网上讲解docker详细原理有很多了,我就记录下几个重要概念通过实践来理解
详细可以参考:点击访问
Docker包括三个基本概念:
- 镜像(Image)
- 容器(Container)
- 仓库(Repository)
镜像(Image)
通过base镜像扩展来叠加分层应用给后续的容器使用,也就是说给容器的运行做的准备环境
1、镜像分为二种
- base原镜像,不依赖其他镜像
- 基于base原镜像进行应用扩展
base 镜像提供的是最小安装的 Linux 发行版,比如 Ubuntu, Debian, CentOS
我们大部分镜像都基于base镜像构建的,可以在docker hub里找到。官网地址访问
拉取下载镜像
docker pull ubuntu

注意:TAG标记,一般我们直接拉取到的镜像都是最近的,就是最新的,但是往往我们需要其他的版本,这个TAG就是区别他们

拉取下载镜像
docker pull centos7.7.1908
2、内核空间和用户空间
内核空间是kernel,用户空间是rootfs(根文件系统),不同Linux发行版的区别主要是rootfs.比如 Ubuntu 14.04 使用 upstart 管理服务,apt 管理软件包;而 CentOS 7 使用 systemd 和 yum。这些都是用户空间上的区别,Linux kernel 差别不大。
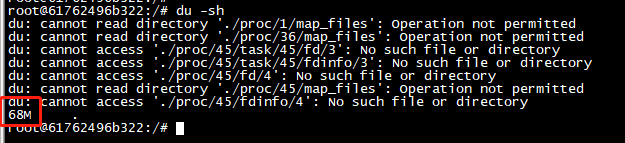
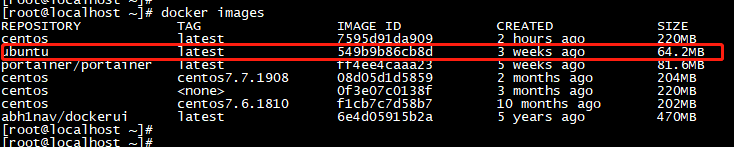
直接查看容器系统的根文件大小,再看镜像的大小,基本能相差不大,docker镜像只是存储用户空间
可以参考:点击访问linux的内核空间和用户空间
可以参考:rootfs的原理和介绍

可以看到镜像文件大小只有几百兆,怎么理解,其实docker镜像只是用户空间也就是根文件,而内核空间是需要共享原主机的内核来实现。也就是我本机linux内核是3.1版本,你容器里的系统也是3.1版本内核
实践查看ubuntu系统内核是否跟宿主机系统内核一样

3、分层结构
镜像其实是由分层结构来存储文件系统,通过不断生成新的叠加层
启动镜像的时候,一个新的可写层会加载到镜像的顶部。这一层通常称为“容器层”, 之下是“镜像层”。
容器层可以读写,容器所有发生文件变更写都发生在这一层。镜像层read-only,只允许读取。

docker history 可以查看镜像分层的步骤

第一层为镜像ID的摘要,作用主要防止真实的镜像文件被篡改
missing:构建缺少的图层id,根据摘要识别下面的层,通过将算法(SHA256)应用于图层内容来计算的。如果内容更改,则计算的摘要也将更改,这意味着Docker可以使用已发布的摘要检查层的检索内容,以验证其内容
参考:点击访问

我创建了一个文件夹,然后进行了封装,也就是docker commit 命令来提交更新后的副本,创建了一个新的镜像
可以看到新增了一个镜像id,我新的操作被当做层来存储的,对于用户看到的只有一个文件对象,原镜像的大小是没有发生变化的,也就是说base镜像可以被多次共享使用,达到节省系统资源的目的,不同的应用只是针对新加的层的改变而已。
容器(Container)
基于镜像运行的实体进程
上面提到,容器层可以读写,容器所有发生文件变更写都发生在这一层。镜像层read-only,只允许读取。
而存储结构就是镜像层上面加一层容器层

创建镜像的时候,分层可以让docker只保存我们添加和修改的部分内容。其他内容基于base镜像,不需要存储,读取base镜像即可。如此,当我们创建多个镜像的时候,所有的镜像共享base部分。节省了磁盘空间。
对于启动的容器,查看容器空间可以通过docker ps -s


SIZE大小为容器层的大小,后面的virtual为容器层+镜像层的大小,第一个容器我测试自己上传了一个文件后,再次查看大小就发生了变化,镜像层的大小还是没变的,71-6.76=64.2
上传命令
docker cp 本地文件路径 ID全称:容器路径
docker cp 538133.exe 61762496b322:/root
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等 。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间,为了起到隔离的作用
参考:docker命名空间
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
按照Docker最佳实践的要求,容器不应该向其存储层内写入任何数据 ,容器存储层要保持无状态化。所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, 使用数据卷后,容器可以随意删除、重新run,数据却不会丢失。
参考:点击访问
这个就是体现容器的优势地方,我能起几十个容器运行稳定,启动速度快等等,因为底层的镜像都是一个,多出来的只是新层的进程消耗而已。
仓库(Repository)
方便远程使用镜像专门存储的地方
一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本 。我们可以通过<仓库名>:<标签>的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
仓库可以分为两种形式:
public(公有仓库)
private(私有仓库)
公有仓库就类似我们代码放到GitHub上一样
私有仓库就类似自己搭建的Gitlab一样,一般企业肯定是要有自己的仓库的
分层概念参考:点击访问
