实验环境
整个代码我是在64位windows下的vscode中编写完成的,使用的是GBK编码格式,能够编译运行。但是编译器基于X86架构,使用的是IA-32指令集,所以生成的汇编代码只能在32位的操作系统下进行汇编和链接成可执行代码。经测试,代码可以在32位的Ubuntu16.04中编译运行并生成测试源程序的可执行代码。
参考书籍和工具
①《编译原理龙书》
②《编译原理虎书》
③《自制编译器》----青木峰郎[日]
④ GCC(代码生成关键参考)
文件结构
①globals.h 编译器关键数据结构
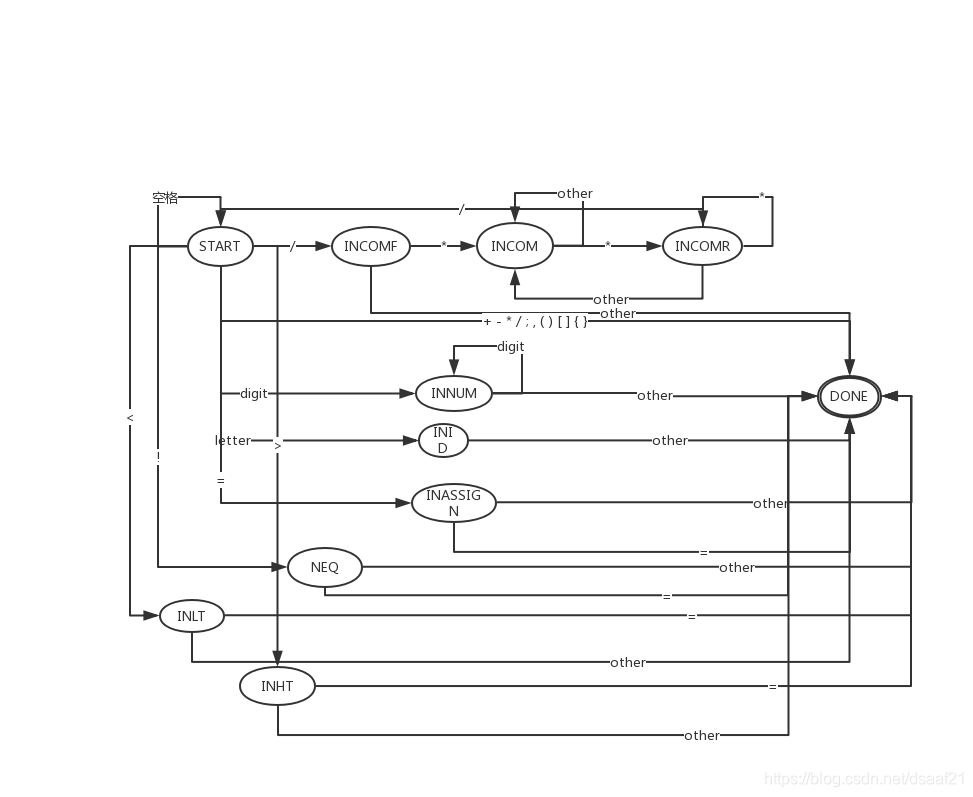
②cifa.h cifa.cpp 词法分析程序
③yufa.h yufa.cpp 语法分析程序
④yuyi.h yuyi.cpp 语义分析程序
⑤mid_code.h mid_code.cpp 中间代码生成程序
⑥Assembly_code.h Assembly_code.cpp 汇编代码生成程序
⑦main.cpp 主函数,调用编译器各部分完成整个编译过程并生成源程序的可执行程序
Tokens.txt:词法分析输出的记号流
Tree.txt:语法分析输出的抽象语法树
symbol_table.txt:语义分析输出的符号表
code.txt:中间代码
text.txt:测试源码
main.s:测试源码生成的汇编代码
简单cminus词法语法规则
参见文后githup链接
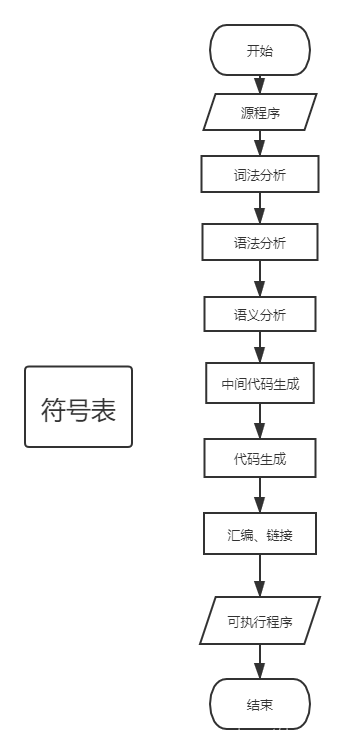
编译流程图
关键数据结构
词法分析数据结构
/*****c-语言惯用的词法******/
typedef enum
{
ENDFILE,ERROR,
/* 保留字 */
IF,ELSE,INT,RETURN,WHILE,VOID,
/*标识符、数字*/
ID,NUM,
/* special symbols */
PLUS,MINUS,TIMES,OVER,LT,LTE,HT,HTE,EQ,NEQ,ASSIGN,SEMI,COM,LPAREN,RPAREN,MLPAREN,MRPAREN,LLPAREN,LRPAREN
/* + - * / < <= > >= == != = ; , ( ) [ ] { } */
} TokenType;
c-语言所有的记号,使用枚举类型表示
词法分析DFA
语法分析数据结构
/************抽象语法树结点类型***********/
typedef enum {
VAR_DECK,FUN_DECK,INTK,VOIDK,IDK,NUMK,PARAMK,COM_SK,
IFK,WHILEK,RETURNK,RELOPK,ADDOPK,MULOPK,ARRK,ARR_ELEMK,
CALLK,ARGK,ASSIGNK
}NodeKind;
/***********抽象语法树结点的数据结构**********/
typedef struct treeNode{
struct treeNode * child[5];
struct treeNode * sibling;
int lineno;//行数
NodeKind nodekind;
string val;
ExpType type;//语义分析类型检查使用,结点类型
//int tmp_loc;//中间代码生成使用,临时变量索引,-1非临时变量,>=0临时变量,表示在tmp_var中的索引
bool is_deal;//中间代码生成使用,该节点是否已经生成过中间代码
} TreeNode;
根据上下文无关文法,一个树节点最多有三个子节点,兄弟结点数量不一定。使用lineno指明该节点在源码中的行数,val是该节点该源码中对应的字符串,保留字无val。nodekind表示该节点的类型,由枚举类型NodeKind定义。成员type,is_deal在语法分析过程中不需要使用
语义分析数据结构
/************数据类型**************/
typedef enum {Void,Integer,Boolean,Integer_arr} ExpType;
/************函数的符号表,记录参数的个数,每个参数的类型以及返回类型***************/
typedef struct Fun_sys
{
int p_num;// 参数的个数
vector<ExpType> p_type;//每个参数的类型
ExpType return_type;
int stack_size=0;//函数栈的大小
} Fun_sym;
/*************记录变量的作用域、内存位置、类型************/
typedef struct LineListRec
{
int linepoc=0;//在源码中的行数
int loc;//内存中的位置,当为参数时表示参数的位置
int scope;//作用域,0--全局变量
ExpType ty;//类型
int sizes;//变量的大小
} LineList;
/**********同一行数中,所有相同名字ID的作用域**********/
typedef struct Var_sys
{
vector<LineList> lines;
} Var_sym;
extern map<string,Fun_sym> fun_table;//所有函数的符号表,记录返回类型,参数个数,每个参数的类型
extern map<string,map<string,Var_sym> > sys_table;//函数中变量的符号表,key为函数名,value为变量的符号表
c-语言语义,可能不全
1.变量声明只能使用int;函数声明可使用int,void,无数组类型
2.所有的变量和函数在使用前必须声明 ,注意变量的作用域
3.程序中最后的声明必须是一个函数声明,名字为 main
4.return 语句返回值和函数声明的类型一致
5.函数在调用之前必须声明, 声明中参数的数目必须等于调用中参数的数目 ,并且类型相同,避免重定义
6.加减乘除,比较 符号两边必须是整型
7.if 语句有通常的语义:表达式进行计算;非 0 值引起第一条语句的执行;0 值引起第二条语 句的执行,如果它存在的话
8.while 语句也要对表达式求值
9.赋值符号两边类型相同 ,不能出现数组指针赋值
10.局部声明的作用域等于复合语句的语句列表,并代替任何全局声明
11.不允许在函数调用的参数中出现函数调用,简化处理
12.除法运算的除数出现数字时不能为0
13.考虑两个在全局环境中预定义的函数,它们已进行了声明:
int input(void)
void output(int x)
input 函数没有参数,从标准输入设备 (通常是键盘)返回一个整数值
output 函数接受 一个整型参数,其值和一个换行符一起打印到标准输出设备
语义分析主要是要生成符号表,为各个变量分配好栈中地址,计算函数栈的大小。
使用变量时要找出正确作用域中声明的变量,因为可能存在同一名字的变量在不同的作用域被声明,这是重点也是难点。为此,可以使用一个栈来保存当前可以访问的所有作用域,每进入一个花括号,作用域加一,同时将该作用域压栈,退出花括号时,栈顶作用域出栈。全局域的作用域为0,函数的作用域从1开始,函数参数中的作用域为1,以此递增。退出函数时,作用域归0。这样,栈顶作用域为当前作用域,栈中的所有作用域为当前可以访问的作用域,在这些作用域中寻找最近声明的变量作为使用的变量。
int v(int s){
return 2;
}
int a[12];
{
int a;
int b;
a=1;
}
b=3;
v(a);
比如上述代码就存在语义错误,语义分析需要准确找出使用的变量是哪个作用域声明的变量,是否使用正确。
每个函数都有一个符号表,全局域GLOBALS有一个符号表
中间代码生成数据结构
typedef enum {
ERROR_CODE,
/**无参数三地址码符号***/
FUNCTION_CODE,GLOBAL_VAL_CODE,LABELS_CODE,
/*********函数调用相关************/
CALL_CODE,PUTPARAM_CODE,RETURN_CODE,
/**********if,while相关***************/
IF_CODE,GOTO_CODE,
/*****二元运算符*****/
PLUS_CODE,MINUS_CODE,TIMES_CODE,OVER_CODE,LT_CODE,LTE_CODE,HT_CODE,HTE_CODE,EQ_CODE,NEQ_CODE,
/******赋值运算******/
ASSIGN_CODE,
/********数组访问**********/
ARRAY_CODE
}Mid_code_type;//中间代码结点类型
typedef struct name_2_loc{
string id_string; //变量名字 tmp表示临时变量
int is_global_tmp;//该变量是否属于全局域(0),局部变量(1),还是临时变量(2)
bool is_num;//该参数是否为整数
int loc ;
/*
loc=-2,表示函数调用后的返回值
loc=-1,表示为参数
is_num为false时:
is_global_tmp=2,tmp_var中索引
is_global_tmp=1,栈中位置
is_global_tmp=0,只记录id_string,其他均为0
is_num为true:整数值;
*/
int array_loc;
/*
数组中的位置,当为普通变量时,值为0;
当loc=-1时,表示该变量为参数,此时array_loc表示第几个参数
*/
bool is_array=false;
/*
标识ID是否为数组,当ID为数组时,函数调用的过程中使用leal指令加载数组首地址
leal 数组首地址,%eax
is_array供生成汇编代码时,函数调用压参使用
同时is_array也用来处理数组元素赋值
*/
}Args;
typedef struct Mid
{
// int line=0;//源码中的行数
string label="";//该指令前是否有标号
Mid_code_type op; //操作符
Args arg1; //参数字段
Args arg2;
int putparam_pos=0;//三地址码位putparam时,压栈参数在函数调用栈中保存的位置
}Instruction; //三地址码三元式表示
typedef struct Code{
string fuction;//函数名称
int stack_size;//栈的大小
int max_param_size;//为函数调用参数预留的最大栈空间
vector<Instruction> ins;//三地址码指令序列
}code;//函数中的所有三地址码,按执行顺序排列
extern map<string,vector<Args> > tmp_var;//保存临时变量
extern vector<code> my_code;
中间代码使用的形式为三地址码,使用了间接三元式来表示三地址码,相关理论见龙书6.2节。中间表示也可以使用树的形式,虎书和自制编译器都是使用树的形式作为中间表示形式。中间主要是优化和软件工程的角度有用处,不优化的话可以直接跳过生成汇编。三地址码和汇编代码形式上很像,设计一个良好的数据结构存储和表示三地址码可以更快地生成汇编代码。
因为变量可能在多处声明,所有三地址码中使用变量在栈中的偏移量唯一表示一个变量。在栈中需要留下位置给函数调用过程中参数压栈处理,所以变量偏移不从0开始。max_param_size是为函数调用预留的最大栈空间,最小值为12,因为input函数中,输入的值存放在8(%esp)中,0(%esp)、4(%esp)分别存放两个参数,具体调用参见gcc。
Args成员array_loc仅仅作为参数在函数调用的位置使用
代码生成无需定义数据结构,只需分配寄存器
代码生成
学习汇编代码最好的方式是通过gcc生成的汇编代码,并修改相应的汇编代码为同义汇编,多看多写。X86架构IA-32指令集只有8个通用寄存器,每个通用寄存器都是32位的,每个寄存器都有自己的用途:
| 寄存器 | 特殊用途 |
|---|---|
| EAX | 累加器accumulator。操作数的累加器/计算结果数据 |
| EBX | 基址寄存器base。指向DS段中的数据 |
| ECX | 计数器counter。字符串/循环操作的计数器 |
| EDX | I/O指针 |
| ESI | 指向DS段中的数据;字符串操作时的源操作数指针 |
| EDI | 指向ES段中的数据(目标);字符串操作时的目的操作数指针 |
| ESP | 指向SS段栈顶 |
| EBP | 指向SS段栈中的数据 |
该编译器较简单,不需要使用寄存器分配算法,只需将各个寄存器分配给特定的用途,在我的编译器中各个寄存器的用途如下:
edx寄存器存放临时变量,eax寄存器存放函数返回值,ecx寄存器存放if语句的测试条件值
ebx寄存器用于加减乘运算保存运算左值,edx保存加减乘运算右值
eax,esi寄存器用于处理除法运算,edx保存除法运算结果
比较运算符,ebx保存第一操作数的值,edx保存第二操作数的值,结果保存在edx中
edi保存数组元素在栈中地址
edi,esi用于处理数组元素访问操作
ebp,esp函数栈底栈顶指针
汇编中各个段的作用
| 段 | 作用 |
|---|---|
| bss段 | BSS段通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文BlockStartedby Symbol的简称。BSS段属于静态内存分配。 |
| data段 | 数据段通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。 |
| text段 | 代码段通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读,某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。 |
| rodata段 | 存放C中的字符串和#define定义的常量 |
| heap堆 | 堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。 |
| stack栈 | 是用户存放程序临时创建的局部变量 |
主函数
int errors1=0;
int main(int argc, char * argv[]){
string file_name; /* 源程序名字 */
if (argc != 2)
{
fprintf(stdout,"usage: %s <filename>\n",argv[0]);
exit(1);
}
file_name=argv[1];
if(file_name.find(".")==string::npos)file_name+=".txt";
cout<<"词法分析"<<endl;
cifa_parse(file_name);
cout<<"词法分析完成\n"<<endl;
TreeNode* tree;
if(!errors1){
cout<<"语法分析"<<endl;
tree=yufa_parse();
cout<<"语法分析完成\n"<<endl;
}
else {cout<<"\t词法分析错误,编译提前终止"<<endl;return 0;}
if(!errors1){
cout<<"语义分析"<<endl;
yuyi_parse(tree);
cout<<"语义分析完成\n"<<endl;
}
else {cout<<"\t语法分析错误,编译提前终止"<<endl;return 0;}
if(!errors1) {
cout<<"生成中间代码"<<endl;
mid_code_parse(tree);
cout<<"生成中间代码完成\n"<<endl;
cout<<"生成汇编代码"<<endl;
assembly_code_parse();
cout<<"生成汇编代码完成,生成的汇编指令保存在main.s中\n"<<endl;
system("as main.s -o main.o"); //完成汇编
system("gcc main.o -o final"); //使用gcc完成连接
//链接和汇编都得在32位的操作系统中,使用的是X86架构,IA-32指令集
}
else {cout<<"\t语义分析错误,编译提前终止"<<endl;return 0;}
return 0;
}
依次进行词法分析、语法分析、语义分析、中间代码生成、代码生成,生成了汇编代码后,用system函数调用linux的终端完成汇编和链接,最后生成可执行代码。汇编使用的使用linux中的as汇编器,而链接使用的是gcc。后面我会修改成使用链接器ld来进行链接。
该博客我只讲解了一些我认为在自制编译器过程中的重点和难点,设计数据结构是关键,一个良好的数据结构能够让自制编译器的过程事半功倍,所以得多花点心思来设计数据结构,并且得从整体来编写代码,不用拘泥于某个部分。我认为自制编译按照难度排列为:中间代码生成>语义分析>语法分析>代码生成>词法分析。GCC很关键,能够帮助我们更好的理解汇编代码,多使用gcc生成汇编并换另一种汇编代码来表示同一语义的汇编能够更快地学习汇编代码
