内置字符串函数

gsub函数
替换字符串,使用正则表达式:/目标模式/,替换模式。
awk 'gsub(/4842/,8888) {print $0}' grade.txtindex函数
查询字符串 s 中 t 出现的第一位置。必须用双引号将字符串括起来。例如返回目标字符串Bunny中ny出现的第一位置。
awk 'BEGIN {print index("Bunny","ny")}' grade.txtlength函数
返回所需字符串的长度:
awk '$1=="Jerry" {print length($1)"\n"$1}' grade.txt
//另一种方式,字符串加双引号
awk 'BEGIN {print length("Jerry is a good boy")}'
match函数
match测试目标字符串是否包含查找字符的一部分。可以使用正则表达式,返回值为成功的字符排列数,如果未找到返回0
awk 'BEGIN {print match("ABCD",/s/)}'
awk 'BEGIN {print match("ABCD",/B/)}'
awk '$1=="Hello" {print match($1,/0/)}' hellosplit函数
使用split函数返回字符串数组元素个数,需要指定数组名和分隔符。
awk 'BEGIN {print split("ADC-APC-AP-AD-1",array,"-")}'sub函数
使用sub发现并替换模式的第一次出现的位置,
awk '$1=="Jerry" sub(/Jerry/,"JERRY",$0)' hello.txt
//修改并打印修改后的文本
awk '{$1=="Jerry" sub(/26/,30,$0)} END{ print $0}' find.sh
substr函数
按照起始位置以及长度返回字符串的一部分。如果给定长度远大于字符串长度,awk将从起始位置返回所有字符。
//返回字符串:L.Tan
awk '$1=="L.Tansley" {print substr($1,1,5)}' grade.txtsubstr的另一种形式是返回字符串后缀或指定位置后面字符。这里需要给出指定字符串及其返回字串的起始位置。例如,从文本文件中抽取姓氏,需操作域1,并从第三个字符开始:
awk '{print substr($1,3)}' grade.txt在BEGIN部分定义字符串,在END部分返回从第t个字符开始抽取的子串。
awk 'BEGIN{STR="hello,jerry"} END{print substr(STR,7)}' find.sh
//一个有趣的现象:必须制定一个存在的文件,否则无法截取字符串。下列无法截取打印:
awk 'BEGIN{STR="hello,jerry"} END{print substr(STR,7)}'字符串屏蔽序列

例如:
awk 'BEGIN {print"\nMay\tDay\n\nMay \104\141\171"}'输出函数printf
printf函数基本语法是printf([格式控制符],参数),格式控制字符通常在引号里。
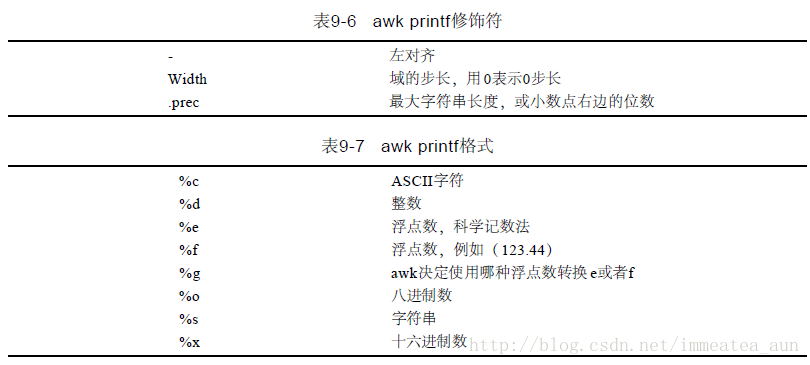
字符转换
echo "65" | awk '{printf "%c\n",$0}'
awk 'BEGIN {printf "%c\n",65}'格式化输出
awk 'BEGIN{print "Name\t\tS.Number"}{printf "%-15s %s\n",$1,$3}' grade.txt向awk中传值
awk '{if($5<AGE) print $0}' AGE=10 grade.txt
//查询文件系统容量,观察是否达到一定水平
df -k | awk '($4~/^[0-9]/){if($4<LEVEL) print $6"\t"$4}' LEVEL=56000
who | awk '{print $1 "is logged on"}'
who | awk '{if($1==user)print $1 " you are connected to "$2}' user=$LOGNAMEawk脚本
可以将awk脚本写入一个文件再执行它。命令不必很长(尽管这是写入一个脚本文件的主要原因),甚至可以接受一行命令。这样可以保存awk命令,以使不必每次使用时都需要重新输入。使用文件的另一个好处是可以增加注释,以便于理解脚本的真正用途和功能。
创建文件total.awk并输入如下内容,保存并设置该文件的可执行权限:

//调用脚本
$> total.awk grade.txt使用awk脚本时,记住设置FS变量是在BEGIN部分。如果不这样做, awk将会发生混淆,不知道域分隔符是什么。
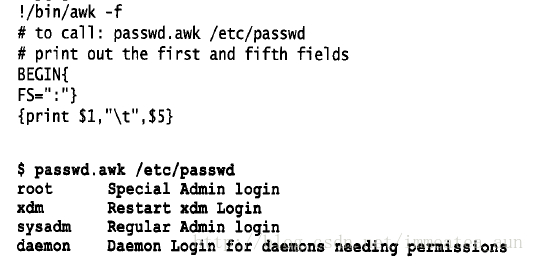
向脚本传值:
awk script_file var=value input_file同样可以使用前面提到的管道命令传值,下述awk脚本从du命令获得输入,并输出块和字节数。
#!/bin/awk -f
# To call: du | du.awk
# prints file/direc's in bytes and blocks
BEGIN{
OFS="\t";
print "name" "\t\t","bytes","blocks\n"
print "=============================="}
{print $2,"\t\t",$1*512,$1}