文章目录
分组查询
回忆一下我们上篇的案例:数据库学习之MySQL (十一)—— 统计函数
原来我们是FROM employees范围内 进行一个统计 比如获得最大值 平均值等,但是实际生活中,总是需要分组查询,比如我统计多个月小店的营销收入,如果不分组,就需要用IF疯狂判断,最恐怖的是,时间越长,你IF条件句越多,一发不可收拾
这时 我们需要给他分组,对每个分组进行相同的操作。
我们将表格稍稍更改为这个样子:
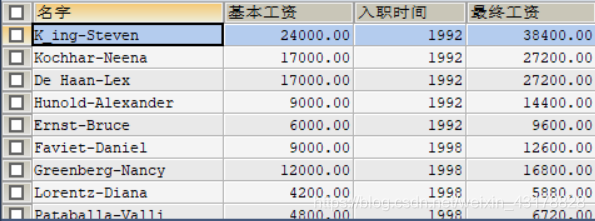
USE data1;
SELECT
CONCAT(`last_name`,'-',`first_name`) 名字,
`salary` 基本工资,
YEAR(IFNULL(`hiredate`, 0)) 入职时间,
CASE
WHEN YEAR(`hiredate`) < 1996
THEN `salary` * (1+0.6+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 1997 AND 2000
THEN `salary` * (1+0.4+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2001 AND 2010
THEN `salary` * (1+0.2+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2011 AND 2014
THEN `salary` * (1+0.1+IFNULL(`commission_pct`, 0))
ELSE `salary` * (1+0.0+IFNULL(`commission_pct`, 0))
END AS 最终工资
FROM
employees
ORDER BY 入职时间 ASC ;
但我很好奇,最终工资与入职时间有没有什么关联,于是,我将入职时间来个GROUP BY,对于每种入职时间,取最高工资来看看效果:

USE data1;
SELECT
CONCAT(`last_name`,'-',`first_name`) 名字,
`salary` 基本工资,
YEAR(IFNULL(`hiredate`, 0)) 入职时间,
MAX(CASE
WHEN YEAR(`hiredate`) < 1996
THEN `salary` * (1+0.6+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 1997 AND 2000
THEN `salary` * (1+0.4+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2001 AND 2010
THEN `salary` * (1+0.2+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2011 AND 2014
THEN `salary` * (1+0.1+IFNULL(`commission_pct`, 0))
ELSE `salary` * (1+0.0+IFNULL(`commission_pct`, 0))
END) AS 每组最高_最终工资
FROM
employees
GROUP BY 入职时间
ORDER BY 入职时间 ASC ;
感觉其实相关性不大 毕竟最老的最高工资可能是老板QAQ:)
没事 把MAX 改成AVG 看看效果:

最年轻的一批工资高,中间的一批最惨,最老的一批很舒服:)
WHERE语句位置问题
GROUP BY 入职时间 整句话和WHERE ORDER BY FROM 都是一样作为SELECT的附加语句,相当于添加了一个Fliter过滤器 那么 既然都是“并列的”附加语句,我随便放怎么样呢?
你可以试一试,但结果是GG
WHERE 筛选器针对于FROM employees 原始表这个范围(可以装逼点:域),最好就放在FROM employees屁股后面,做一个附加的筛选器,
一般而言,WHERE也只能针对某一列(属性 或着说栏目)进行一个WHERE条件筛选 仅此而已
但是有时我们想要获得的参数并不在原始表的列 属性(或者说栏目)里面,
如果只是照着原来的属性,进行一些数学运算,都问题不大,就像之前的:
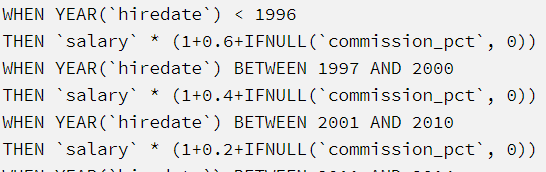
案例我想在之前这个表
筛选 平均最终工资>8000的对象实例(即 行),该怎么办?
分析 你其实是在入职年为1992年、1996年、2000年等的一个一个小表里面,统计一些统计量(平均值)。我们要再从平均値做筛选,其实已经是另一张表做where了
我猜有人会这么写:
USE data1;
SELECT
CONCAT(`last_name`,'-',`first_name`) 名字,
`salary` 基本工资,
YEAR(IFNULL(`hiredate`, 0)) 入职时间,
AVG(CASE
WHEN YEAR(`hiredate`) < 1996
THEN `salary` * (1+0.6+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 1997 AND 2000
THEN `salary` * (1+0.4+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2001 AND 2010
THEN `salary` * (1+0.2+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2011 AND 2014
THEN `salary` * (1+0.1+IFNULL(`commission_pct`, 0))
ELSE `salary` * (1+0.0+IFNULL(`commission_pct`, 0))
END) AS 每组平均_最终工资
FROM
employees
WHERE AVG(CASE
WHEN YEAR(`hiredate`) < 1996
THEN `salary` * (1+0.6+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 1997 AND 2000
THEN `salary` * (1+0.4+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2001 AND 2010
THEN `salary` * (1+0.2+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2011 AND 2014
THEN `salary` * (1+0.1+IFNULL(`commission_pct`, 0))
ELSE `salary` * (1+0.0+IFNULL(`commission_pct`, 0))
END) > 8000
GROUP BY 入职时间
ORDER BY 入职时间 ASC ;
然后收获:

错误原因很清楚:这表不是原来的原始表了,应该说,我们要判断的新属性“平均_最终工资”,不是那种,从原始表,直接套用一个数学代数式就出来了的, 必须分组再统计。也就是,数据源不是原始表。
这时WHERE这种失去意义——他对新的分组后的表无能为力,于是我们迎来了HAVING
HAVING
上面正确的写法应该是:
USE data1;
SELECT
CONCAT(`last_name`,'-',`first_name`) 名字,
`salary` 基本工资,
YEAR(IFNULL(`hiredate`, 0)) 入职时间,
AVG(CASE
WHEN YEAR(`hiredate`) < 1996
THEN `salary` * (1+0.6+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 1997 AND 2000
THEN `salary` * (1+0.4+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2001 AND 2010
THEN `salary` * (1+0.2+IFNULL(`commission_pct`, 0))
WHEN YEAR(`hiredate`) BETWEEN 2011 AND 2014
THEN `salary` * (1+0.1+IFNULL(`commission_pct`, 0))
ELSE `salary` * (1+0.0+IFNULL(`commission_pct`, 0))
END) AS 每组平均_最终工资
FROM
employees
GROUP BY 入职时间
HAVING 每组平均_最终工资 > 8000
ORDER BY 入职时间 ASC ;
ORDER BY位置不限 , 就是个附加品,因为无论是原始表范围还是我们新的分组表范围都能用。
而HAVING一般放在GROUP后面,就类似WHERE在FROM后面一样
总结
WHERE 分组前筛选
HAVING 分组后筛选
为了提升查询效率,建议多在分组前筛选
拓展
我们从WHERE横向拓展为HAVING
从分组前的FROM employees横向拓展为GROUP BY分组后
那么可见 HAVING有类似WHERE的性质,可以接受函数返回值进行筛选 如:
HAVING CHAR_LENGTH(job.id)
同样的:可以根据分组后的数据 进行一些数学代数运算,然后再分组,最简单的莫过于:
GROUP BY job.id+1
或者 GROUP BY CHAR_LENGTH(job.id)
(不记得CHAR_LENGTH() 的同志可以传送去这里:数据库学习之MySQL (九)—— 数学函数 字符串函数)
下一站:
