一.递归神经网络RNN简介
BP神经网络和CNN的输入输出都是互相独立的;但是实际应用中有些场景输出内容和之前的内 容是有关联的。 RNN引入“记忆”的概念;递归指其每一个元素都执行相同的任务,但是输出依赖于输入和“记忆”
bp神经网络和卷积神经网络这两种结构有一个特点,就是假设输入是一个独立的没有上下文联系的单位。但是对于一些有明显的上下文特征的序列化输入,比如预测视频中下一帧的播放内容,那么很明显这样的输出必须依赖以前的输入, 也就是说网络必须拥有一定的”记忆能力”。为了赋予网络这样的记忆力,一种特殊结构的神经网络——递归神经网络(Recurrent Neural Network)便应运而生了
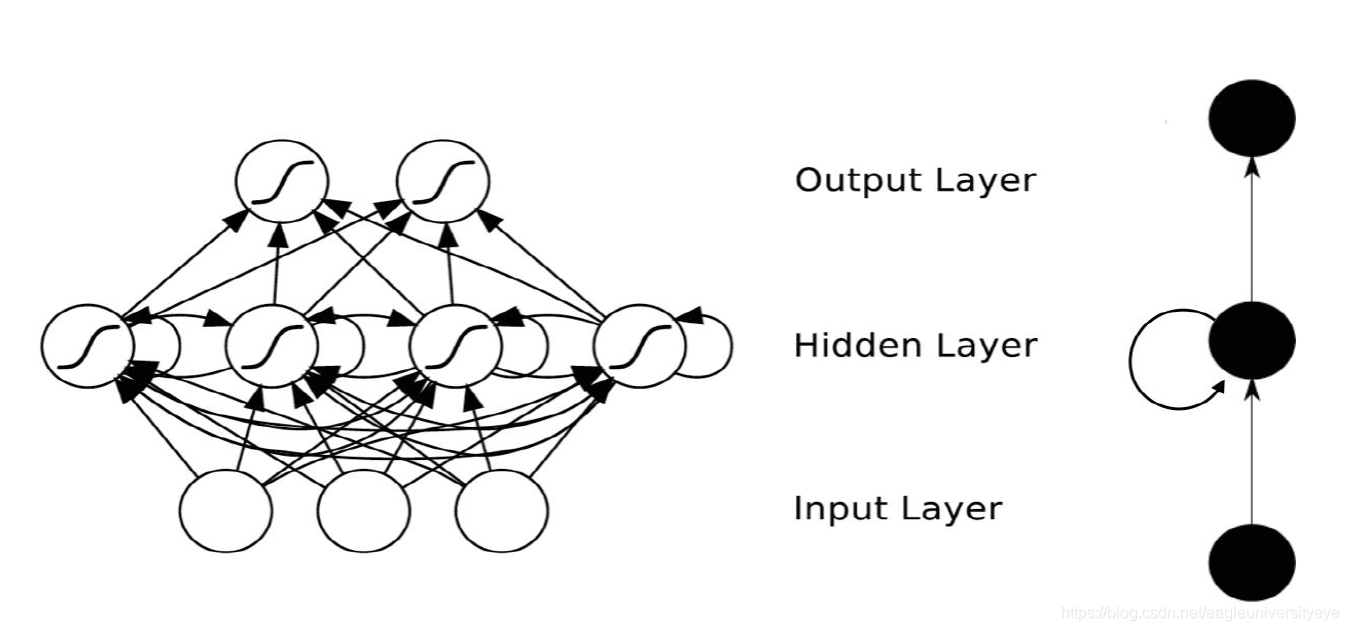
下图为RNN的工作状态图(下文会详细讲解RNN的工作原理):
同一个神经元在不同时刻的状态构成了RNN神经网络
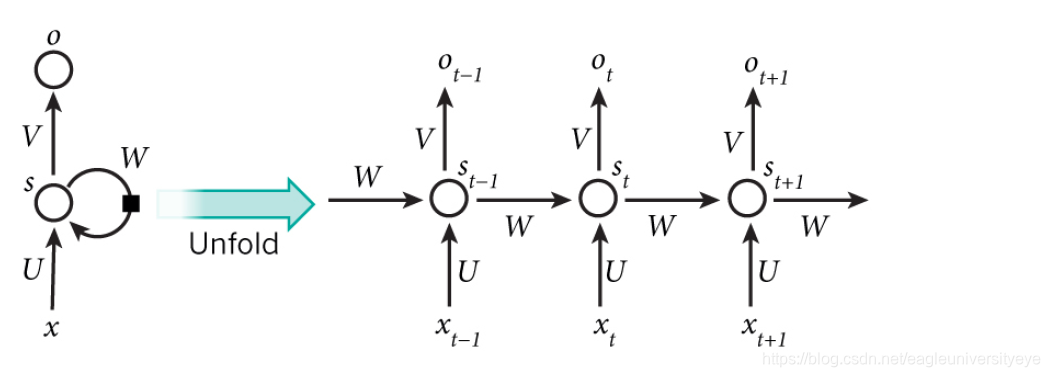
 将同一个神经元,展开为在t-1、t、t+1三个时刻的状态,这三个时刻状态构成了一个网络。RNN通过将前一时刻的数据加入运算,使神经网络具有了记忆功能
将同一个神经元,展开为在t-1、t、t+1三个时刻的状态,这三个时刻状态构成了一个网络。RNN通过将前一时刻的数据加入运算,使神经网络具有了记忆功能
二.RNN递归神经网络工作原理
网络某一时刻的输入Xt,和之前介绍的bp神经网络的输入一样,xt是一个n维向量,不同的是递归网络的输入将是一整个序列,也就是X=[X1,…,Xt-1,Xt,Xt+1,…XT]。对于语言模型,每一个Xt代表一个词向量,一整个序列就代表一句话
RNN神经网络中的神经元进行的数学计算可由方程St=f(U×Xt+W×S(t-1))来表达,其中Xt是时间t处的输入,St是时间t处的“记忆”,f可以是非线性转换函数,比如tanh等,Ot是时间t处的输出,比如是预测下一个词的话,可能是sigmoid(softmax)输出的属于每个候选词的概率,Ot=softmax(V×St)。按照一定的时间序列规定好计算顺序,将这样带环的结构展开成一个序列网络,也就是下图一个神经元被展开(unfold)之后的结构,其中ht代表时刻t的隐藏状态,xt代表时刻t的输入。将一个神经元序列按时间展开就可以得到RNN的结构
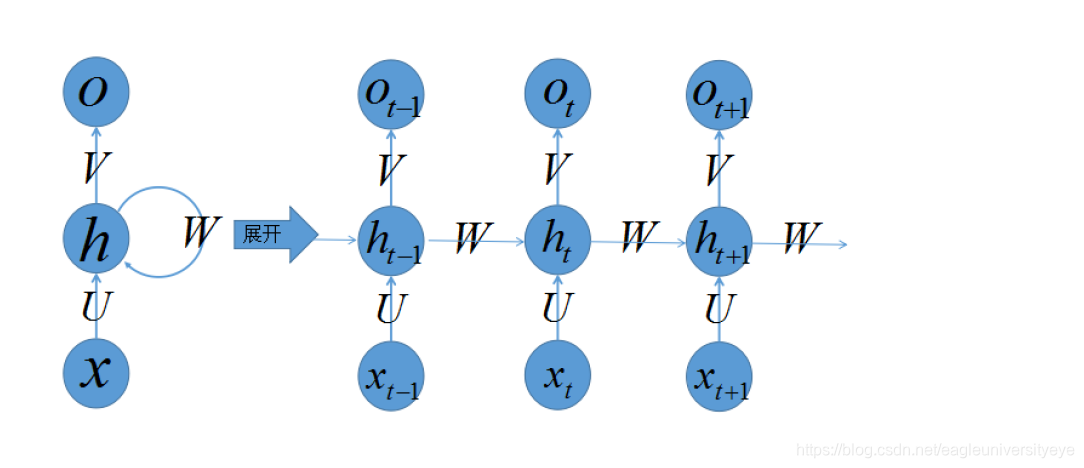
在t=0的时刻,U,V,W都被随机初始化好,h0通常初始化为0,然后进行如下计算:
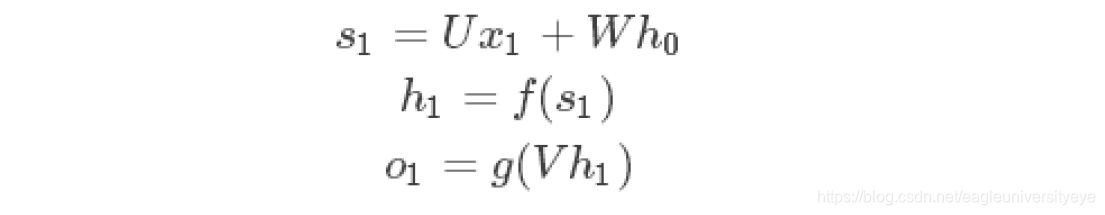 时间就向前推进,此时的状态h1作为时刻0的记忆状态将参与下一次的预测活动,也就是:
时间就向前推进,此时的状态h1作为时刻0的记忆状态将参与下一次的预测活动,也就是:
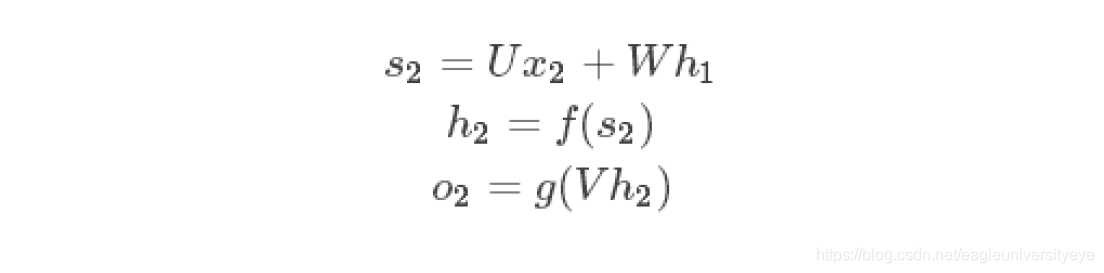 以此类推,可得任意时刻t,神经元的计算过程
以此类推,可得任意时刻t,神经元的计算过程
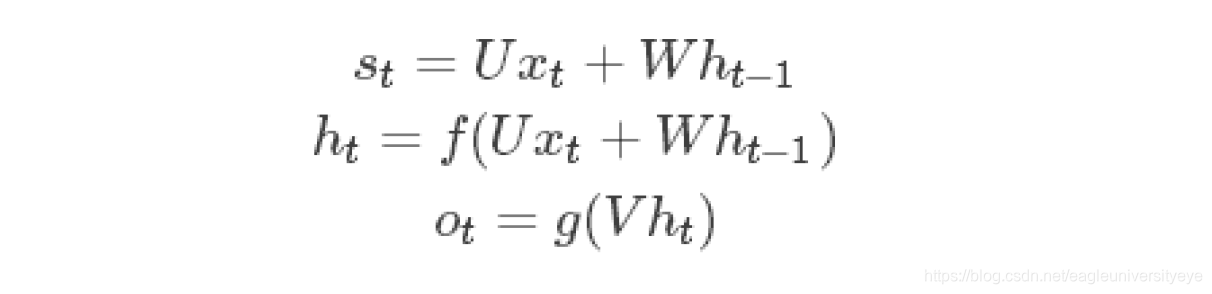
上式中,f可以是tanh,relu,logistic等激活函数,g通常是softmax,也可以是其他。 值得注意的是,我们说递归神经网络拥有记忆能力,而这种能力就是通过W将以往的输入状态进行总结,而作为下次输入的辅助,可以这样理解隐藏状态:h=f(现有的输入+过去记忆总结)
RNN递归神经网络更新权重的方式
bp神经网络用到误差反向传播方法将输出层的误差总和,对各个权重的梯度∇U,∇V,∇W,求偏导数,然后利用梯度下降法更新各个权重
对于每一时刻t的RNN网络,网络的输出ot都会产生一定误差et,误差的损失函数,可以是交叉熵也可以是平方误差等等。那么总的误差为E=Σtet,我们的目标就是要求取各个权重(U、V、W)对总误差的偏导
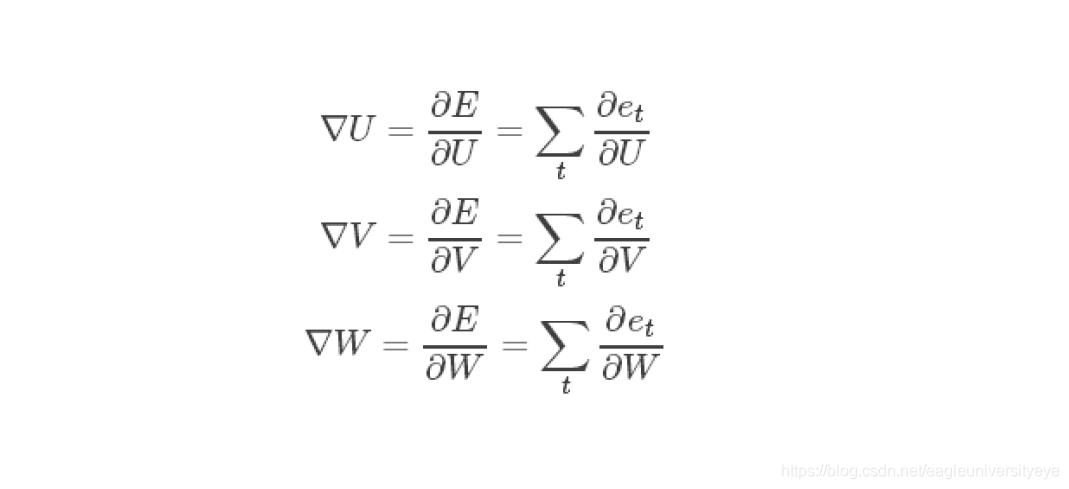 对于输出ot=g(Vst),任意损失函数,求∇V是非常简单的,我们可以直接求取每个时刻的∂Et / ∂V,由于它不存在和之前的状态依赖,可以直接求导取得,然后简单地求和即可。对于∇W、∇U的计算不能直接求导,需要用链式求导法则。 为了使得误差E能够对U和W求偏导数,定义一个δ=∂E/∂S,首先计算出输出层的δL,再向后传播到各层δL-1,δL-1,…
对于输出ot=g(Vst),任意损失函数,求∇V是非常简单的,我们可以直接求取每个时刻的∂Et / ∂V,由于它不存在和之前的状态依赖,可以直接求导取得,然后简单地求和即可。对于∇W、∇U的计算不能直接求导,需要用链式求导法则。 为了使得误差E能够对U和W求偏导数,定义一个δ=∂E/∂S,首先计算出输出层的δL,再向后传播到各层δL-1,δL-1,…
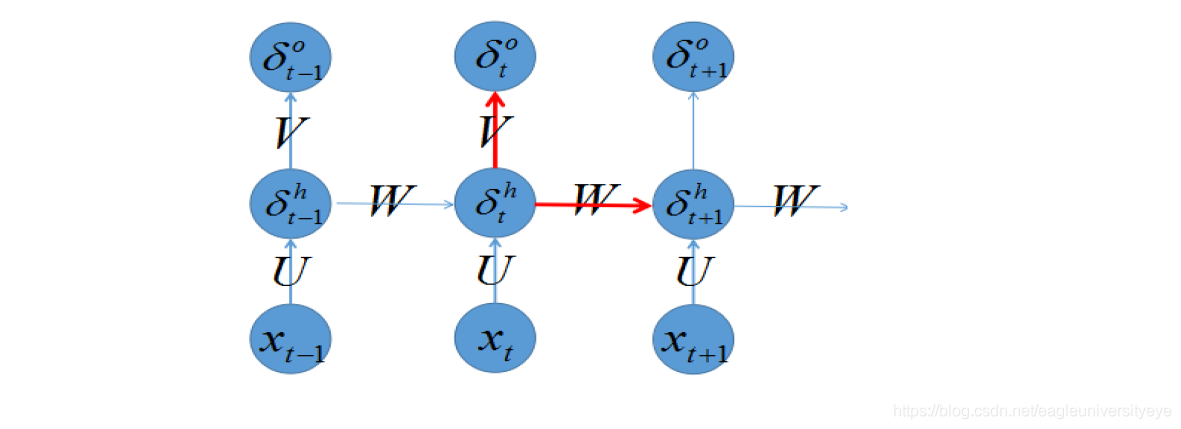 某一个神经元在t时刻的δt的计算公式
某一个神经元在t时刻的δt的计算公式
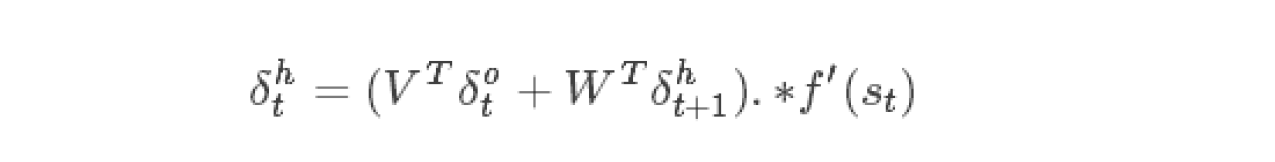
只要计算出所有的δot,δht,就可以通过以下计算出∇W,∇U
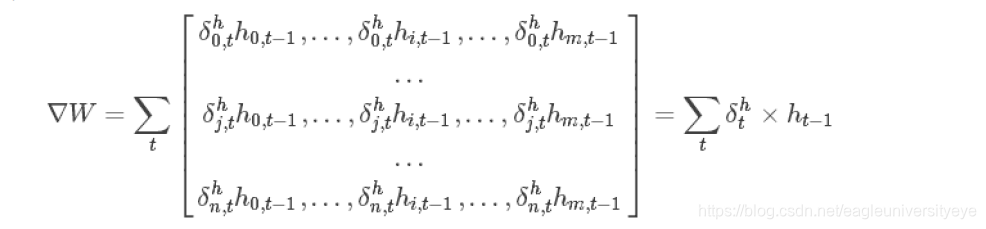
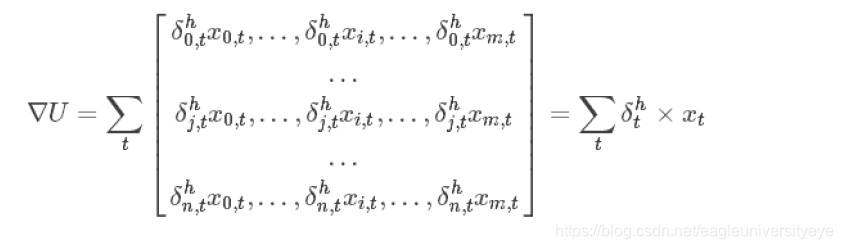
下文举例说明W的梯度的计算方法:
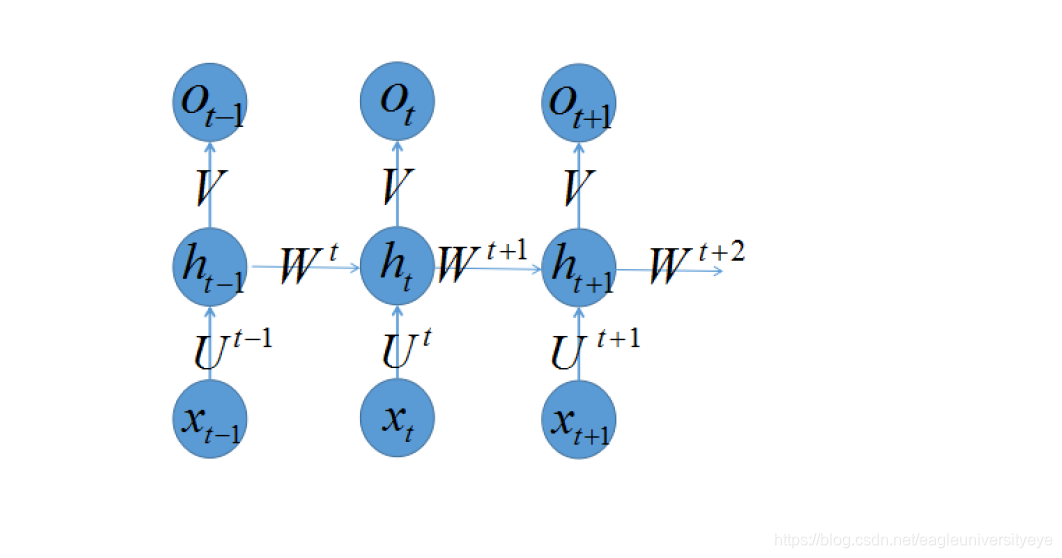 对于时刻t+1产生的误差Et+1,计算它对于W1,W2,…,Wt,Wt+1的梯度:
对于时刻t+1产生的误差Et+1,计算它对于W1,W2,…,Wt,Wt+1的梯度:
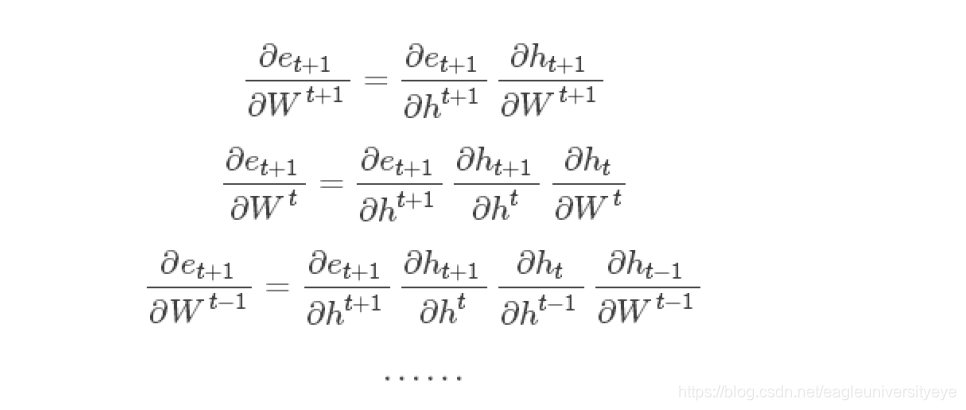
反复运用链式法则,我们可以求出每一个∇W1,∇W2,…,∇Wt,∇Wt+1
在不同时刻共享同样的参数,可以大大减少训练参数,和CNN的共享权重类似。对于共享参数的RNN,我们只需将上述的一系列式子抹去标签并求和,就可以得到 :
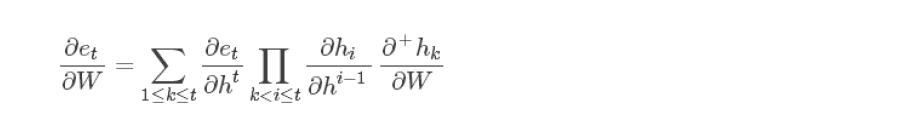 其中 ∂+×hk/∂W 表示不利用链式法则直接求导,也就是假如对于函数f(h(x)),对其直接求导结果为:∂f(h(x))/∂x=f′(h(x)),也就是求导函数可以写成x的表达式,即将h(x)看成常数
其中 ∂+×hk/∂W 表示不利用链式法则直接求导,也就是假如对于函数f(h(x)),对其直接求导结果为:∂f(h(x))/∂x=f′(h(x)),也就是求导函数可以写成x的表达式,即将h(x)看成常数
RNN的缺陷
在上面得到的权值对总偏差的偏导的计算公式中,经过实验论证,发现该公式有一个规律:
 这说明权值对总误差的偏导有一部分环节是指数模型,根据指数函数的性质,可以推测出,当η<1时,就会出现梯度消失,而当η>1时,会出现梯度爆炸
这说明权值对总误差的偏导有一部分环节是指数模型,根据指数函数的性质,可以推测出,当η<1时,就会出现梯度消失,而当η>1时,会出现梯度爆炸
为了克服梯度消失的问题,LSTM和GRU模型便后续被推出了,LSTM和GRU都有特殊的方式存储”记忆”,以前梯度比较大的”记忆”不会像RNN一样马上被抹除,因此可以一定程度上克服梯度消失问题。
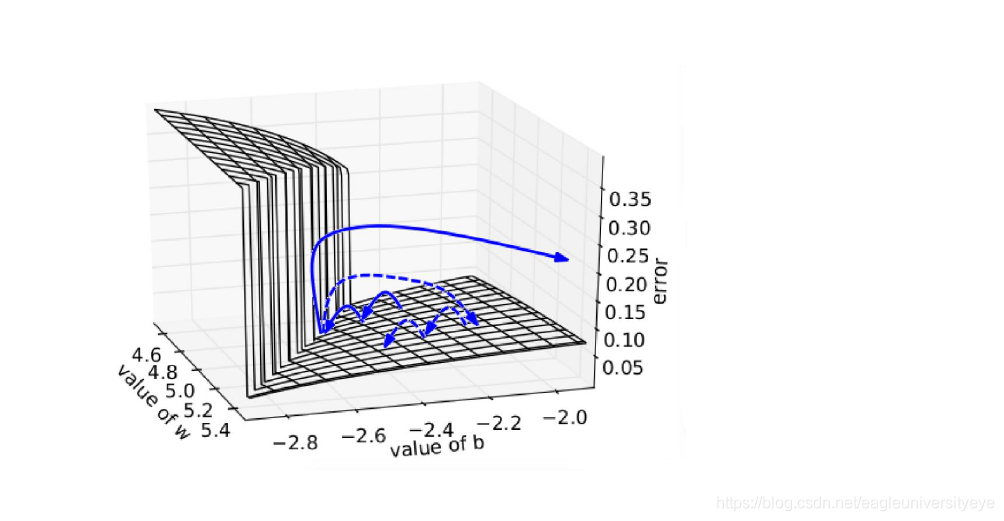
另一个简单的技巧gradient clipping可以用来克服梯度爆炸的问题,也就是当你计算的梯度超过阈值c的或者小于阈值−c时候,便把此时的梯度设置成c或−c。下图所示是RNN的误差平面,可以看到RNN的误差平面要么非常陡峭,要么非常平坦,如果不采取任何措施,当你的参数在某一次更新之后,刚好碰到陡峭的地方,此时梯度变得非常大,那么你的参数更新也会非常大,很容易导致震荡问题。而如果你采取了gradient clipping,那么即使你不幸碰到陡峭的地方,梯度也不会爆炸,因为梯度被限制在某个阈值c