#!/usr/bin/python
#encoding:utf-8
"""
@author: LlQ
@contact:[email protected]
@file:ipFreeProxyEn.py
@time: 10/1/2019 12:13 PM
"""
#!/usr/bin/python
#encoding:utf-8
"""
@author: LlQ
@contact:[email protected]
@file:ipFreeProxyDotCZ.py
@time: 9/13/2019 3:10 AM
"""
#Under the Anaconda Prompt
#pip install fake-useragent
from fake_useragent import UserAgent
from selenium import webdriver
from lxml import etree
import pandas as pd
import re
import numpy as np
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import json
import pprint # for print dict structure
import copy
import telnetlib
import requests
from selenium.webdriver.support.select import Select
from time import sleep
import urllib.request
domainList=["http://free-proxy.cz"]
domain = domainList[0]
base="/en/proxylist/main/1"
#print(domain+base)
#####responding to anti-crawler
userAgent=UserAgent()
#print(userAgent.random)
#Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1309.0 Safari/537.17
#The actual userAgent
# (right click your mouse then select Inspection
# and then you can find it from Headers by clicking any elementName Under the Name in Network )
header = {'UserAgent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
'Connection':'close'#countryNameRaw
}
#print(header['UserAgent'])
#Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
options = webdriver.ChromeOptions()
options.add_argument("'user-agent=" + header['UserAgent'] + "'")
options.add_argument('--diable-gpu') # google document mentioned this attribute can avoid some bugs
options.add_experimental_option('excludeSwitches',['enable-automation'])
#set the browser as developer model, prevent the website identifying that you are using Selenium
#browser = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver',
# chrome_options=options)
#run command("window.navigator.webdriver")in the Console of the inspection
#result: undefine # means: regular browserclass GetIp():
def __init__(self, domain=domain, baseUrl=base):
self.domain = domain
self.url = self.domain + str(baseUrl)
self.browser = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver',
chrome_options=options
)
from selenium.webdriver.support.ui import WebDriverWait
self.wait = WebDriverWait(self.browser, 2)
def __del__(self):
# self.browser.close() # close current browser's window or tab
self.browser.quit() # close browser
def get_webpagecontent(self):
print(self.url)
# import requests
# Python requests appear "HTTPConnectionPool Max retires exceeded"
# requests.session().keep_alive=False
# requests.adapters.DEFAULT_RETRIES = 5
self.browser.keep_alive = False
self.browser.DEFAULT_RETRIES = 5
self.browser.get(self.url)
# from selenium.webdriver.support import expected_conditions as EC
# from selenium.webdriver.common.by import By
self.wait.until(EC.presence_of_element_located((By.ID, "proxy_list")))
pageSource = self.browser.page_source
return pageSource
def parse_webData(self, pageSource):
# get ip Data and save it into a dataframe
df = pd.read_html(pageSource, header=0)[1]
# print(df)
# import re
selector = etree.HTML(pageSource)
countryDict = {}
# locate to the selection box on webpage
time.sleep(.5)
countryNameRaw = selector.xpath('//select/option/text()')
# get country name's Abbreviation
countryAbbreviations = selector.xpath('//select/option/@value')
# create a dictionary{countryName:countryAbbreviations}
for i in range(2, len(countryNameRaw)):
# get country name
countryName = re.findall('[\u4e00-\u9fa5_a-zA-Z]+', countryNameRaw[i])[0]
# create a dictionary{countryName:countryAbbreviations}
countryDict[countryName] = countryAbbreviations[i]
for r in range(df.shape[0]):
# get Ip Address
ipAddress = re.findall(r'\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b', df.loc[r, 'IP address'])
if len(ipAddress) == 0:
df.drop([r], inplace=True) # drop the row in which there not exist ip data
else:
df.loc[r, 'IP address'] = ipAddress[0]
# get Port
port = re.findall(r'\b[0-9]+\b', str(df.loc[r, 'Port']))[0]
df.loc[r, 'Port'] = port
if df.loc[r, 'Country'] in countryDict.keys():
# countryName, countryAbbreviations #United States, US
df.loc[r, 'Country'] = df.loc[r, 'Country'] + ", " + countryDict[df.loc[r, 'Country']]
# import numpy as np
if pd.isnull(df.loc[r, 'Region']) and pd.isnull(df.loc[r, 'City']):
# df.loc[r,'Region']=np.nan#pd.NaT
# df.loc[r,'City']=np.nan#pd.NaT
df.loc[r, 'Location'] = np.nan
elif pd.isnull(df.loc[r, 'Region']) and pd.isnull(df.loc[r, 'City']) == False:
df.loc[r, 'Location'] = df.loc[r, 'City']
elif pd.isnull(df.loc[r, 'Region']) == False and pd.isnull(df.loc[r, 'City']):
df.loc[r, 'Location'] = df.loc[r, 'Region']
else:
df.loc[r, 'Location'] = df.loc[r, 'Region'] + ", " + df.loc[r, 'City']
df.drop(['Region', 'City'], axis=1, inplace=True)
df.columns = ['IP Address', 'Port', 'Protocol', 'Country', 'Anonymity',
'Speed', 'Available', 'Response Time', 'Update', 'Location']
return df, countryDict # main page ip data and country Dict
def crawler(self, pageNumber=0): # get first 3 pages' data
# current page
# pageNumber = 0
pageSource = self.get_webpagecontent()
ipDataFrame, countryDict = self.parse_webData(pageSource)
# print(ipDataFrame)
hasNextPage = False
# from lxml import etree
selector = etree.HTML(pageSource)
try:
time.sleep(.5)
# nextPageUrl = selector.xpath('//div[@class="pagination"]/a[contains(text(),"Next »")]/@href')[0]
nextPageUrl = selector.xpath('//div[@class="paginator"]/a[last()]/@href')[0]
if nextPageUrl:
hasNextPage = True
except:
# print("No next page!")
return ipDataFrame
while hasNextPage and pageNumber < 2:
self.url = self.domain + nextPageUrl
pageSource = self.get_webpagecontent()
pageNumber = pageNumber + 1
###
currentIpDataFrame, countryDict = self.parse_webData(pageSource)
# combine two dataframe
ipDataFrame = pd.concat([ipDataFrame, currentIpDataFrame])
hasNextPage = False
selector = etree.HTML(pageSource)
try:
# nextPageUrl = selector.xpath('//div[@class="pagination"]/a[contains(text(),"Next »")]/@href')[0]
nextPageUrl = selector.xpath('//div[@class="paginator"]/a[last()]/@href')[0]
if nextPageUrl:
hasNextPage = True
except:
break
return ipDataFrame
def execute2(self): # get at most (first) 5 pages's data for each value on selection('country')
pageSource = self.get_webpagecontent()
self.browser.implicitly_wait(2)
selector = etree.HTML(pageSource)
# get all values belonging to select tag
countryAbbreviations = selector.xpath('//select/option/@value')
# print(countryAbbreviations)
#from selenium.webdriver.support.select import Select
# from selenium.webdriver.common.action_chains import ActionChains #import mouse action event package
#from time import sleep
selectionBox = self.browser.find_element_by_id('frmsearchFilter-country')
# Select(selectionBox).select_by_value("BT")
# Select(selectionBox).select_by_value("MO")
# ipCrawler.browser.find_element_by_name("send").click()
counterCountry = 0
ipDataFrame = None # create a empty dataframe
for value in countryAbbreviations:
if value != 'all' and counterCountry < 5:
Select(selectionBox).select_by_value(value)
self.browser.find_element_by_name("send").click()
self.url = self.browser.current_url # reset url since each page's url is different
if ipDataFrame is None:
ipDataFrame = self.crawler()
else:
ipDataFrame = ipDataFrame.append(self.crawler(), ignore_index=True)
sleep(2)
counterCountry = counterCountry + 1
# since each page's select tag is a instance
selectionBox = self.browser.find_element_by_id('frmsearchFilter-country')
self.browser.quit() # close browser
return ipDataFrame
def execute(self, country='all', protocol='all',
anonymity='all'): # get at most (first) 5 pages's data for each value on selection('country')
pageSource = self.get_webpagecontent()
self.browser.implicitly_wait(2)
selector = etree.HTML(pageSource)
# get all values belonging to select tag
countryAbbreviations = selector.xpath('//select/option/@value')
# print(countryAbbreviations)
from selenium.webdriver.support.select import Select
# from selenium.webdriver.common.action_chains import ActionChains #import mouse action event package
import time
time.sleep(.5)
selectionBox = self.browser.find_element_by_id('frmsearchFilter-country')
Select(selectionBox).select_by_value(country)
protocolButton = self.browser.find_element_by_xpath('//input[@value="{}"]'.format(protocol))
protocolButton.click()
anonymityButton = self.browser.find_element_by_xpath('//input[@value="{}"]'.format(anonymity))
anonymityButton.click()
# Filter proxies
self.browser.find_element_by_name("send").click()
self.url = self.browser.current_url # reset url since each page's url is different
ipDataFrame = self.crawler()
self.browser.quit() # close browser
return ipDataFrame
def ipData_to_file(self, fileName, ipDataFrame):
import json
import sys
# set the column "IP Address" as the index of dataframe
# and I will use this index as key of a dict
ipDataFrame.set_index('IP Address', inplace=True)
# convert dataframe to json string #since the dataframe is not using ascii
ipJsonStr = ipDataFrame.to_json(orient='index', force_ascii=False) # type: str
# convert json string to json dict
ipJsonDict = json.loads(ipJsonStr) # type: dict
# save dict to a file #sys.stdout.encoding=='utf-8' since my system using utf-8
with open(fileName, 'w', encoding=sys.stdout.encoding) as f:
ipDataDF = json.dump(ipJsonDict, f, ensure_ascii=False)
f.write('\n')
def getIpData_from_file(self, fileName):
with open(fileName, 'r', encoding='utf-8') as f:
ipJsonDict = json.load(f)
return ipJsonDict
def getSpecifedIpList_from_nestedJsonDict(self, jsonDict, innerKey, innerValue):
return [k for k, v in jsonDict.items() if v[innerKey] == innerValue]ipCrawler=GetIp(domain,base)
#level1:High #level2:Anonymous #level3:Transparent

ipDataFrame=ipCrawler.execute(country='US',protocol='http',anonymity='level1')
ipDataFrame


Write ip data to file
ipCrawler.ipData_to_file('ipDataFrame.txt',ipDataFrame)

Read ip data from specified file and save them in a nested dict
ipDataDict=ipCrawler.getIpData_from_file('ipDataFrame.txt')
ipDataDict

import pprint #for print dict structure
pprint.pprint(ipDataDict)

get the detail by a specifed ip addresss
ipDataDict['104.152.45.45'] #get ip detatil by a specifed ip addresss

get an ip list by specifed location
ipList=ipCrawler.getSpecifedIpList_from_nestedJsonDict(ipDataDict,'Location','California, Los Angeles')
ipList
![]()
Convert the nested dict to a dataframe
import pandas as pd
dataframe = pd.DataFrame(ipDataDict)
dataframe

gives a name to the row which the columnName on
dataframe.columns.name="IP Address"
dataframe

current dataframe does transpose
import copy
ipDataframe=copy.deepcopy(dataframe.T)
ipDataframe[:5]
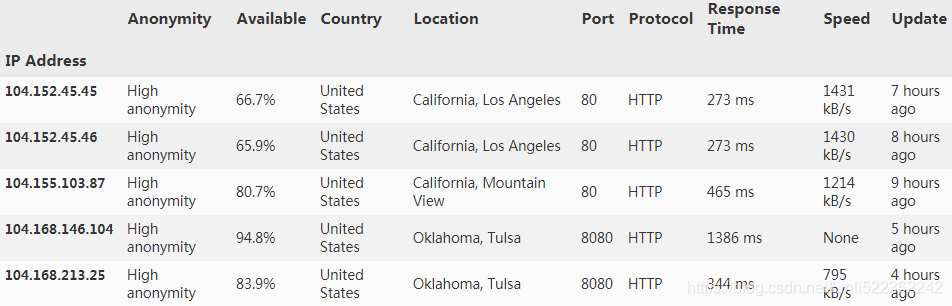

extract the numerical value and rename the columnName of dataframe
for ip in ipDataframe.index:
speed = re.findall( '[0-9]+', str(ipDataframe.loc[ip,'Speed']) )
if len(speed)!=0:
ipDataframe.loc[ip,'Speed'] = int(speed[0])
else:
ipDataframe.loc[ip,'Speed']=np.nan
response = re.findall( '[0-9]+', str(ipDataframe.loc[ip,'Response Time']) )
if len(response)!=0:
ipDataframe.loc[ip,'Response Time'] = int(response[0])
else:
ipDataframe.loc[ip,'Response Time']=np.nan
update = re.findall( '[0-9]+', str(ipDataframe.loc[ip,'Update']) )
if len(update)!=0:
ipDataframe.loc[ip,'Update'] = int(update[0])
else:
ipDataframe.loc[ip,'Update']=np.nan
ipDataframe.columns= [ 'Anonymity','Available', 'Country', 'Location', 'Port', 'Protocol',
'Response(ms)','Speed(KB/s)', 'Update(hours ago)']
columnOrder= [ 'Port','Protocol','Anonymity','Available', 'Country', 'Location',
'Response(ms)','Speed(KB/s)', 'Update(hours ago)']
ipDataframe=ipDataframe[columnOrder]
ipDataframe[:10]

sort the dataframe
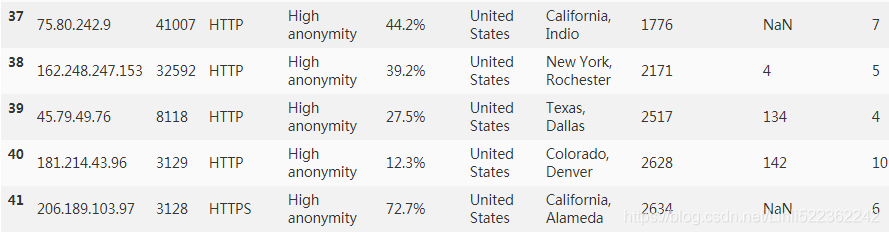
ipDataframe=ipDataframe.sort_values(by=['Speed(KB/s)'],ascending=False)
ipDataframe=ipDataframe.sort_values(by=['Response(ms)','Update(hours ago)'],ascending=True)
ipDataframe[:5]

convert the first column(or index column) to a regular column
ipDataFrame = ipDataframe.reset_index()
ipDataFrame[:10]
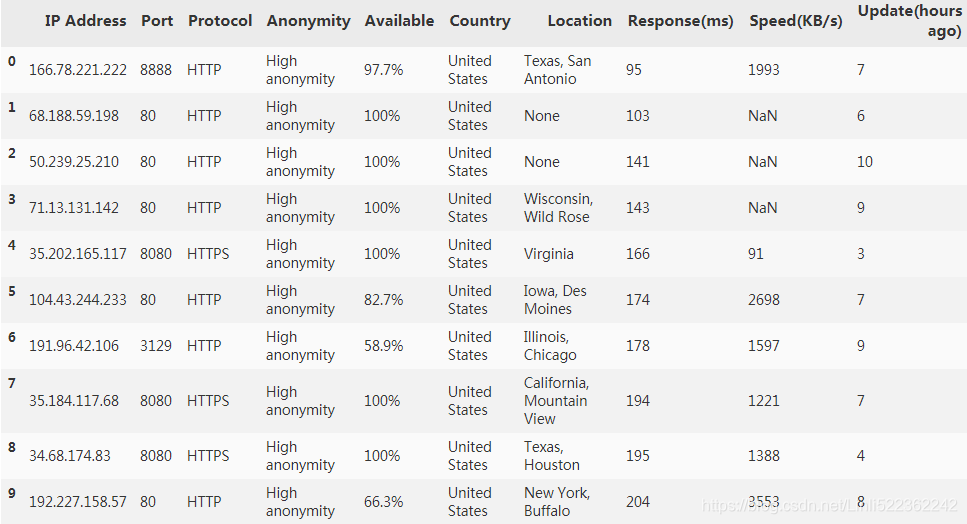
test ip dataframe for selecting an ip list without using your computer's used port
availableIPportDF= pd.DataFrame(columns=ipDataFrame.columns.values) # create a empty dataframe with columnNames
#availableIPportDF.colulmns=ipDataFrame.columns
availableIPportDF
![]()

import telnetlib
ifValid=False
for r in ipDataFrame.index:
try:
telnetlib.Telnet(ipDataFrame.at[r,'IP Address'], ipDataFrame.at[r,'Port'], timeout=2)
print(ipDataFrame.at[r,'IP Address']+ ": "+ipDataFrame.at[r,'Port'])
availableIPportDF=availableIPportDF.append(ipDataFrame.iloc[r])
except:
ifValid=False
availableIPportDF


availIPportDF=availableIPportDF.reset_index(drop=True)
availIPportDF


import requests

avail2IPportDF= pd.DataFrame(columns=ipDataFrame.columns.values) # create a empty dataframe with columnNames
header = {'UserAgent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
'Connection':'close'#'keep-alive'
}
proxy={} #dict
for r in availIPportDF.index:
proxy[availIPportDF.at[r,'Protocol'].lower()] = availIPportDF.at[r,'Protocol'].lower() + "://" +\
availIPportDF.at[r,'IP Address'] + ":" +\
availIPportDF.at[r,'Port']
attempts=0
success=False
while attempts <1 and success==False:
try:#Note: try is not just one time
attempts+=1
page = requests.get('http://icanhazip.com', headers=header, proxies=proxy)
#from lxml import etree
#page.text='165.22.45.183\n'
#currentIp=165.22.45.183
currentIP=re.findall(r'\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b',page.text)[0]
if currentIP == availIPportDF.at[r,'IP Address'] :
success=True
#print("current IP: "+currentIP)
#print("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~")
except:#Maximum number of open connections reached.
#OR
#<title>ERROR:The requested URL could not be retrieved</title>
#OR
#ERR_PROXY_CONNECTION_FAILED
success=False
attempts+=1
#print("current IP: "+currentIP+" fail!")
#current IP: 191.96.42.82 has been attended to the avail2IPportDF
#current IP: 191.96.42.82 fail!
#[~]drop the current IP if the current IP in the new dataframe
avail2IPportDF=avail2IPportDF[~avail2IPportDF['IP Address'].isin([currentIP])]
#print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
break
else:
avail2IPportDF=avail2IPportDF.append(availIPportDF.loc[r])
#avail2IPportDF.append(availIPportDF.loc[0])
#go to use next ip
sleep(2)
avail2IPportDF

#use website https://www.ipip.net/ip.html to test ip again since 'Hign anonymity'#########
#and
#import urllib.request
#from lxml import etreeimport urllib.request
from lxml import etree
domain='https://en.ipip.net/ip/'
avail2IPportDF=avail2IPportDF.reset_index(drop=True)
for index in avail2IPportDF.index:
currentIP = avail2IPportDF.at[index,'IP Address']
currentPort = avail2IPportDF.at[index,'Port']
currentProtocol = avail2IPportDF.at[index,'Protocol']
proxyStr='{}:{}'.format(currentIP,currentPort)
proxyDict={}
proxyDict[currentProtocol]=proxyStr
proxy_support = urllib.request.ProxyHandler(proxyDict)
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36')]
#req = urllib.request.Request(url)
#response = opener.open(req)
#OR
urllib.request.install_opener(opener)
response = urllib.request.urlopen(domain + currentIP + '.html')
html = response.read().decode('utf-8')
from lxml import etree
selector = etree.HTML(html)
ip = selector.xpath('//a[contains(@style,"color: #000;")]/text()')[0]
location = selector.xpath('//td[contains(text(),"Location")]/../td[2]/span/text()')[0]
if(ip==currentIP):
print(currentIP + ":" + avail2IPportDF.at[index,'Country'] + ',' + avail2IPportDF.at[index,'Location'])
print(" "+location)
else:
print('False')

Besides,

I find that the result(location) in some ip address is different with IP location in my dataset/dataframe
Besides, using different ip locator(such as baidu.com) will display another different ip address(112.213.104.1) and location after setting up ip(165.22.235.89) proxy

#####################################西刺代理#####################################
#Under the Anaconda Prompt
#pip install fake-useragent
from fake_useragent import UserAgent
from selenium import webdriver
urlList=["https://www.xicidaili.com/nn"]
url = urlList[0]
header={'UserAgent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/75.0.3770.100 Safari/537.36"}
options = webdriver.ChromeOptions()
options.add_argument("'user-agent=" + header['UserAgent'] + "'")
options.add_argument('--diable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
options.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver',
chrome_options=options
)
browser.get(url)
pageSource=browser.page_source
print(pageSource)

import pandas as pd
df1 = pd.read_html(pageSource, header=0)[0]
df1[:5]

df1.columns = ['Country', 'IP Address', 'Port', 'Server Address', 'Anonymous',
'Type', 'Speed', 'Response Time', 'Available','Update']
df1[:5]


from lxml import etree
selector = etree.HTML(pageSource)
for r in range(df1.shape[0]):
#for c in range(df1.shape[1]):
if pd.isnull(df1.loc[r,'Country']):
#xpath cost time, so we need to run several time
try:
cn=selector.xpath('//table[@id="ip_list"]/tbody/tr[{0}]/td[@class="country"]/img/@alt'.format(r+2))[0]
#print(cn) #Cn
except:
print("run again")
df1.loc[r,'Country']=countryDict[cn.lower()]
if df1.loc[r,'Anonymous'] in anonymousDict.keys():
df1.loc[r,'Anonymous'] = anonymousDict[ df1.loc[r,'Anonymous'] ]
try:
speed = selector.xpath('//table[@id="ip_list"]/tbody/tr[{0}]/td[@class="country"]/div/@title'.format(r+2))[0]
df1.loc[r,"Speed"]=speed
except:
print("speed")
try:
res = selector.xpath('//table[@id="ip_list"]/tbody/tr[{0}]/td[@class="country"]/div/@title'.format(r+2))[1]
df1.loc[r,"Response Time"] = res
except:
print("response")
df1.head()

from lxml import etree
selector = etree.HTML(pageSource)
data = selector.xpath('//table[@id="ip_list"]/tbody/tr[1]/th[@class="country"]/text()')
data
![]()
data = selector.xpath('//table[@id="ip_list"]/tbody/tr[2]/td[@class="country"]/img/@alt')[0]
data
![]()
data = selector.xpath('//table[@id="ip_list"]/tbody/tr[2]/td[@class="country"]/div/@title')[0]
data
![]()
data = selector.xpath('//table[@id="ip_list"]/tbody/tr[2]/td[contains(text(),"222.89.32.140")]/../td[@class="country"]/div/@title')[0]
data
![]()

#############################Class##################################
#!/usr/bin/python
#encoding:utf-8
"""
@author: LlQ
@contact:[email protected]
@file:ipProxy.py
@time: 9/7/2019 3:04 AM
"""
#https://www.cnblogs.com/Micro0623/p/10905193.html
#https://www.cnblogs.com/jackadam/p/9293569.html
#http://www.mamicode.com/info-detail-2694399.html
#https://www.cppentry.com/bencandy.php?fid=77&id=213146
#https://sites.google.com/a/chromium.org/chromedriver/capabilities
#https://blog.csdn.net/zwq912318834/article/details/78933910
#https://github.com/stormdony/python_demo/tree/master/TaoBao_Login
#Under the Anaconda Prompt
#pip install fake-useragent
from fake_useragent import UserAgent
from selenium import webdriver
from lxml import etree
import pandas as pd
domainList=["https://www.xicidaili.com"]
domain = domainList[0]
url = '/nn/3818'
###########responding to anti-crawler
#####UserAgent
userAgent = UserAgent()#User agent, or ua, is a special string header that enables the server
# to identify the operating system and version, cpu type,
# browser and version, browser rendering engine, browser language,
# browser plug-in, etc. used by the client.
#print(userAgent.ie) #Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64;
# Trident/4.0; SLCC2; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8
#print(userAgent.firefox)
#Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/25.0
#print(userAgent.chrome) #Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36
# (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36
#print(userAgent.random) #Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko)
# Chrome/27.0.1453.90 Safari/537.36
###########responding to anti-crawler
#actual User-Agent
# (right click your mouse then select Inspection
# and then you can find it from Headers by clicking any elementName Under Name in Network )
header={'UserAgent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/75.0.3770.100 Safari/537.36"}
#print(header['UserAgent']) #check
#from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("'user-agent=" + header['UserAgent'] + "'")
options.add_argument('--diable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
#options.add_argument('disable-infobars')# 去掉提示:Chrome正收到自动测试软件的控制
#browser = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver')
#chrome_options=options)
#if I run command("window.navigator.webdriver")in the Console of the inspection
#result: true # means: Selenium + webdriver
#solution:
options.add_experimental_option('excludeSwitches', ['enable-automation'])
#此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
#browser = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver',
# chrome_options=options)
#run command("window.navigator.webdriver")in the Console of the inspection
#result: undefine # means: regular browser
#browser.get(url)
#print(browser.page_source)
class GetIp():
def __init__(self,domain,baseUrl):
self.domain=domain
self.url=self.domain+str(baseUrl)
self.browser = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver',
chrome_options=options
)
def __del__(self):
self.browser.close()
def get_webpagecontent(self):
print(self.url)
self.browser.get(self.url)
pageSource = self.browser.page_source
return pageSource
def parse_webData(self, pageSource):
#import pandas as pd #0: first row in dataframe
df1 = pd.read_html(pageSource, header=0)[0]
#Converting the chinese columnName to english name
df1.columns = ['Country', 'IP Address', 'Port', 'Server Address', 'Anonymous',
'Type', 'Speed', 'Response Time', 'Available', 'Update']
#from lxml import etree
selector = etree.HTML(pageSource)
countryDict = {'cn': 'China'}
anonymousDict = {'高匿': 'Highly'}
for r in range(df1.shape[0]):
# for c in range(df1.shape[1]):
if pd.isnull(df1.loc[r, 'Country']):
# xpath will cost time, so we need to run several time
try:
cn = \
selector.xpath('//table[@id="ip_list"]/tbody/tr[{0}]/td[@class="country"]/img/@alt'.format(r + 2))[
0]
# print(cn) #Cn
except:
print("run again")
df1.loc[r, 'Country'] = countryDict[cn.lower()]
if df1.loc[r, 'Anonymous'] in anonymousDict.keys():
df1.loc[r, 'Anonymous'] = anonymousDict[df1.loc[r, 'Anonymous']]
try:
speed = \
selector.xpath('//table[@id="ip_list"]/tbody/tr[{0}]/td[@class="country"]/div/@title'.format(r + 2))[0]
df1.loc[r, "Speed"] = speed
except:
print("speed")
try:
res = \
selector.xpath('//table[@id="ip_list"]/tbody/tr[{0}]/td[@class="country"]/div/@title'.format(r + 2))[1]
df1.loc[r, "Response Time"] = res
except:
print("response")
#df1.head()
return df1
def execute(self):
pageSource = self.get_webpagecontent()
ipDataFrame = self.parse_webData(pageSource)
#print(ipDataFrame.head())
hasNextPage = True
#counter=0
while hasNextPage:
hasNextPage=False
selector = etree.HTML(pageSource)
try:
nextPageUrl = selector.xpath('//div[@id="body"]/div[@class="pagination"]/a[@class="next_page"]/@href')[0]
if nextPageUrl:
hasNextPage = True
except:
break
self.url=self.domain+nextPageUrl
pageSource = self.get_webpagecontent()
currentIpDataFrame = self.parse_webData(pageSource)
#print(currentIpDataFrame.head())
ipDataFrame=pd.concat([ipDataFrame,currentIpDataFrame], ignore_index=True)
#counter=counter+1
return ipDataFrame
if __name__=="__main__":
#print(domain + url)
ipCrawler = GetIp(domain,url)
ipDF=ipCrawler.execute()
print(ipDF)
