目录
七、string.h库中的memcpy()和memmove()
在编译和链接之前,还需要对源文件进行一些文本方面的操作,比如文本替换、文件包含、删除部分代码等,这个过程叫做预处理,由预处理程序完成。
一、C 语言#include 的用法(文件包含命令)
#include 叫做文件包含命令,用来引入对应的头文件(.h 文件)。 #include 也是 C 语言预处理命令的一种。
#include 的处理过程很简单,就是将头文件的内容插入到该命令所在的位置,从而把头文件和当前源文件连接成一个源文件,这与复制粘贴的效果相同。
#include <sumjess.h>
#include "sumjess.h"使用尖括号< >和双引号" "的区别在于头文件的搜索路径不同:
- 使用尖括号< >,编译器会到系统路径下查找头文件;
- 而使用双引号" ",编译器首先在当前目录下查找头文件,如果没有找到,再到系统路径下查找。
也就是说,使用双引号比使用尖括号多了一个查找路径,它的功能更为强大。
二、C 语言宏定义(#define 的用法)
1、#define 的基础用法
#define 叫做宏定义命令,它也是 C 语言预处理命令的一种。所谓宏定义,就是用一个标识符来表示一个字符串,如果在后面的代码中出现了该标识符,那么就全部替换成指定的字符串。字符串可以是数字、表达式、 if 语句、函数等。
#define 用法的几点说明
1) 宏定义是用宏名来表示一个字符串,在宏展开时又以该字符串取代宏名,这只是一种简单粗暴的替换。字符串中可以含任何字符,它可以是常数、表达式、 if 语句、函数等,预处理程序对它不作任何检查,如有错误,只能在编译已被宏展开后的源程序时发现。
2) 宏定义不是说明或语句,在行末不必加分号,如加上分号则连分号也一起替换。
3) 宏定义必须写在函数之外,其作用域为宏定义命令起到源程序结束。如要终止其作用域可使用#undef 命令。
#define PI 3.14159
int main(){
// Code
return 0;
}
#undef PI5) 宏定义允许嵌套,在宏定义的字符串中可以使用已经定义的宏名,在宏展开时由预处理程序层层代换。
6) 习惯上宏名用大写字母表示,以便于与变量区别。但也允许用小写字母。
7) 可用宏定义表示数据类型,使书写方便。例如:
2、C 语言带参数的宏定义
对带参数的宏,在展开过程中不仅要进行字符串替换,还要用实参去替换形参。
带参宏定义的一般形式为:
#define 宏名(形参列表) 字符串#define MAX(a,b) (a>b) ? a : b3、对带参宏定义的说明
1) 带参宏定义中,形参之间可以出现空格,但是宏名和形参列表之间不能有空格出现。
2) 在带参宏定义中,不会为形式参数分配内存,因此不必指明数据类型。而在宏调用中,实参包含了具体的数据,要用它们去替换形参,因此实参必须要指明数据类型。
3) 在宏定义中,字符串内的形参通常要用括号括起来以避免出错。
#define SQ(y) y*y
sq = SQ(a+1);
与
SQ(y) (y)*(y)
sq = SQ(a+1);
最终结果是不一样的
由此可见,对于带参宏定义不仅要在参数两侧加括号,还应该在整个字符串外加括号以防出错。
4、用宏参数创建字符串:#运算符
C允许在字符串中包含宏参数。在类函数宏的替换体中,#号作为一个预处理运算符,可以把记号转换为字符串。
例如:如果x是一个宏形参,那么#x就是转换为字符串“x”的形参名。这个过程称为字符串化。
#define add2 (x) printf("the double of " #x " is %d.\n", ((x)*(x) )
int y=5 ;
add2(y);
输出结果:the double of y is 25.
add2(2+3);
输出结果:the double of 2+3 is 25.
转换流程:
printf("the double of " "y" " is %d.\n", ((y)*(y) );
printf("the double of y is %d.\n", 25 );
输出结果:the double of y is 25.5、预处理器粘合剂:##运算符
与#运算符类似,##运算符可用于类函数宏的替换部分。而且,##还可用于对象宏的替换部分。##运算符把两个记号组合成一个记号。
#include <stdio.h>
#define XN(n) x ## n
#define PRINTF_XN(n) printf("x" #n " = %d\n", x ## n);
int main(void)
{
int XN(1) = 3; 变成 int x1 = 3
int XN(2) = 2; 变成 int x2 = 2
int x3 = 1; 变成 int x3 = 1
PRINTF_XN(1); 变成 printf("x1 = %d\n", x1);
PRINTF_XN(2); 变成 printf("x2 = %d\n", x2);
PRINTF_XN(3); 变成 printf("x3 = %d\n", x3);
return 0;
}
结果
x1 = 3
x2 = 2
x3 = 16、变参宏:...和_ _VA_ARGS_ _
通过把宏参数列表中最后的参数写成省略号(即,3个点...)来实现这一功能。这样,预定义宏_ _VA_ARGS_ _可用在替换部分中,表明省略号代表什么。
#define PR(X,...) printf("message " #x ": "_ _VA_ARGS_ _)
int x= 5, y=9;
PR(1," x= %d,y=%d \n",x,y);
结果
message 1 : x=5,y=9三、其他指令
1、#undef指令
#undef指令用于“取消”已定义的#define指令。
#define PI 3.14159
int main()
{
Code 此处可以使用PI
return 0;
}
#undef PI “取消”已定义的#define指令(PI)。
void nono(void)
{
Code 此处无法再使用PI
}2、#ifdef、#else和#endif指令
#ifndef指令和#else、#endf搭配使用。
#ifdef MAVIS
#include "horse.h" 如果已经用了#define定义了MAVIS,则执行下面的指令
#define SABLE 5
#else
#include "cow.h" 如果没有用了#define定义了MAVIS,则执行下面的指令
#define SABLE 10
#endif 3、#ifndef指令
#ifndef指令也和#else、#endf搭配使用。
#ifndef SIZE
#defien SIZE 100 如果SIZE没定义,那么定义SIZE等于1000
#endif在头文件中我们常使用#ifndef指令避免文件被重复包含。
4、#if和#elif指令
#if和#elif也与#endif搭配,#if和#elif可以类比if 和else if。
defined是一个预处理运算符,如果它的参数被define定义过,则返回1,否则返回0。
#if defined (VAX) 等于 #ifdef VAX
#include "vax.h"
#elif defined (SEE)
#include "see.h"
#else
#include "all.h"
#endif5、预定义宏:
| 宏 |
意 义 |
| _ _DATE_ _ | 进行预处理的日期,“Mmm dd yyy”形式的字符串字面量,格式为 Nov 23 2013 |
| _ _FILE_ _ | 代表当前源代码文件名的字符串文字 |
| _ _LINE_ _ | 代表当前源代码文件中的行号的整数常量 |
| _ _STDC_ _ | 设置为1时,表示该实现遵循C标准 |
| _ _STDC_HOSTED_ _ | 为本机环境设置为1,否则为设为0 |
| _ _STDC_VERSION_ _ | 为C99时设置为199901L |
| _ _TIME_ _ | 源文件编译时间,格式为“hh:mm:ss” |
使用printf直接打印即可。
6、#line和#error指令
① #line指令重置_ _LINE_ _和_ _FILE_ _宏报告的行号和文件名。
#line 1000 把当前行号重置为1000
#line 10 “cllo.c” 把行号重置为10,把文件名重置为cllo.c② #error指令让预处理器发出一条错误信息,该消息包含指令中的文本。
#if _ _STDC_VERSION_ _ != 201112L 如果版本号不是C11
#error Not C11 报错Not C11
#endif四、数学库

使用说明:
五、通用工具库:
1、exit()和atexit()函数
exit()函数用于在程序运行的过程中随时结束程序,exit的参数state将会返回给操作系统,返回0表示程序正常结束,非0表示程序非正常结束。main函数结束时也会隐式地调用exit函数。exit函数运行时首先会执行由atexit()函数登记的函数,然后会做一些自身的清理工作,同时刷新所有输出流、关闭所有打开的流并且关闭通过标准I/O函数tmpfile()创建的临时文件。
- exit() 结束当前进程/当前程序/,在整个程序中,只要调用 exit ,就结束;
- exit(1)表示进程非正常退出. 返回 1给操作系统;
- exit(0)表示进程正常退出. 返回 0给操作系统.
atexit()函数--注册程序正常终止时要被调用的函数
按照ISOC的规定,一个进程可以登记多达32个函数,这些函数将由exit自动调用,通常这32个函数被称为终止处理程序,并调用atexit函数来登记这些函数。
在程序退出时经常需要做一些诸如释放资源的操作,但程序退出的方式有很多种。因此需要一种与程序退出方式无关的方法来进行程序退出时的必要处理。atexit()函数用来注册程序正常终止时要被调用的函数。
atexit的参数是一个函数指针,当调用此函数时无须传递任何参数,该函数也不能返回值,atexit函数称为终止处理程序注册程序,注册完成以后,当函数终止时exit函数会主动的调用前面注册的各个函数,但是exit函数调用这些函数的顺序与这些函数登记的顺序是相反的,我认为这实质上是参数压栈造成的,参数由于压栈顺序而先入后出。同时如果一个函数被多次登记,那么该函数也将多次的执行。
2、qsort函数
描述
C 库函数 void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *, const void*)) 对数组进行排序。
声明
下面是 qsort() 函数的声明。
void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *, const void*))
参数
- base -- 指向要排序的数组的第一个元素的指针。
- nitems -- 由 base 指向的数组中元素的个数。
- size -- 数组中每个元素的大小,以字节为单位。
- compar -- 用来比较两个元素的函数。
实例
下面的实例演示了 qsort() 函数的用法。
#include <stdio.h>
#include <stdlib.h>
int values[] = { 88, 56, 100, 2, 25 };
int cmpfunc (const void * a, const void * b)
{
return ( *(int*)a - *(int*)b );
}
int main()
{
int n;
printf("排序之前的列表:\n");
for( n = 0 ; n < 5; n++ ) {
printf("%d ", values[n]);
}
qsort(values, 5, sizeof(int), cmpfunc);
printf("\n排序之后的列表:\n");
for( n = 0 ; n < 5; n++ ) {
printf("%d ", values[n]);
}
return(0);
}
让我们编译并运行上面的程序,这将产生以下结果:
排序之前的列表:
88 56 100 2 25
排序之后的列表:
2 25 56 88 100
六、断言库
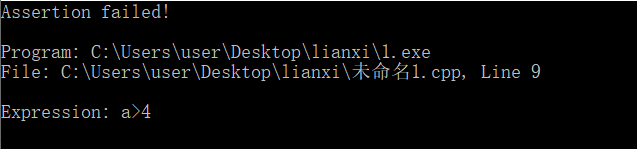
1、assert的用法
#include <stdio.h>
#include <assert.h>
int main(void)
{
int a = 3;
assert(a>4); //这里有错,因为3>4是错的。
return 0;
}
当我们修改完bug后,可以在assert.h前面,加上 #define NDEBUG。
2、_Static_assert
assert是编译运行后才显示错误,_Static_assert是编译的时候就显示。
#include <stdio.h>
#include <limits.h>
_Static_assert(a==16,"!!!这里有错!!!");
int main(void)
{
int a = 2;
return 0;
}![]()
七、string.h库中的memcpy()和memmove()
memcpy和memmove()都是C语言中的库函数,在头文件string.h中,作用是拷贝一定长度的内存的内容,原型分别如下:
void *memcpy(void *dst, const void *src, size_t count);
void *memmove(void *dst, const void *src, size_t count);
唯一的区别是,当内存发生局部重叠的时候,memmove保证拷贝的结果是正确的,memcpy不保证拷贝的结果的正确。
memmove在copy两个有重叠区域的内存时可以保证copy的正确,而memcopy就不行了,但memcopy比memmove的速度要快一些。
char s[] = "1234567890";
char* p1 = s;
char* p2 = s+2;
memcpy(p2, p1, 5)与memmove(p2, p1, 5)的结果就可能是不同的,
memmove()可以将p1的头5个字符"12345"正确拷贝至p2,而memcpy()的结果就不一定正确了.和memcpy相比,src和des有重叠的情况下,memmove可以保证数据的完整性.
memmove保证的原因很简单,就是针对重叠的情况做特殊处理,因此速度会比memcpy慢一些
具体解释见:https://blog.csdn.net/zhao_miao/article/details/82319093
