进行查找
# soup.select('#try3') # id
# soup.select('.efg') # class
# soup.select('a[class="efg"]') # 属性
# <a href="www.aaa.com" class="efg" id="try3"> 人工智能</a>
005.Beautiful Soup
实例运行结果(内嵌HTML字符串)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> Python</title>
</head>
<body>
<p id="python">
<a href="/index.html"> Python </a>BeautifulSoup的使用
</p>
<p class=”myclass”>
<a href="http://www.baidu.com/">这是</a> 一个指向百度的页面的URL。
</p>
</body>
</html>
MySoup.Html与mySoupDemoPy文件处于同一目录下
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
Open_file = open('MySoup.html','r',encoding='utf-8')
Html_Content = Open_file.read()
Open_file.close()
soup = BeautifulSoup(Html_Content,'html5lib')
print(soup.title.getText())
find_first_p = soup.find('p',id='python')
print(find_first_p.getText())
find_all_p = soup.find_all('p')
for i, k in enumerate(find_all_p):
print(i+1,k.getText())

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![面试问题:一行代码求和[0,100],并输出结果](https://img-blog.csdnimg.cn/20191104221324724.PNG#pic_center){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}