学习内容:
正则表达式的分组指令
1.group,groups,start,end指令的使用
1)group指令
import re
text="tom is 8 years old nitty is 64 years old"
s=re.compile(r"(\d+).*?(\d+)")
m=s.search(text)
m.group(0)
Out[57]: '8 years old nitty is 64'
m.group(1)
Out[58]: '8'
m.group(2)
Out[59]: '64'承接上面的指令,我尝试了end和start指令
m.start(1)
Out[62]: 7
m.start(2)
Out[63]: 28
m.end(1)
Out[64]: 8
m.end(2)
Out[65]: 30groups指令
import re
s=re.compile(r"(\d+).*?(\d+)")
text="tom is 8 years old nitty is 64 years old"
m=s.search(text)
m.groups(text)
Out[70]: ('8', '64')
我们发现使用groups直接返回包含数字的元组,不同于group返回一整串字符串
3)限制备选选项
import re
re.search(r"centre|er","center")
Out[10]: <re.Match object; span=(4, 6), match='er'>
re.search(r"centre|er","center")
Out[11]: <re.Match object; span=(4, 6), match='er'>
re.search(r"cent(re|er)","center")
Out[12]: <re.Match object; span=(0, 6), match='center'>
re.search(r"cent(re|er)","center")
Out[13]: <re.Match object; span=(0, 6), match='center'>4)特定声明加引用。
声明?p<属性名>
引用m.group(“属性名”)
import re
text="tom:66"
s=re.compile(r'(?p<name>\w+):(?p<score>\d+)')
m.group()
m.group("name")这样就会出现name对应内容(tom)
5)内容切割
split操作
import re
text="good-morning"
p=re.compile(r"(-)")
p.split(text)
Out[9]: ['good', '-', 'morning']
p=re.compile(r"-")
p.split(text)
Out[11]: ['good', 'morning']这里要注意括号的使用,加上括号,包括分隔符在内都会分成一组
import re
text="good-morning-everyone"
p=re.compile(r"-")
p.split(text,1)
Out[19]: ['good', 'morning-everyone']这里的split后面加上了数字1,表示切割一段,切割剩下的单独为一个整体
6)内容的替换
import re
text="good-morning-everyone"
re.sub(r"-","+",text)
Out[21]: 'good+morning+everyone'sub(即将替换的内容,替换的内容,操作的文件)
import re
text="good-*moring*-everyone"
re.sub(r"\*(.*?)\*",'<&><^>',text)
Out[24]: 'good-<&><^>-everyone'
我们再替换之后,发现内容被删掉了,这时候就用到了文件内引用\g<关键字>(参考别人代码)

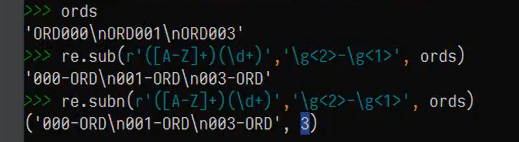
7)编译标记
re.I忽略大小写
text="myy MYY mYy myY Myy MYy MyY"
re.findall(r"myy",text,re.I)
Out[29]: ['myy', 'MYY', 'mYy', 'myY', 'Myy', 'MYy', 'MyY']re.M匹配多行
re.findall(r"<ss>","\n<ss>")
Out[30]: ['<ss>']
re.findall(r"^<ss>","\n<ss>")
Out[31]: []
re.findall(r"^<ss>","\n<ss>",re.M)
Out[32]: ['<ss>']re.S指定“内容”匹配所有字符包括\n
re.findall(r"(.)","1\n1er")
Out[33]: ['1', '1', 'e', 'r']
re.findall(r"(.)","1\n1er",re.S)
Out[34]: ['1', '\n', '1', 'e', 'r']我们发现,加上之后,就会找到\n
8)模块及操作
re.purge()清理正则缓存
re.escape()逃逸字符
text="^morning^"
re.findall(r"^",text)
Out[36]: ['']
re.findall(re.escape("^"),text)
Out[37]: ['^', '^']
re.purge()清理缓存在后台进行,我们看不到
