分布式系统已经无处不在,它有哪些特性,在 MySQL 应用过程中的表现形式是什么样的,这里做一些介绍和总结。
分布式理论基石 CAP
- 一个分布式系统最多只能同时满足 CAP 这三项中的两项,以分布式关系型数据库举例说明:
- Consistency 一致性:一个事务在一个节点提交后,在同一时间所有节点读出来的数据是一致的;
- Availability 可用性:系统中任何一个节点故障,不影响整体继续提供服务;
- Partition Tolerance 分区容错性:当系统内部出现网络故障,所有节点仍然都可用,但是内部出现脑裂,此时也不影响一致性。
- CAP 在本质上,是分布式系统设计过程中需要考虑的最基本的三个问题。
- 虽然没有完美的 CAP,但是,在实际业务场景中,我们可以根据业务场景的实际需求,有取舍的进行分布式系统的设计,给用户一个完美的体验。
- 例如,对于一致性问题,节点间的网络延迟和对性能的要求是现实存在的矛盾点和难点,因此,在实现过程中出现了强一致性、弱一致性和最终一致性。
必备利器 ZooKeeper
- ZooKeeper 是一个分布式协调服务
- 可以有非常多的应用:发布订阅、命名服务、分布式协调和分布式锁
- 基于 Fast Paxos 思想实现,是对 Basic Paxos 算法的优化
- 服务方式为 Server/Client 模式
- 允许分布式进程通过 Client 共享 Server 中的层次结构命名空间,从而实现相互协调,命名空间与标准文件系统类似
/zoo-1/tiger,称为 ZNode - ZNode 分为持久节点和临时节点两类,其中临时节点的生命周期和 session 绑定,一旦 session 失效,那么临时节点会被移除
- ZNode 支持自动编号功能,这种 ZNode 节点会根据当前已近存在的 ZNode 节点编号自动加 1
- ZNode 操作包括:CREATE/DELETE/READ/WRITE
- ACL 权限控制包括: CREATE/DELETE/READ/WRITE/ADMIN
- Fast Paxos 中的角色分类:领导者(Leader)、跟随者(Follower)、观察者(Observer),Leader 的选举流程如下:
- 每个Server发出一个投票。每次投票会包含所推举的服务器的(myid, ZXID),然后各自将这个投票发给集群中其他机器。
- 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
- 处理投票。针对每一个投票,服务器都进行比较,比较的规则是:优先选择 ZXID 更大的,然后选择 myid 较大的。
- 统计投票。每次投票后,服务器都会统计投票信息,如果确认已经有过半机器接收到相同的投票信息,则确认 Leader。
- 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING。
- Fast Paxos 中事务的请求和提交的流程如下:
- 发起投票。若当前请求是事务请求,Leader 会发起一轮事务投票,在发起事务投票之前,会检查当前服务端的 ZXID 是否可用。
- 生成提议 Proposal。若 ZXID 可用,ZooKeeper 会将已创建的请求头和事务体以及 ZXID 和请求本身序列化到 Proposal 对象中,此 Proposal 对象就是一个提议。
- 广播提议。Leader 以 ZXID 作为标识,将该提议放入投票箱 outstandingProposals 中,同时将该提议广播给所有 Follower。
- 收集投票。Follower 接收到 Leader 提议后,进入 Sync 流程进行日志记录,记录完成后,发送 ACK 消息至 Leader 服务器,Leader 根据这些 ACK 消息来统计每个提议的投票情况,当一个提议获得半数以上投票时,就认为该提议通过,进入 Commit 阶段。
- 将请求放入 toBeApplied 队列中。
- 广播 Commit 消息。
MySQL 应用中的分布式情况
信息化和数字化的脚步势不可挡,数据库为了不成为业务发展的瓶颈,其不断扩容的过程,也是分布式技术逐步深入数据库领域的过程。
- 一、 存储空间和读写流量扩展:分库分表
- 如果一个电商平台稳健发展的话,订单数据是比较容易出现数据量大的问题,所以需要对它进行拆分。
- 此时从理论上对订单拆分有两个维度,一个是订单的 id 取模的方式,即以订单 id 为分库分表键。另一个是通过卖家用户 id 进行取模,即以卖家用户 id 为分库分表键。
- 如果是按照订单 id 取模,比如按照 64 取模,则可以保证主订单以及相应的子订单,和详情数据平均落入 64 个数据库中。
- 如果按照卖家用户 id 取模的方式,比如也是按照 64 取模,也能够保证订单相关数据拆分到 64 个数据库中。但如果有些卖家的交易量很大,就会出现数据不平均的现象。
- 二、 多维度查询扩展:异构索引表
- 按照订单 id 取模虽然很好地满足了订单数据均匀地保存在数据库中,但在买家查看自己订单的业务场景中,就出现了扫描所有的 64 个分库然后聚合结果的情况,严重影响效率。
- 采用“异构索引表”的方式解决,即采用异步机制将原表的每一次插入或更新,都以另一个维度(买家 id 取模分库)保存一份完整的数据表,并构建相应的索引,这是拿空间换时间的典型思路。
- 应用向以订单 id 分库分表的数据库插入或更新一条数据时,也会再保存一份到以买家 ID 分库分表的数据库,其结果就是同一条订单数据在两个数据库中同时存在,这就是给订单创建了异构索引表。
- 三、 单点读流量扩展:一主多备
- 在读流量极大的情况下,需要这种一个主库(提供数据更新服务)多个备库(提供数据查询服务)的结构,尤其适用于写流量非常少,读流量非常大的配置数据库

- 在读流量极大的情况下,需要这种一个主库(提供数据更新服务)多个备库(提供数据查询服务)的结构,尤其适用于写流量非常少,读流量非常大的配置数据库
- 四、 异地容灾和就近访问:单元化
- 单元化核心设计思想是从 C 端用户角度考虑,将用户核心业务的闭环链(比如购物闭环),内聚到一个单元,用户在 C 端操作的一个完整过程,相关数据都能在一个单元内完成,避免跨单元获取数据。这里的一个单元可以是一个机房,也可以是一个机房内的某一组子系统群。
- 可以按照一定的路由规则(按照用户 id 或者活用的地理位置),让某些用户的访问请求在某个单元闭环完成,例如,深圳附近的用户的所有访问请求都在深圳单元,实现就近访问。
- 单元化使整体系统具备了极强的水平伸缩能力,
- 异地多活怎么去应对故障
- 五、 分布式数据库
- 分布式事务
- 分布式存储
数据质量问题
数据质量面临的挑战是,在分布式部署场景下的,最终一致性的保障。我们假设,单元间的数据同步也是基于 binlog 的异步复制,数据同步方式如下图。
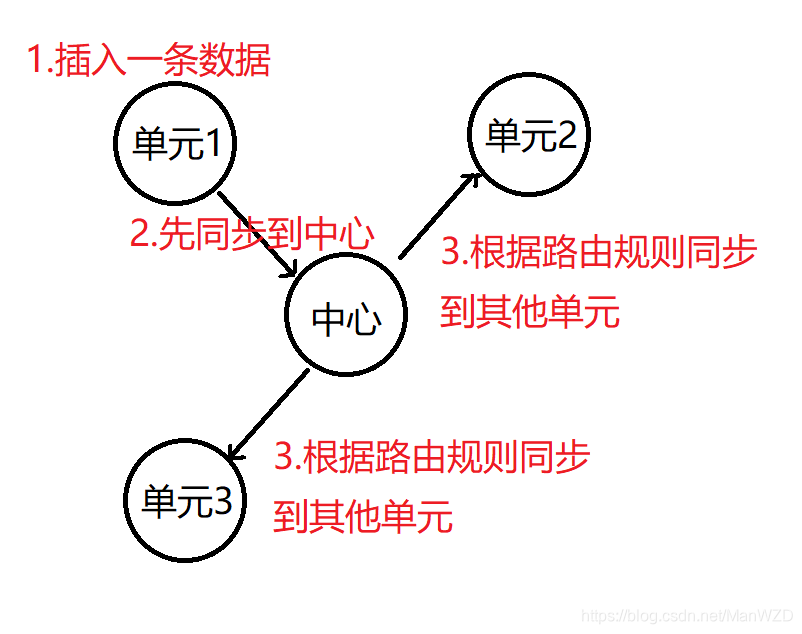
-
单元内的情况,某个单元发生网络故障时,单元内主库备库的数据一致性问题
- 异步复制和孤岛双写导致老主库多数据,同时回补时由于自增 ID 或状态推进导致无法自动修复
-
单元间的情况,某个单元发生网络故障,由此产生的单元间的数据一致性问题
- 单元 2 中主备切换后,中心向新主库复制数据时,无法获取准确的位点,往往会产生偏差。
- 自动修复和单元间同步交叉使用 binlog 的数据,导致单元间不一致
- 自动修复,导致依赖 binlog(例如异构表) 的应用获得脏数据
基于 binlog 的自动修复
- 针对老主库多数据的情况,解析 binlog 获得可执行 SQL 语句
- 在老主库反向执行 SQL 完成回滚(执行时必须关闭 binlog),使主备数据一致
- 在新主库正向执行 SQL 实现回补,尽量修复数据
- 不足
- 事后的回补由于主键冲突等原因可能回补失败,导致丢数据
- 回滚很难支持 DDL/TRUNCATE 语句
- 回滚不记录 binlog,会导致单元间的不一致
数据校验和修复
- 增量数据校验
- 从业务层接收异步消息,获取用户 id、订单 id 等键值,对比单元内主备和单元间的数据
- 修复方式:记录不一致的情况,根据业务场景选择以某个节点数据去订正其他节点
- 缺点:无法保证全局的一致性
- 全量数据校验
- 使用全量校验程序,全量对比某两个节点的数据
- 修复方式:把记录不一致的情况同步给增量校验的后台,利用增量校验的修复逻辑,结合业务场景修复
- 缺点:全量校验比较耗时,查询使用的是 MySQL 快照读,可能会导致 undo log 无法及时回收,占用系统资源,只能在业务低峰期执行
强同步、半同步和强保护模式介绍
如果主备之间使用 XA 强同步(打开 sync_binlog),数据质量问题会得到极大的环节,但是对性能却是无法接受的。
- semi-sync (半同步)
- 半同步介于异步和全同步(sync_binlog 打开)之间
- 主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log 文件即可
- 半同步保证了主备的最终一致性,同时降低了主库事务 commit 的等待时间
- 半同步中主库在提交事务前会等待备库的 ack 信号,必须设置等待超时,在超时后,会退化到异步模式
- MP(强保护模式)
- 强保护模式是基于半同步模式的改进,区别在于等待备库 ack 超时后的处理方式
- MP 在超时后,会设置 read_only=1,使主库不能写入新数据,以此强制保护主备一致性
- 半同步(semi-sync)模式和强保护(MP)模式的不足
- 主备间网络抖动和备库故障都会影响可用性
- 高 tps 情况下 semi-sync 对 rt 有明显影响
参考文档
https://blog.csdn.net/u014231523/article/details/88096413
http://www.warski.org/blog/2011/07/trying-to-understand-cap/
https://www.cnblogs.com/paul8339/p/9178761.html
https://blog.csdn.net/qq_27384769/article/details/80331540
