遍历文件夹(文件夹里的文件夹)
使用os.walk(指定的绝对路径或者相对路径),可以实现把文件夹里的把文件夹里的把文件夹里的…文件都找出来
import os
for dirpath, dirnames,files in os.walk('./'):
print(f'发现文件夹:{dirpath}')
print(files)
其中:
dirpath是文件夹路径
dirnames是dirpath这个文件夹下的子文件夹列表
files是dirpath这个文件夹里的文件列表
注意:这里使用的是相对路径,也就是创建该程序的.py文件是和放在第一层的路径下的
搜索、匹配文件名称
利用字符串内置的方法:.startswith()和.endswith()
print('abc.txt'.startswith('ab'))
print('abc.txt'.endswith('.txt'))
返回的结果都是True
glob模块
import glob
print(glob.glob('*.py'))
输出为这个路径下所有包含.py的文件(这里使用了正则的’*'的用法)
| 模式 | 意义 |
|---|---|
| * | 匹配所有 |
| ? | 匹配任意字符 |
| [seq] | 匹配seq中的任何字符 |
| [!seq] | 匹配任何不在seq中的字符 |
把藏在文件夹很多层下面的文件都找出来
print(glob.glob('**/*.txt', recursive = True)
用**表示任意层文件或文件夹,recursive=True会不断进入文件夹内。查找该路径下面的所有.txt文件,包括深层的文件
fnmatch模块
import fnmatch
print(fnmatch.fnmatch('file1.txt','f*1.txt'))
print(fnmatch.fnmatch('file1.txt','f*[0-9].txt'))
用来匹配文件名称,如果文件夹中存在前面的文件就返回True
查询文件的信息
os.scandir()返回的文件都可以查询信息
for file in os.scandir():
print(file.stat())
输出结果样式为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-stgDIAYM-1579346098488)(399D0830E69E48CF9ABB908D32A6060D)]](https://img-blog.csdnimg.cn/20200118191743799.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2x5c184Mjg=,size_16,color_FFFFFF,t_70)
部分参数的说明见下表:
| 名称 | 说明 |
|---|---|
| st_size | 文件的体积大小(单位:bytes),除于1024就是KB |
| st_atime | 文件的最近访问时间 |
| st_mtime | 文件的最近修改时间 |
| st_ctime | windows下创建的时间 |
| st_birthtime | 在Mac、linux下使用,表示创建时间 |
unix时间戳:前面类似1579276201这样的一个数字,可以转换成为正常的日期时间
import time
print(time.ctime(1579276201))
输出结果为:Fri Jan 17 23:50:01 2020
datetime模块
import datetime
that_time = datetime.datetime.fromtimestamp(1579276201)
print(that_time)
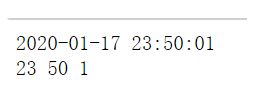
print(that_time.hour,that_time.minute,that_time.second)
输出结果为:
单独查询指定文件
os.stat(指定文件路径)
print(os.stat('file1.txt'))
输出为:

综合应用
编写一个python程序,示例文件夹内容如下,要求:
(1)搜索整个文件夹,包括文件夹中所有的文件夹
(2)筛选体积大于100MB的压缩包.zip文件
(3)筛选这些文件中日期早于2020年之前的文件
(4)输出这些文件的路径
文件夹选取电脑中某一个文件,编写原代码如下:
import os
import glob
import datetime
os.chdir('D:\\Program Files (x86)\\数据分析师')
paths = glob.glob('**/*.zip',recursive = True)
#进行试错
'''path0 = paths[0]
file_size = os.stat(paths[0]).st_size/1024/1024
file_build_year = datetime.datetime.fromtimestamp(os.stat(path0).st_ctime).year
print('第一个压缩包的路径名称是:{},内存大小为{:.2f}MB,创建文件年份为:{}'.format(path0,file_size,file_build_year))
#输出结果为--第一个压缩包的路径名称是:python学习资料.zip,内存大小为136.43MB,创建文件年份为:2019
'''
#应用到全部的路径
for path in paths:
file_size = os.stat(path).st_size/1024/1024
file_build_year = datetime.datetime.fromtimestamp(os.stat(path).st_ctime).year
if (file_size > 100) and (file_build_year < 2020):
print('压缩包的路径名称是:{},内存大小为{:.2f}MB,创建文件年份为:{}'.format(path,file_size,file_build_year))
代码以及输出结果为:

应用总结
在进行列表循环之前可以对列表中的某一个元素进行试错,也就是单独对某一个元素进行分析(直接进行列表循环可能由于文件较多,而影响调试),比如这里使用第一个元素,获取它的路径、内存大小和创建时间,顺利完成后,再遍历循环列表时,只需要将下标索引[0]删除就可以了。
