前言:
系统管理员很重要的任务之一就是管理好自己的磁盘文件系统,每个分区槽不能太大也不能太小。在这篇文章中,我们重点在于如何制作文件系统,包括分区、格式化与挂载。
1.文件系统特性
我们都知道磁盘分区完毕之后需要进行格式化(format),之后操作系统才能使用这个文件系统。为什么需要进行格式化呢,这是因为每种操作系统所设定的文件属性/权限并不相同,为了存放这些文件所需的数据,就需要将分区槽进行格式化,以成为操作系统能够利用的文件系统格式(filesystem)。
每种操作系统的文件系统并不相同,比如windows 98以前的微软操作系统对应的文件系统是FAT,Windows 2000 以后的版本是所谓的NTFS的文件系统,而Linux系统的正统文件系统则为Ext2(linux second extended file system)。在默认情况下,Windows系统是不会认Linux系统的Ext2fs的。
传统的磁盘是一个分区槽只能够被格式化成为一个文件系统,因此我们说一个filesystem就是一个partition。但是由于新技术的使用,不再是一对一的关系,现在我们一般称呼一个可被挂载的数据为一个文件系统而不是一个分区槽哦!
文件系统通常会将权限与属性放置到inode中,实际数据则放置到data block中,另外还有一个超级区块(superblock)会记录整个文件系统的整体信息,包括inode与block的总量/使用量/剩余量等。
每个inode与block都有编号,这三个数据的意义是:
- superbloock :记录filesystem整体信息,包括inode/block的总量,使用量,剩余量以及fs的 格式及相关信息等。
- inode:记录文件的属性,一个文件占用inode,同时记录此文件数据所在的block号码;
- block:实际记录文件的内容,若文件太大时,会占用多个block。
由于每个inode/block都有编号,而每个文件会占用一个inode,inode里有文件数据放置的block号码。因此,如果我们能够找到文件的inode的话,就自然会知道这个文件所放置数据的block号码,也就能够读出该文件的实际数据啦。
假设某一个文件的属性与权限数据是放到inode 4号,而这个inode记录的文件数据实际放置点为2,7,13,15这四个block号码,此时我们的操作系统就能根据此来排列磁盘的阅读顺序,这种数据存储的方法我们叫做索引式文件系统(indexed allocation)。
还有一种惯用的文件系统,随身碟(闪存),随身碟使用的文件系统一般为FAT格式,这种格式的文件系统并没有inode存在,所以FAT没有办法将这个文件的所有block在一开始就读取出来,每个block号码都记录在前一个block中,需要一个一个将block读出后,才会知道下一个block在何处。如果数据写入的block太过分散,又是还需要多转几圈来完整的读取到这个文件的内容。常常会听到一个概念碎片整理,需要碎片整理的原因就是因为文件写入的block太过于离散了,此时文件的读取效能变得很差所致。这时可以透过碎片整理将同一个文件所属的blocks汇整在一起,这样数据的读取会比较容易。FAT系统经常需要碎片整理,而Ext2 因为是indexed allocation并不需要碎片整理的。
2. Linux的EXT2 文件系统(inode)
文件系统一开始就将inode与block规划好了,除非重新格式话(或者利用resize2fs等指令重新变更文件系统的大小),否则inode与block固定后就不再变动。不过Ext2文件系统在格式化的时候基本上区分为多个区块群组(block group)的,每个block group都有独立的inode/block/superblock 系统。分区后的文件系统有点类似如下:
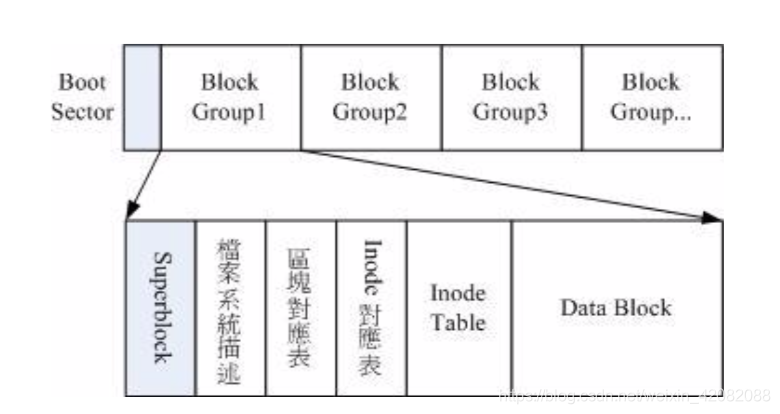 在整体规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装到开机管理程序,这样一来我们就能够将不同的开机管理程序安装到个别的fs最前端,而不用覆盖整颗磁盘唯一的MBR。关于每一个block group的六个主要内容说明如下:
在整体规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装到开机管理程序,这样一来我们就能够将不同的开机管理程序安装到个别的fs最前端,而不用覆盖整颗磁盘唯一的MBR。关于每一个block group的六个主要内容说明如下:
2.1data block 资料区块
data block使用来存放文件内容数据的地方,在Ext2文件系统中所支持的block大小有1k,2k及4k三种而已。
 blcok基本限制:1.block的大小与数量在格式化完就不能够再改变了(除非重新格式化);
blcok基本限制:1.block的大小与数量在格式化完就不能够再改变了(除非重新格式化);
2.每个block内最多只能放置一个文件的数据;
3.承上,如果文件大于block的大小,则一个文件会占用多个block数量;
4.承上,如果文件小于block,则该block的剩余容量就不能够再被使用了 (磁盘空间会被浪费)。
2.2 inode table(inode表格)
inode记录的文件数据至少有:该文件的存取模式(r,w,x);该文件的拥有者与群组(owner/group);该文件的容量;该文件建立或状态改变时间(ctime);最近一次读取时间(atime);最近修改的时间(mtime);定义文件特性的旗标(flag),如SetUID;该文件的真正内容指向(pointer)。
另外inode 的特点还有:1.每个indoe 的大小固定为128bytes(新的ex14与xfs可设定到256bytes);
2.每个文件都仅会占用一个inode而已;
3.承上,因此文件系统能够建立的文件数量和inode数量有关;
4.系统读取文件需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能开始实际读取block的内容。
在fs中,将inode记录block号码的区域定义为12个直接,一个间接,一个双间接与一个三间接记录区。所谓的间接就是再拿一个block来当记录block号码的记录区,如果文件太大时,就会使用间接的block来记录编号。如果文件持续长大,就会利用双间接,即第一个block仅指出下一个记录编号的block在哪里,实际记录的在第二个block当中。那么这样的inode能够指定多少个block呢,我们以较小的1k block来说明好了。
- 12个直接指向: 12*1k=12k
- 间接: 256*1k=256k
- 双间接:2562561k
- 三间接:256256256*1k
- 总额,全部相加得 16GB
因此,我们可以知道当文件系统将block格式化为1k时,能够容纳的最大文件为16GB。但这个方法不适用于2K及4K 的block大小计算中吗,因为大于2K的block将会收到Ext2文件系统本身的限制。
2.3 Superblock(超级区块)
superblock 是记录整个filesystem相关信息的地方,一般来说superblock的大小为1024bytes。
2.4 Filesystem Description(文件系统描述说明)
这个区段可以描述每个block group的 开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, datablock)分别介于哪一个block号码之间。
2.5 block bitmap(区块对照表)
如果你想要新增文件时总会用到block吧,那么肯定要使用一个空的block来记录新文件的数据啰。这时就要透过block bitmap来判断哪个block是空的,快速找到可以使用的空间来处置文件。删除文件时,也是同样的,原本占用的block会被释放出来,在block bitmap中相对应到该block号码的标志就会被修改成为【未使用中】。
2.6 inode bitmap(inode 对照表)
这个和block bitmap的功能类似,只不过记录的是使用与未使用的inode号码啰。
一个指令:dumpe2fs 查询Ext家族 superblock 信息的指令
3.与目录树的关系
3.1 目录
当我们在Linux下的文件系统建立一个目录时,文件系统会分配一个inode与至少一块block给该目录。目录所占用的block内容记录如下信息:
 如果想实际观察root 家目录内文件所占用的inode号码时,可以用ls -i这个指令来处理
如果想实际观察root 家目录内文件所占用的inode号码时,可以用ls -i这个指令来处理
3.2 文件
当我们在Linux下的ext2建立一个一般文件时,ext2会分配一个inode与相对该文件大小的block数量给该文件。假如我的一个block为4k bytes,而我要建立一个100KB的文件,那么将会分配一个inode与25个block来存储该文件。由于inode 仅有12个直接指向,因此还要多一个block 来作为区块号码的记录。
3.3 目录树读取

举例例如系统上面的/etc/passwd有关的目录文件读取流程为:
1./ 的inode:通过挂载点找到inode号码为128的根目录inode,且inode规范的权限让我们可以读取该block的内容(有r,x)
2./的block:经过上个步骤取得block的号码,并找到该内容有etc/目录的inode号码(33595521);
3.etc/ 的inode:读取33595521号inode得知dmtsai具有r与x的权限,因此可以读取etc/的block内容;
4.etc/的block
5.passwd的inode;
6.passwd的block:最终将该block的数据读出来。
3.4 filesystem大小与磁盘读取功能
分区的规划并不是越大越好,当一个文件分别记录在filesystem的最前面与最后面的block的号码中,会造成磁盘的机械手臂移动幅度过大,从而导致数据读取功能的低落。
3.5 EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
假设我们想新增一个文件,此时系统的行为是:
 3.6 日志式文件系统(journaling filesystem)
3.6 日志式文件系统(journaling filesystem)
为了避免文件系统不一致的情况发生,我们的前辈想到一个方式,在fs中规划出一个区块,专门记录写入或修订文件时的步骤以简化一致性检查的步骤。也就是说:
1.预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息;
2.实际写入:开始写入文件的权限与数据,开始更新metadata的数据;
3.结束:完成数据与metadata的更新后,在日志记录区块当中完成文件的记录。
3.7 linux 文件系统的运作
Linux系统中有一个异步处理的方式(asynchronously),当系统加载一个文件到内存后,如果该文件没有被更动过,则在该内存区段的文件数据会被设定为干净的(clean),但如果内存中的文件数据被更改过了(例如你用nano去编辑过这个文件),此时该内存中的数据会被设定为脏的(dirty)。此时所有动作都还在内存中执行,并没有写到磁盘中。系统会不定时将内存中设定为dirty的数据写回磁盘,也可以利用sync指令来手动强迫写入磁盘。
3.8 挂载点的意义(mount point)
每个filesystem 都有独立的inode/block/superblock等信息,这个文件系统要能够连接到目录树才能够被我们使用。将文件系统与目录树结合的动作我们成为挂载。
3.9 其他Linux支持的文件系统与vfs
Linux标准fs是ext2,还有增加了日志功能的ext3/ext4。近几年还推出了SUI的XFS文件系统等,常见的fs有:
传统文件系统:ext2/minix/MS-DOS/FAT/iso9660(光盘)等;
日志式文件系统:ext3/ext4/ReiserFS/winows’NTFS/IBM’s JFS/SGI’s XFS/ZFS
网络文件系统:NFS/SMBFS
VFS(virtual filesystem switch),整个Linux认识的filesystem都是通过VFS来进行管理。
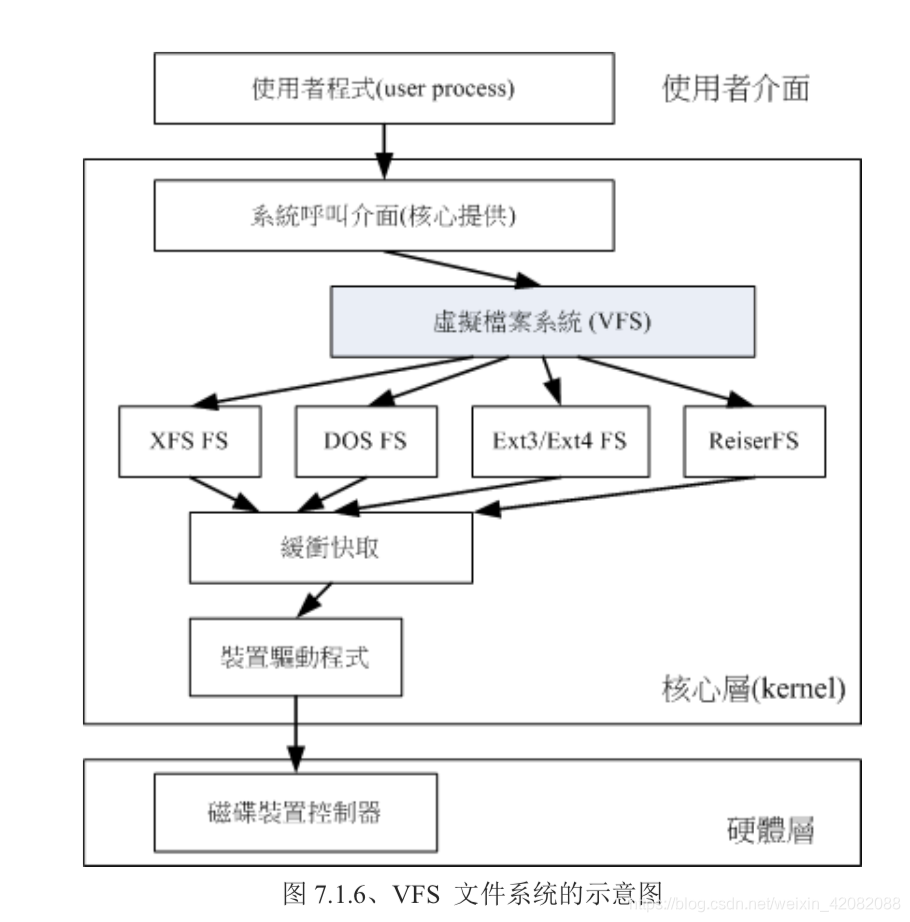 3.10 XFS文件系统简介
3.10 XFS文件系统简介
CentOS 7 开始,预设的文件系统已经由EXT4变成了XFS文件系统了。相较来说,EXT家族当前伤脑筋的地方是:支持度最广,但格式化超慢。而xfs比较适合高容量磁盘与巨型文件效能。
xfs主要分为三部分,一个资料区(data section),一个文件系统活动登陆区(log section),一个实时运作区(realtime section)。
**资料区(data section)**和ext一样,包括inode/block/superblock等数据,不同的是xfs的block与inode有多种不同容量可供设定,block容量由512bytes-64k调配,inode容量可以由256kbytes到2M这么大。
**文件系统活动登陆区(log section)**在这个区域主要被用来记录文件系统的变化,有点像日志区。
**实时运作区(realtime section)**当有文件被建立时,xfs会在这个区段里面找到一个到数个的extent区块,将文件放置到这个区块内,在写入到data section的inode 与 block中去。extent的大小在格式化的时候先指定,4k到1G。
xfs文件系统描述数据观察下达指令【xfs_info 挂载点|装置文件名】
4.文件系统的简单操作
4.1 磁盘与目录的容量
df:列出文件系统的整体磁盘使用量;
du:评估文件系统的磁盘使用量(常用在推估目录所占容量)



需要注意的是:一些比较特殊的文件系统几乎都是在内存中的,不会占据磁盘空间的。另外/dev/shm 这个目录,是利用内存虚拟出来的磁盘空间,通常是总物理内存的一半。
 与df指令不同的是,du会直接到文件系统内去搜寻所有的文件数据。
与df指令不同的是,du会直接到文件系统内去搜寻所有的文件数据。
4.2 实体链接与符号链接
在Linux底下的链接档有两种,一种是类似windows的快捷方式功能的文件,可以让你快速的连接到目标文件,另一种则是透过inode连接来产生新的档名(注意不是新文件),这种称为实体链接(hard link)。
- 实体链接,硬式连结或实际连结(hard link)
简单来说,hard link 只是在某个目录下新增一笔档名链接到某inode号码
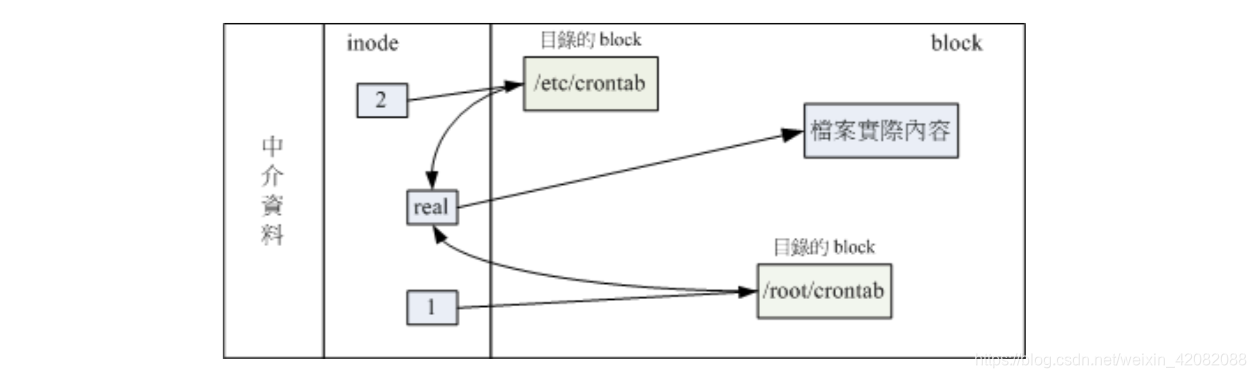 由上图我们可以知道,透过1/2目录之inode指定的block找到两个不同的档名,而不管使用哪个档名都可以找到real那个inode去读取到的真正的数据。这样的最大的好处就是安全,如果你将任何一个档名删除,其实inode与block都是存在的,可以通过另一个档名来读取到正确的数据。不过使用hard link设定链接文件时,磁盘的空间与inode的数目都不会改变哦,只是在某个目录下的block多写入一个关联数据而已,即不会增加inode也不会耗用block的数量。
由上图我们可以知道,透过1/2目录之inode指定的block找到两个不同的档名,而不管使用哪个档名都可以找到real那个inode去读取到的真正的数据。这样的最大的好处就是安全,如果你将任何一个档名删除,其实inode与block都是存在的,可以通过另一个档名来读取到正确的数据。不过使用hard link设定链接文件时,磁盘的空间与inode的数目都不会改变哦,只是在某个目录下的block多写入一个关联数据而已,即不会增加inode也不会耗用block的数量。
hard link的限制:1.不能跨filesystem;2.不能link目录(会造成巨大的复杂度,目前还不支持)。
-符号链接,即快捷方式(symbolic link)
symbolic link就是建立一个独立的文件,而这个文件会让数据的读取指向他link的那个文件档名。不过当来源档被删除后,symbolic link的文件会开不了,会一直说无法开启某文件,实际上就是找不到原始的档名。
 例如上图,我们先建立一个symbolic link连接到/ect/crontab去看看,我们发现两个文件指向不同的inode号码,就是两个独立的文件存在。而且,链接档的重要内容就是他会写上目标文件的文件名。上图中链接档的大小为12bytes,这时因为箭头(–>)右边的档名【/etc/crontab】总共有12个英文,每个英文占用1个bytes,所以文件大小就是12bytes了!
例如上图,我们先建立一个symbolic link连接到/ect/crontab去看看,我们发现两个文件指向不同的inode号码,就是两个独立的文件存在。而且,链接档的重要内容就是他会写上目标文件的文件名。上图中链接档的大小为12bytes,这时因为箭头(–>)右边的档名【/etc/crontab】总共有12个英文,每个英文占用1个bytes,所以文件大小就是12bytes了!
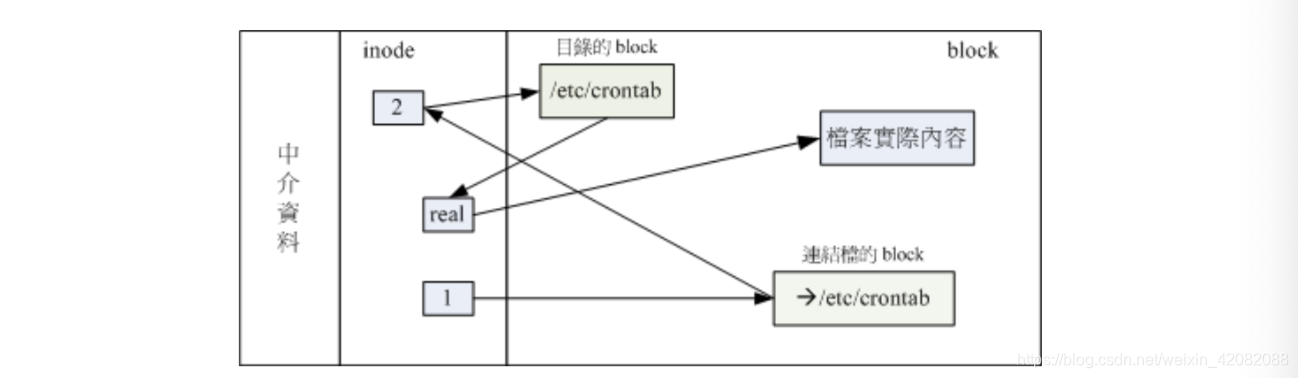 symbolic link可以等于Windows的快捷方式,而且symbolic link建立的文件为一个独立的新文件,所以会占用到inode与block哦。
symbolic link可以等于Windows的快捷方式,而且symbolic link建立的文件为一个独立的新文件,所以会占用到inode与block哦。
制作链接档的命令 【In [-sf] soure file target file】
选项与参数: -s:如果不加任何参数就进行连结,那就是hard link。-s,就是symbolic link。
-f:如果目标文件存在时,就主动将目标文件直接移除后再建立。
关于目录link的数量
通常来说,一个空目录里面至少会存在 . 与 … 这两个目录,例如当我们建立一个新目录名称为/tmp/testing,基本上会有三个东西,那就是:/tmp/testing /tmp/testing/. /tmp/testing/…
5.磁盘的分区、格式化、检验与挂载
如果我们想在系统中增加一颗磁盘时,应该怎么做呢?1.对磁盘进行分区,以建立可用的partition;2.对该partition进行格式化format,以建立系统可用的filesystem ;3.若想要仔细一点,可对刚刚建好的filesystem进行检验;4.在Linux系统上,需要建立挂载点(亦即是目录),并将他挂载上来。
**5.1 观察磁盘分区状态 **
**lsblk 列出系统上所有的磁盘列表 —list block device **
lsblk意为列出所有储存装置,常用的输出的默认信息有:
- NAME:装置文件的名字,会省略/dev等目录;
- MAJ:MIN:其实核心认识的装置都是透过这两个代码来熟悉的。分别是主要:次要装置代码;
- RM:是否为可卸载装置(removable device),如光盘、USB等;
- RO:是否为只读装置的意思;
- TYPE:是磁盘(disk)、分区槽(partition)还是只读存储器(rom)等输出;
- MOUTPOINT:就是前面提到的挂载点。
blkid 列出装置的UUID等参数
UUID是全局单一标识符(universally unique identifier), Linux系统会将系统内所有装置都给予一个独一无二的标识符,这个标识符就可以拿来作为挂载或者是使用这个装置/文件系统之用了。当然用【lsblk -f】也可以起到blkid指令相同的作用。
parted 列出磁盘的分区表类型与分区信息
指令:【parted device_name print】
例如:列出/dev/vda磁盘的相关数据, 指令为【parted /dev/vda print】
磁盘分区:gdisk/fdisk
要注意的是:MBR分区表请使用fdisk分区,GPT分区表请使用gdisk分区。
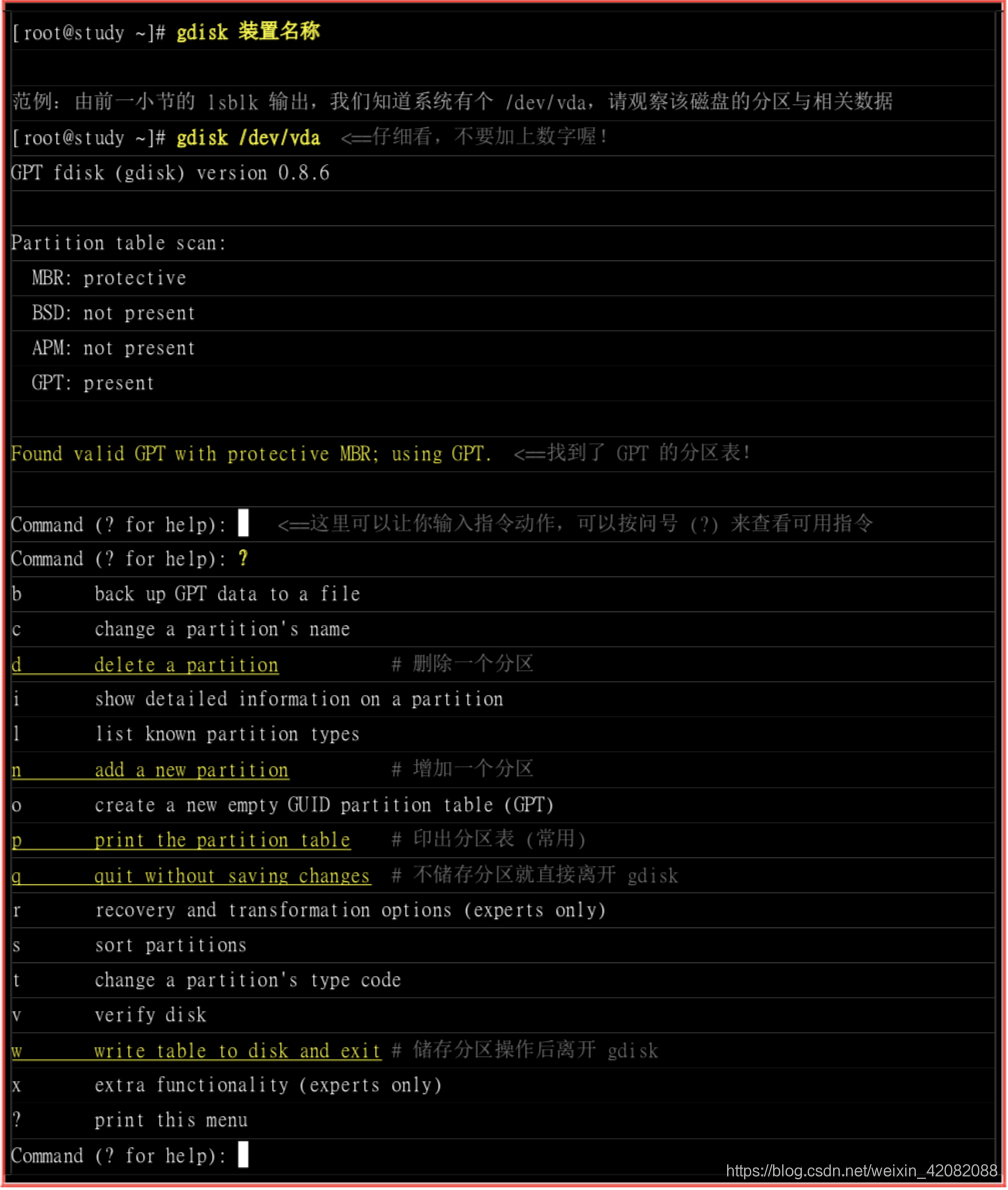 可以看出gdisk指令使用前,我们应该用lsblk或者blkid指令先找到磁盘,在用parted /dev/xxx print 来找出内部的分区表类型,之后才用gdisk或fdisk来操作系统。在上图中,可以发现gdisk会扫描MBR与GPT分区表,不过这个软件还是单纯使用在GPT分区表比较好啦。在这些选项参数中,比较不一样的是【q】与【w】,只要离开gdisk时按下【q】,那么所有动作都不会生效,相反,只要按下【w】即为动作生效的意思。
可以看出gdisk指令使用前,我们应该用lsblk或者blkid指令先找到磁盘,在用parted /dev/xxx print 来找出内部的分区表类型,之后才用gdisk或fdisk来操作系统。在上图中,可以发现gdisk会扫描MBR与GPT分区表,不过这个软件还是单纯使用在GPT分区表比较好啦。在这些选项参数中,比较不一样的是【q】与【w】,只要离开gdisk时按下【q】,那么所有动作都不会生效,相反,只要按下【w】即为动作生效的意思。
用gdisk新增分区槽
【问题总结】1.一个可以挂载的数据通常称为文件系统,而不是分区槽。
