整体概念图
- 作用是:解耦、削峰、异步处理。
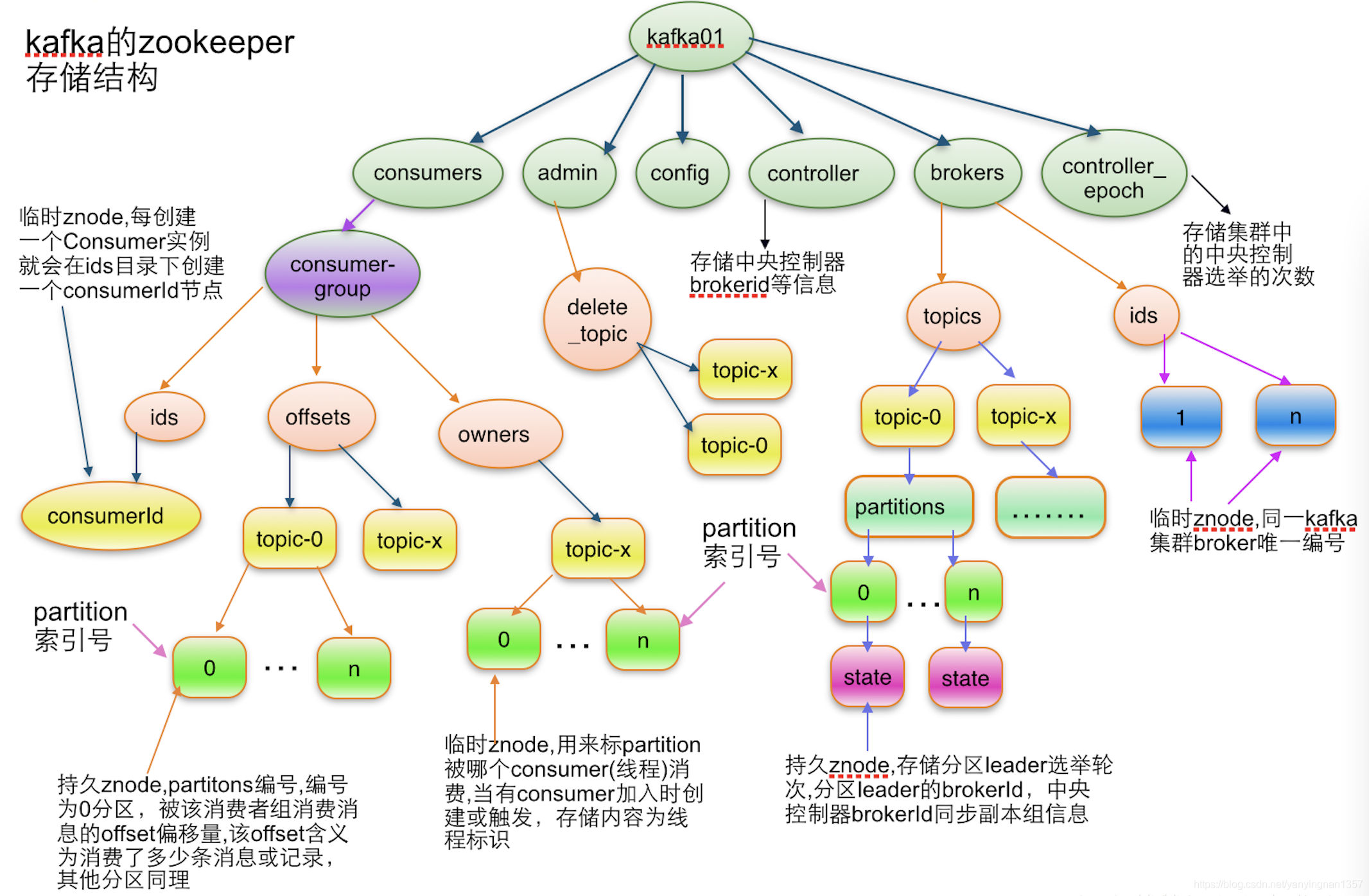
- brokers、topic、partition的相关信息、监控和路由相关信息使用zk存储。
- zk在broker中选出一个controller,用于partition分配和leader选举。
文件存储简述
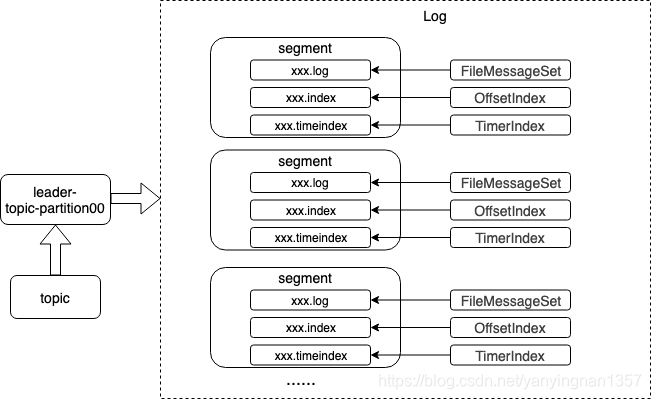
- 每新写一条消息,kafka就是在对应的文件append写,将随机写操作改为顺序写,所以性能非常高
- 使用文件系统和操作系统的页缓存分别存储和缓存消息,结合Zero-Copy,因此IO性能好
- 索引策略是稀疏矩阵法,查找过程采用二分法。
- 一个log文件对应两个索引文件,偏移量索引文件,时间戳索引文件(这个是干啥用?)
- 文件存储方式:
生产消息
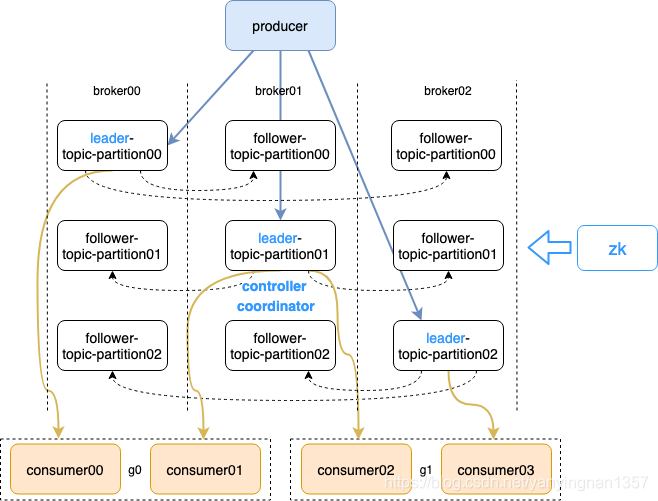
- key参数用来哈希,分配partition使用。
- 一般我们不传key,默认用round-robin轮询负载均衡算法来选partition。
- 有一个broker节点是controller,完成partition分配和leader选举。

消费消息
- 一个消费组里面可以有多个消费者,同一个消费组中的两个消费者,不会同时消费一个partition。
- 一个partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费。
- 从broker中选一个coordinator,用于分配消费那个partition。
- 偏移量索引流程:

- 解决重复消费有两个方法:
1、下游系统保证幂等性,重复消费也不会导致多条记录;
2、把commit offset和业务处理绑定成一个事务。 - reblance触发场景:
1、增加partition
2、增加消费者
3、消费者主动关闭
4、消费者宕机
5、coordinator宕机
zk节点