以下内容翻译自:MPI Broadcast and Collective Communication
到目前为止,在MPI教程中,我们已经审视了两个进程之间的点对点通信。本课是集合通信部分的开始。集合通信是一种所有通信进程都参与其中的通信方式。在本课中,我们将讨论集合通信的含义,并讨论标准集体例程——广播。
注——本网站的所有代码均位于GitHub上。本教程的代码位于tutorials/mpi-broadcast-and-collective-communication/code下。
集合通信和同步点
集合通信需要记住的一点是,它在进程间设置同步点。这意味着所有进程在它们全部开始执行之前必须到达其代码中的某个点。
在详细讨论合通信例程之前,让我们更详细地研究同步。事实证明,MPI有一个专门用于同步进程的特殊函数:
MPI_Barrier(MPI_Comm communicator)该函数的名称非常具有描述力——该函数产生一个障碍,并且通信器中的任何进程都不能通过该障碍,直到所有这些进程调用该函数为止。这是一个例子。想象一下水平轴表示程序的执行,圆圈表示不同的过程:
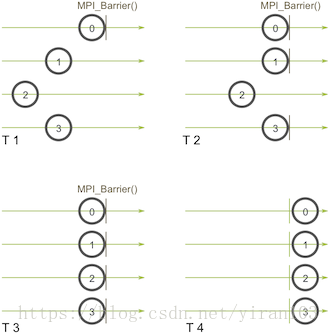
进程0首先在第一次快照(T 1)时调用MPI_Barrier。当进程0在屏障上挂起时,进程1和进程3最终到达(T 2)。当进程2最后进入屏障(T 3)时,所有进程再次开始执行(T 4)。
MPI_Barrier可以用于很多事情。主要用途之一是同步一个程序,以便并行代码部分可以准确计时。
想知道MPI_Barrier是如何实现的?当然你可以 :-) 你还记得发送和接收教程中的环形程序吗?为了让你回忆起来,我们编写了一个程序,以环形方式在所有进程中传递令牌。 这种类型的程序是实现屏障的最简单方法之一,因为在所有进程一起工作之前,令牌无法完成传递。这种类型的程序是实现一个屏障最简单的方法之一,因为在所有进程协同工作之前,令牌不能完成传递。
关于同步的最后一点注意事项——请始终记住您所做的每个集合调用都进行了同步。换句话说,如果您无法成功完成MPI_Barrier,那么您也无法成功完成任何集合调用。如果您尝试调用MPI_Barrier或其他集合例程而未确保通信器中的所有进程也会调用它,则您的程序将空闲。这可能会让初学者感到困惑,所以要小心!
使用MPI_Bcast进行广播
广播是标准的集合通信技术之一。在广播过程中,一个进程向通信器中的所有进程发送相同的数据。广播的主要用途之一是将用户输入发送到并行程序,或向所有进程发送配置参数。
广播的通信模式如下所示:
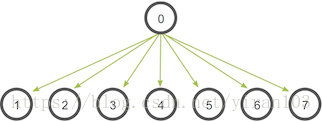
在这个例子中,进程0是根进程,它有数据的初始副本。所有其他进程都会收到数据副本。
在MPI中,可以使用MPI_Bcast完成广播。函数原型如下所示:
MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)尽管根进程和接收者进程执行不同的工作,但它们都调用相同的MPI_Bcast函数。当根进程(在我们的例子中,它是进程0)调用MPI_Bcast时,data变量将被发送到所有其他进程。当所有接收者进程调用MPI_Bcast时,data变量将被来自根进程的数据填充。
使用MPI_Send和MPI_Recv进行广播
起初,似乎MPI_Bcast只是MPI_Send和MPI_Recv的简单封装。事实上,我们现在可以制作这个功能封装。我们的函数my_bcast位于bcast.c中。它采用与MPI_Bcast相同的参数,如下所示:
void my_bcast(void* data, int count, MPI_Datatype datatype, int root,
MPI_Comm communicator) {
int world_rank;
MPI_Comm_rank(communicator, &world_rank);
int world_size;
MPI_Comm_size(communicator, &world_size);
if (world_rank == root) {
// If we are the root process, send our data to everyone
int i;
for (i = 0; i < world_size; i++) {
if (i != world_rank) {
MPI_Send(data, count, datatype, i, 0, communicator);
}
}
} else {
// If we are a receiver process, receive the data from the root
MPI_Recv(data, count, datatype, root, 0, communicator,
MPI_STATUS_IGNORE);
}
}根进程将数据发送给其他进程,而其他进程则从根进程接收数据。很简单,对吧?如果您从repo的tutorials目录运行my_bcast程序,则输出应该与此类似。
>>> cd tutorials
>>> ./run.py my_bcast
mpirun -n 4 ./my_bcast
Process 0 broadcasting data 100
Process 2 received data 100 from root process
Process 3 received data 100 from root process
Process 1 received data 100 from root process相信与否,我们的功能效率实际上非常低下!想象一下,每个进程只有一个输出/输入网络连接。我们的函数仅使用一个来自进程0的网络连接来发送所有数据。更智能的实现是基于树的通信算法,可以一次使用更多可用的网络链接。例如:

在上图中,进程0开始时将数据发送给进程1。与我们前面的例子类似,在第二阶段进程0也向进程2发送数据。这个例子的不同之处在于,进程1现在帮助完成根进程将数据转发到进程3。在第二阶段,一次使用两个网络连接。在树形通信的每个后续阶段,网络利用率都会翻倍,直到所有进程都收到数据。
你认为你可以编码吗?编写这段代码有点超出了本课的目的。如果你感觉很勇敢,那么《Parallel Programming with MPI》就是一本很好的书,它带有上述问题的完整代码例子。
MPI_Bcast与MPI_Send和MPI_Recv的比较
MPI_Bcast实现利用类似的树广播算法来实现良好的网络利用率。我们的广播功能相比MPI_Bcast如何?我们可以运行compare_bcast,这是一个课程代码(compare_bcast.c)中包含的示例程序。在查看代码之前,我们先来看一下MPI的一个定时功能——MPI_Wtime。MPI_Wtime不接受任何参数,它只是返回自过去某一时间以来的一个浮点数。与C的time函数类似,您可以在整个程序中调用多个MPI_Wtime函数,并减去它们之间的差以获取代码段的时间。
我们来看看比较my_bcast与MPI_Bcast的代码。
for (i = 0; i < num_trials; i++) {
// Time my_bcast
// Synchronize before starting timing
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time -= MPI_Wtime();
my_bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD);
// Synchronize again before obtaining final time
MPI_Barrier(MPI_COMM_WORLD);
total_my_bcast_time += MPI_Wtime();
// Time MPI_Bcast
MPI_Barrier(MPI_COMM_WORLD);
total_mpi_bcast_time -= MPI_Wtime();
MPI_Bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
total_mpi_bcast_time += MPI_Wtime();
}在这个代码中,num_trials是一个变量,说明应该执行多少个时间实验。我们通过两个不同的变量跟踪两个函数的累计时间。在程序结束时打印平均时间。要查看完整的代码,请查看课程代码中的compare_bcast.c。
如果您从repo的tutorials目录运行compare_bcast程序,则输出应与此类似。
>>> cd tutorials
>>> ./run.py compare_bcast
/home/kendall/bin/mpirun -n 16 -machinefile hosts ./compare_bcast 100000 10
Data size = 400000, Trials = 10
Avg my_bcast time = 0.510873
Avg MPI_Bcast time = 0.126835运行脚本使用16个处理器执行代码,每个广播执行100,000个整数,并进行10次测量时间。正如你所看到的,我使用通过以太网连接的16个处理器的实验显示,我们的简单实现和MPI的实现之间存在显着的时间差异。这里是不同规模的时间结果。
| Processors | my_bcast | MPI_Bcast |
|---|---|---|
| 2 | 0.0344 | 0.0344 |
| 4 | 0.1025 | 0.0817 |
| 8 | 0.2385 | 0.1084 |
| 16 | 0.5109 | 0.1296 |
正如你所看到的,在两个处理器上两个实现没有区别。这是因为在使用两个处理器时,MPI_Bcast的树实现不提供任何额外的网络利用率。但是,即使只有16个处理器,差异也可以清楚地观察到。
尝试自己运行代码并在更大规模上进行实验!
结论/接下来
有点理解集合程序了?在接下来的MPI教程中,我会介绍其他重要的集合通信程序 ——gathering 和 scattering。
对于所有课程,请转到MPI教程页面。
想贡献?
这个网站完全托管在 GitHub上。本网站不再由原作者(Wes Kendall)积极贡献,但它放在GitHub上,希望其他人可以编写高质量的MPI教程。点击这里获取更多关于如何贡献的信息。