全为笔记,复习完整本书再做修改。
循环链表
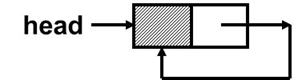
1.循环链表结构设计
循环链表要解决的问题:不从头结点出发,也能访问所有结点,求补充。
循环链表是表中最后一个结点的指针指向头结点,使链表构成环状。
2.循环链表的运算
运算与单链表基本一致,主要有以下不同:
1)在建立一个循环链表时,必须使其最后一个结点的指针指向表头结点,而不是像单链表那样置为NULL。
2)在判断是否到表尾时,则判断该结点链域的值是否是表头结点,当链域值等于表头指针时,说明已到表尾。而非像单链表那样判断链域值是否为NULL。
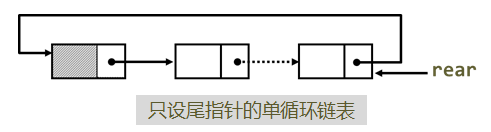
【例子】建立循环链表
利用尾插法建立链表函数Create_Rear_LkList, 将返回前的p->next=NULL改为p->next= head即可。
/*===================================================
函数功能:单链表操作--建立循环链表
函数输入:链表结点值数组,结点数目
函数输出:循环链表尾地址
====================================================*/
LinkListNode *Create_Circle_LkList(ElemType a[],int n )
{
LinkListNode *head,*p, *q;
int i;
?
head=(LinkListNode *)malloc(sizeof(LinkListNode));
q=head;
for(i=0;i<n;i++)
{
p=(LinkListNode *)malloc(sizeof(LinkListNode));
p->data=a[i];
q->next=p;
q=p;
}
p->next=head;
return p;
}
【例】将两个蛋循环链表链接成一个单循环链表
接口信息:
输入:两循环链表尾指针 ra 、rb
输出:无
图中的“内存池”是内存中一块空闲可用的空间
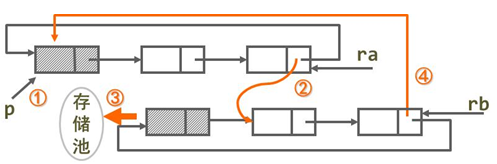
合并步骤:

程序如下:
/*===========================================
函数功能:将两个单循环链表a、b链接成一个
函数输入:链表a尾指针,链表b尾指针
函数输出:无
=============================================*/
void Connect-_L(LinkListNode *ra, LinkListNode *rb)
{
LinkListNode *p;
p=ra->next;
ra->next=rb->next->next;
free(rb->next);
rb->next=p;
}
若在单链表或头指针表示的单循环表上做这种链接操作,都需要遍历第一个链表,找到结点an,然后将结点b1链到an的后面,其执行时间是O(n)。在尾指针表示的单循环链表上实现,则只需修改指针,无须遍历,其执行时间是O(1)。
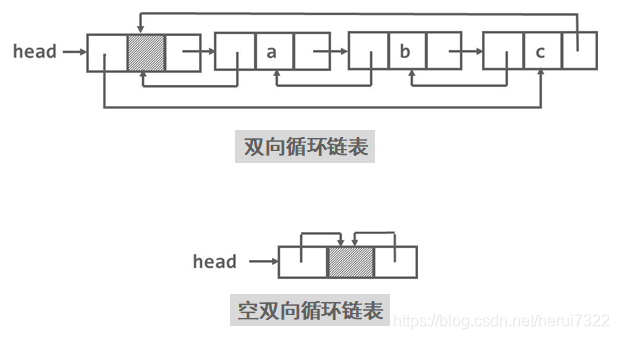
双向链表
1.双向链表的结构设计
在链表的结点中有两个指针域,其一指向直接后继,另一指向直接前趋。

双向链表结点类型的定义:
typedef struct Dnode
{ ElemType data;
struct Dnode *prior,*next;
} DLinkListNode;
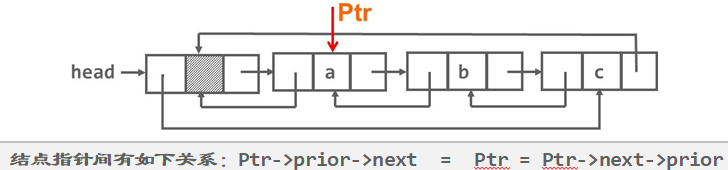
2.双向链表的运算
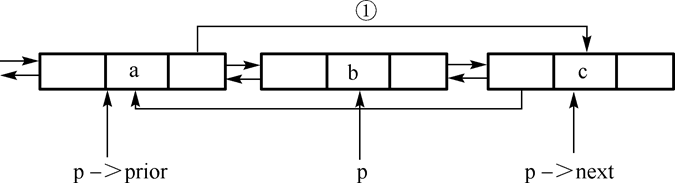
1)删除双向链表中地址为p的结点

/*===================================================
函数功能:在双向链表中删除指定的结点Ptr
函数输入:待删除结点地址Ptr
函数输出:被删除结点Ptr的地址
=====================================================*/
DLinkListNode * Delete_DL( DLinkListNode *Ptr )
{
Ptr->prior->next=Ptr->next;
Ptr->next->prior=Ptr->prior;
return Ptr; //注意Ptr结点从链表中删除,但未在本函数释放
}
/*=====================================================
函数功能:在双向链表中删除第i个结点
函数输入:双向链表首地址,待删除结点编号
函数输出:双向链表首地址
=======================================================*/
DLinkListNode *Delete_i_DL( DLinkListNode *head, int i)
{
DLinkListNode *Ptr;
Ptr=Get_DL(head,i); //找到i结点的地址
if (Ptr!=NULL)
{
Ptr=Delete_DL(Ptr);//删除结点Ptr
} return Ptr;
}
/*==============================================
函数功能:找到第i个结点的地址(跳过头结点)
函数输入:双链表首地址,待查找结点编号i
函数输出:i结点地址
================================================*/
DLinkListNode *Get_DL(DLinkListNode *head,int i)
{
int j=1;
DLinkListNode *Ptr;
Ptr=head->next;
while (j++<i) Ptr=Ptr->next;
return Ptr;
}
为了处理异常情形方便,依然采取单链表的删除方式,即给出要删除的结点序号,通过“按序号查找”函数,找到结点地址,无异常时,再进行删除。
2)双向链表的插入运算
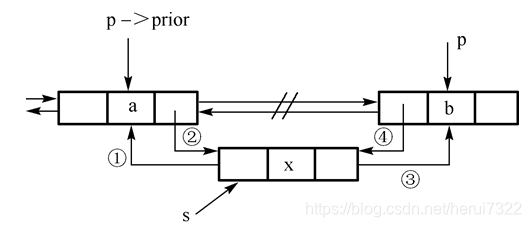
在双向链表地址为p的结点前插入一个值为x的新结点。

/*===========================================
函数功能:双链表在指定结点前的插入运算
函数输入:指定结点地址,插入结点的值
函数输出:无
=============================================*/
void Insert_Before_DL(DLinkListNode *p, ElemType x)
{
DLinkListNode *s;
s=(DLinkListNode*)malloc(sizeof(DLinkListNode));
s->data=x;
s->prior=p->prior;
if (p->prior!=NULL) p->prior->next=s;
s->next=p;
p->prior=s;
}
说明:对指定结点地址做插入与删除的操作函数,都未对输入的结点地址做异常情形的判断,因此需要在调用前做好异常处理,确保输入的地址是正确的。
