<script>
var str="CCCaaabbbBBcc1111221ddDDeeEEee333eeeeEEEfffFFF44774";
console.log('str:',str);
var reg=/([a-z])\1{0,}(\d{2})\2{0,}/gi;
str.replace(reg,function($0,$1,$2){
console.log("$0:",$0);
console.log("$1:",$1);
console.log("$2:",$2);
})
</script>
结果如下:
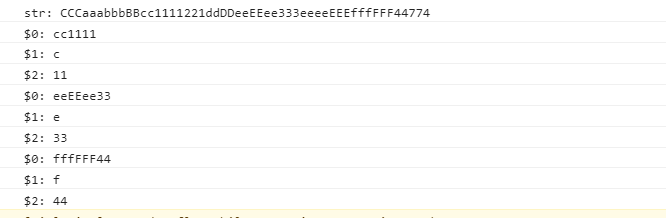
其中$0代表的是整个正则匹配的结果:
/([a-z])\1{0,}(\d{2})\2{0,}/gi;
这个正则的意思是:([a-z])\1{0,}这部分意思是代表匹配多个重复出现的部分大小写字母;
其中的([a-z])\1的意思是捕获这个重复的字母,所以第一个匹配的$1是c;{0,}表示这个字幕可以重复出现的次数,两次cc,
(\d{2})\2{0,}这部分意思是匹配重复出现两次的数字例如11 11,(\d{2})\2的意思是重复出现两次的数字,所以$2是11;{0,}表示后面11必须成组出现并且有一组或者多组,例如11 11,所以1111匹配成功;
综上所述:
第一次的$0为cc1111