文章目录
前言
在分析过前两节(服务端启动、Reactor线程模型)之后,我们再来介绍一下,pipeline的传播机制。
在前两篇的分析中,不断的出现了pipeline,出镜率极高,其作用在Netty也是非常重要的,加上前两篇文章,这三篇文章算得上介绍了Netty中的“三板斧”(三大组件Channel、EventLoop、Pipeline),所以对于理解好Netty,理解这三大组件是必不可少的。
pipeline就像一条工厂流水线(责任链模式),其中流水头尾都有一个固定的Handler处理把关,流水中间部分Handler由用户自定义,想要产品最终变成什么样被生产出去,由用户自由组装Handler处理决定,在可扩展性方面来说是相当灵活的,因为如果要新的什么功能或是新的什么处理,在流水线中新增一个Handler即可,不需要的时候,就不要这个Handler,对于功能的增删是非常便利的。当然,pipeline还自带动态增删Handler的功能,这样一个灵活的设计思想,值得学习。
Pipeline初始化
在第一篇文章服务端启动中,我们可以知道,每创建一个Channel,都会在其内部创建一个pipeline
protected AbstractChannel(Channel parent) {
this.parent = parent;
id = newId();
unsafe = newUnsafe();
// 在Channel的构造函数中,初始化pipeline
pipeline = newChannelPipeline();
}
以此为入口,来分析一下pipeline的初始化
protected DefaultChannelPipeline newChannelPipeline() {
return new DefaultChannelPipeline(this);
}
这个方法,实际上传入了一个Channel实例,表示一个Channel跟一个pipeline实例一一对应。可以知道,这里Pipeline是DefaultChannelPipeline这个实现类,进入该类的构造函数
protected DefaultChannelPipeline(Channel channel) {
// 将channel保存起来,这里可以知道,可以通过pipeline拿到channel
this.channel = ObjectUtil.checkNotNull(channel, "channel");
succeededFuture = new SucceededChannelFuture(channel, null);
voidPromise = new VoidChannelPromise(channel, true);
// 在头尾创建了两个context守护头尾
tail = new TailContext(this);
head = new HeadContext(this);
// 双向链表的结构
head.next = tail;
tail.prev = head;
}
其实在第一篇文章中,已经介绍了头尾两个Conetxt,也介绍了一个Handler其实是对应一个Context的,可以把Context对象看成是Handler的封装类。可以看到,这里conetxt在pipeline中的数据结构是一个双向链表,由此可以知道,我们可以从head从下访问Handler直到tail,也可以从tail往上访问所有Handler直到head
Pipeline数据结构
这里先来介绍一下pipeline的数据结构,从上面的介绍可以知道,首先在pipeline初始化的时候构造了一个头尾Context的双向链表结构,那么我们再来看看,若添加Handler会发生什么
private void addLast0(AbstractChannelHandlerContext newCtx) {
AbstractChannelHandlerContext prev = tail.prev;
newCtx.prev = prev;
newCtx.next = tail;
prev.next = newCtx;
tail.prev = newCtx;
}
private void addFirst0(AbstractChannelHandlerContext newCtx) {
AbstractChannelHandlerContext nextCtx = head.next;
newCtx.prev = head;
newCtx.next = nextCtx;
head.next = newCtx;
nextCtx.prev = newCtx;
}
首先addLast顾名思义,其将元素添加到了tail前面,而addFirst将元素添加到了head后面

大致流程如图所示,到这里,读者应该能明白pipeline的数据结构
传播事件
接下来,我们来介绍事件的传播走向。
首先,传播事件有两种方式
-
调用pipeline进行传播
// pipeline.fireChannelRead() public final ChannelPipeline fireChannelRead(Object msg) { AbstractChannelHandlerContext.invokeChannelRead(head, msg); return this; } -
调用pipeline中的某个Conetxt进行传播
// context.fireChannelRead() public ChannelHandlerContext fireChannelRead(final Object msg) { invokeChannelRead(findContextInbound(MASK_CHANNEL_READ), msg); return this; }
那么,这两种传播方式又有什么区别呢?
头尾传播
首先介绍一下pipeline的传播方式。
- 读传播(fireRead)
可以看到,在fireChannelRead方法中,调用了AbstractChannelHandlerContext的静态方法invokeChannelRead去传播事件,并且值得一提的是,此时参数传入的是headContext。进入该方法看看
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
// 从context中拿到EventLoop,目的是检测是否是发动机线程在执行
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
// 执行context的invokeChannelRead方法
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
可以看到,pipeline的传播和context的传播区别并不大,pipeline的传播到最后也会调用到context的传播方法,只不过pipeline的读传播事件会从headContext先发起,从上往下传播
- 写传播
当调用pipeline的写方法时,首先会从tail进行传播
public final ChannelFuture write(Object msg) {
return tail.write(msg);
}
其会找到pipeline的OutBound类型的Handler,从下往上传播
那么我们这里进行总结
- 由head开始的往下传播的事件
- fireChannelActive
- fireChannelInactive
- fireExceptionCaught
- fireChannelRead
- fireChannelReadComplete
- …等等
- 由tail开始的往上传播的事件
- bind
- connect
- write
- flush
- …等等
Context传播
上面介绍了从pipeline开始传播的传播方式,可见其只不过是从头尾开始传播,最终还是调用了context进行事件的传播,而直接context传播与pipeline的区别只不过是起始的传播点不同而已。这里开始分析context的传播方法
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(MASK_CHANNEL_READ), msg);
return this;
}
可以看到,这里在传播之前,先寻找一个Inbound的Conetxt传递进去
private AbstractChannelHandlerContext findContextInbound(int mask) {
AbstractChannelHandlerContext ctx = this;
do {
// 一直往下找
ctx = ctx.next;
// 直到找到一个Inbound类型的Context
} while ((ctx.executionMask & mask) == 0);
return ctx;
}
那么如何区别Inbound和Outbound呢?在旧版本中,Netty使用instanceof的方式来判断如果是ChannelInbound的子类,就是Inbound,如果是ChannelOutbound的子类,就是Outbound。在新版本中,Netty使用位运算来判断,并且粒度更细,判断粒度从inbound和outbound级别到事件级别,更加突出了事件驱动的思想,在配置Handler的时候也更加的灵活了,不需要去重复经过不关心某个事件的Handler。
传播粒度
static final int MASK_EXCEPTION_CAUGHT = 1;
static final int MASK_CHANNEL_REGISTERED = 1 << 1;
static final int MASK_CHANNEL_UNREGISTERED = 1 << 2;
static final int MASK_CHANNEL_ACTIVE = 1 << 3;
static final int MASK_CHANNEL_INACTIVE = 1 << 4;
static final int MASK_CHANNEL_READ = 1 << 5;
static final int MASK_CHANNEL_READ_COMPLETE = 1 << 6;
static final int MASK_USER_EVENT_TRIGGERED = 1 << 7;
static final int MASK_CHANNEL_WRITABILITY_CHANGED = 1 << 8;
static final int MASK_BIND = 1 << 9;
static final int MASK_CONNECT = 1 << 10;
static final int MASK_DISCONNECT = 1 << 11;
static final int MASK_CLOSE = 1 << 12;
static final int MASK_DEREGISTER = 1 << 13;
static final int MASK_READ = 1 << 14;
static final int MASK_WRITE = 1 << 15;
static final int MASK_FLUSH = 1 << 16;
可以看到,这里使用了16位的二进制位来表示各个事件,那么在什么时候配置具体关心的事件呢?我们可以看一下Context 的executionMask变量在哪里被写入
AbstractChannelHandlerContext(DefaultChannelPipeline pipeline, EventExecutor executor,
String name, Class<? extends ChannelHandler> handlerClass) {
this.name = ObjectUtil.checkNotNull(name, "name");
this.pipeline = pipeline;
this.executor = executor;
this.executionMask = mask(handlerClass);
// Its ordered if its driven by the EventLoop or the given Executor is an instanceof OrderedEventExecutor.
ordered = executor == null || executor instanceof OrderedEventExecutor;
}
搜索了一下,可以看到,其值是在构造函数的时候被赋予的,调用了mask方法进行计算
static int mask(Class<? extends ChannelHandler> clazz) {
// Try to obtain the mask from the cache first. If this fails calculate it and put it in the cache for fast
// lookup in the future.
// 缓存
Map<Class<? extends ChannelHandler>, Integer> cache = MASKS.get();
Integer mask = cache.get(clazz);
if (mask == null) {
// 计算
mask = mask0(clazz);
cache.put(clazz, mask);
}
return mask;
}
由于这里有可能会有重复的Handler一直被初始化,一直需要计算它的mask值(一个新连接接入时,要构造其pipeline中的所有Handler,如果不是配置的共享Handler,就会一次次的重复计算mask),所以这里有必要用到缓存。接着进入mask0方法
private static int mask0(Class<? extends ChannelHandler> handlerType) {
// mask = 1
int mask = MASK_EXCEPTION_CAUGHT;
try {
// instanceof 判断是否是Inbound类型
if (ChannelInboundHandler.class.isAssignableFrom(handlerType)) {
// 或上 MASK_ALL_INBOUND,添加所有inbound关心的事件位
mask |= MASK_ALL_INBOUND;
// 是否需要跳过
if (isSkippable(handlerType, "channelRegistered", ChannelHandlerContext.class)) {
// 表示此Handler并不关心此事件,将对应位上的数字变为相反,即1->0
// 这里registered事件为二进制第二位为1,则跳过的话,将第二位变为0
mask &= ~MASK_CHANNEL_REGISTERED;
}
if (isSkippable(handlerType, "channelUnregistered", ChannelHandlerContext.class)) {
mask &= ~MASK_CHANNEL_UNREGISTERED;
}
// 略过重复操作...
}
// Outbound类型的处理
if (ChannelOutboundHandler.class.isAssignableFrom(handlerType)) {
mask |= MASK_ALL_OUTBOUND;
if (isSkippable(handlerType, "bind", ChannelHandlerContext.class,
SocketAddress.class, ChannelPromise.class)) {
mask &= ~MASK_BIND;
}
// 略过重复操作...
}
// 无关Inbound和Outbound,都可以关心的事件
if (isSkippable(handlerType, "exceptionCaught", ChannelHandlerContext.class, Throwable.class)) {
// 若需要跳过,改变位
mask &= ~MASK_EXCEPTION_CAUGHT;
}
}
return mask;
}
那么是如何判断可以被跳过的呢?
private static boolean isSkippable(
final Class<?> handlerType, final String methodName, final Class<?>... paramTypes) throws Exception {
return AccessController.doPrivileged(new PrivilegedExceptionAction<Boolean>() {
@Override
public Boolean run() throws Exception {
Method m;
try {
// 反射获取该事件的方法对象
m = handlerType.getMethod(methodName, paramTypes);
} catch (NoSuchMethodException e) {
logger.debug(
"Class {} missing method {}, assume we can not skip execution", handlerType, methodName, e);
// 没有该方法,直接跳过
return false;
}
// 如果有该方法,查看是否被打上了@Skip注解
return m != null && m.isAnnotationPresent(Skip.class);
}
});
}
到这里我们明白了,首先是具体到Inbound、Outbound纬度来添加事件,然后再在事件的维度一个个去删除不关心的事件,而判断是否不关心,依赖于方法上是否有@Skip注解。
那么在添加事件的开头,MASK_ALL_INBOUND和MASK_ALL_OUTBOUND又是什么呢?
private static final int MASK_ALL_INBOUND = MASK_EXCEPTION_CAUGHT | MASK_CHANNEL_REGISTERED |
MASK_CHANNEL_UNREGISTERED | MASK_CHANNEL_ACTIVE | MASK_CHANNEL_INACTIVE | MASK_CHANNEL_READ |
MASK_CHANNEL_READ_COMPLETE | MASK_USER_EVENT_TRIGGERED | MASK_CHANNEL_WRITABILITY_CHANGED;
private static final int MASK_ALL_OUTBOUND = MASK_EXCEPTION_CAUGHT | MASK_BIND | MASK_CONNECT | MASK_DISCONNECT |
MASK_CLOSE | MASK_DEREGISTER | MASK_READ | MASK_WRITE | MASK_FLUSH;
这里我们可以总结一下:
- InboundHandler关心的事件:
- MASK_EXCEPTION_CAUGHT
- MASK_CHANNEL_REGISTERED
- MASK_CHANNEL_ACTIVE
- MASK_CHANNEL_READ
- MASK_CHANNEL_READ_COMPLETE
- …等等
- OutboundHanlder关心的事件:
- MASK_EXCEPTION_CAUGHT
- MASK_BIND
- MASK_CLOSE
- MASK_READ
- MASK_WRITE
- MASK_FLUSH
- …等等
所以,这里我需要写一个Handler来处理客户端发来的消息,我可以继承ChannelInboundHandler类,然后在其他方法上全打上@Skip注解,只有channelRead不打上@Skip注解,然后在该方法中实现处理消息到来时的业务逻辑。其实ChannelInboundHandlerAdapter、ChannelOutboundHandlerAdapter帮我们做了这一点,我们继承此类并覆写关心的方法即可,极为方便。
传播事件
到这里我们才真正开始讲传播的事件流向,首先每个Context的executionMask是在初始化的时候就已经计算好了,那么这里我们只需要与上某个需要传播的事件的位数即可,若我现在需要找到对读事件感兴趣的Context,那么需要判断executionMask的第六位是否为1即可
private AbstractChannelHandlerContext findContextInbound(int mask) {
AbstractChannelHandlerContext ctx = this;
do {
// 向下寻找
ctx = ctx.next;
} while ((ctx.executionMask & mask) == 0);
return ctx;
}
private AbstractChannelHandlerContext findContextOutbound(int mask) {
AbstractChannelHandlerContext ctx = this;
do {
// 向上寻找
ctx = ctx.prev;
} while ((ctx.executionMask & mask) == 0);
return ctx;
}
可以看出,在inbound事件是向下的顺序进行传播的,而outbound事件是向上的顺序进行传播的。那么找到了对应的context,接下来就是执行context的某个方法了
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
...
next.invokeChannelRead(m);
...
}
private void invokeChannelRead(Object msg) {
// 在Context被添加到pipeline后会设置一个context被添加完成的标志位
// 这里确保context被添加完成,才会开始事件的执行,不然就往下继续传播
// 也可以不在乎顺序,像Tail、Head这类Context就不在乎顺序,正在被添加也可以执行事件
// 在一般的context中都是在乎顺序的,需要在context完全添加完成才可以执行事件
if (invokeHandler()) {
try {
// 执行对应的事件
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
} else {
// 否则往下传播
fireChannelRead(msg);
}
}
这里invokeHandler方法的逻辑,感兴趣的读者可以自行研究一下,这里限于篇幅不进行介绍,并不是本节的重点内容那么
从这里可以看到,在传播事件的过程中,只不过是找到了关心事件的第一个Context,并取出其Handler调用对应的方法,总结如下图所示
从Pipeline传播

从Context传播

至于是否继续往下传播,取决于Context中是否又调用了fire事件传播方法。而在pipeline传播时会传播两次的原因就是假设为read事件,在headContext的处理如下
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.fireChannelRead(msg);
}
context方式继续向下传播
头节点Conetxt
这里先介绍一下头节点的类结构
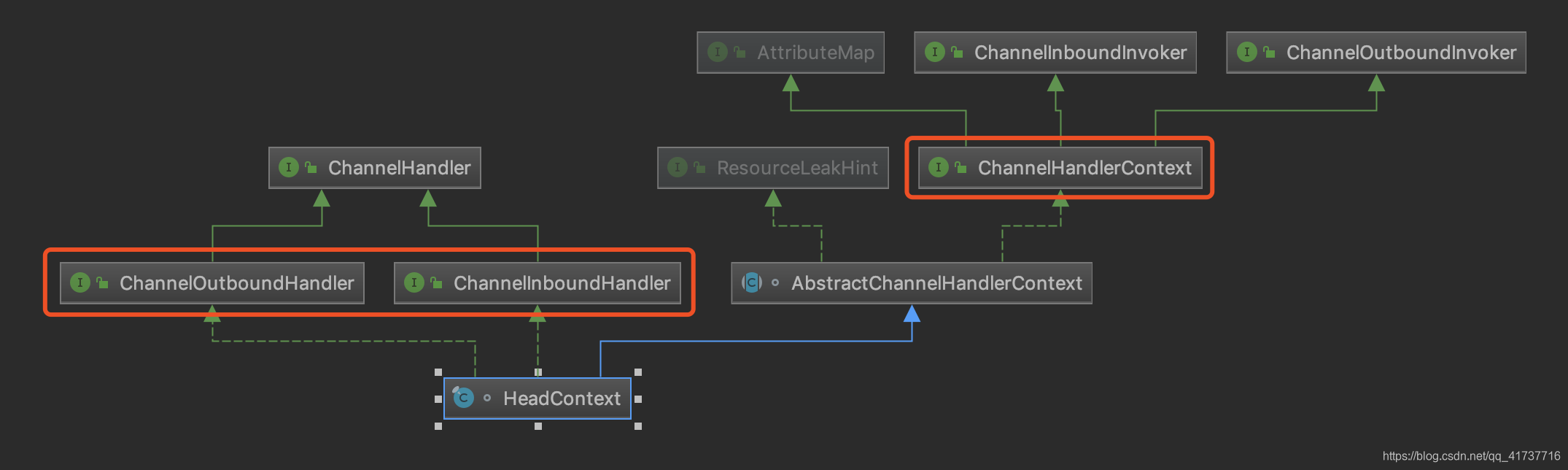
可以看到,它既是一个Handler,又是一个Conetxt,直接充当了两个角色,同时它又是InBound、OutBound两个类型兼顾的Handler(对于InBound、OutBound在下面介绍其用处)
接下来看看它有什么功能
绑定channel
在服务端启动时Channel初始化且注册之后,需要绑定到端口,接着就会调用pipeline的bind方法,其会从tail往上传播事件,找到OutBound类型的Handler执行bind方法,而HeadConetxt正好是一个OutBound,则会执行它的bind方法
public void bind(
ChannelHandlerContext ctx, SocketAddress localAddress, ChannelPromise promise) {
unsafe.bind(localAddress, promise);
}
protected void doBind(SocketAddress localAddress) throws Exception {
if (PlatformDependent.javaVersion() >= 7) {
javaChannel().bind(localAddress, config.getBacklog());
} else {
javaChannel().socket().bind(localAddress, config.getBacklog());
}
}
可以看到,其具有将底层channel绑定到一个地址上的委托功能
激活时自动读
在channel激活的时候,默认其会自动读一下
public void channelActive(ChannelHandlerContext ctx) {
ctx.fireChannelActive();
// 自动读
readIfIsAutoRead();
}
而其会自动传播到head的read方法
public void read(ChannelHandlerContext ctx) {
unsafe.beginRead();
}
这个方法即在selector上修改自己感兴趣的事件,在服务端Channel中会修改成ACCEPT事件,表示自己关心新连接接入,在客户端Channel中会修改成READ事件,表示自己关心可读的事件。
写出数据
在写出数据这部分的底层实现也是由Head来完成的
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
unsafe.write(msg, promise);
}
@Override
public void flush(ChannelHandlerContext ctx) {
unsafe.flush();
}
在我们自定义的Handler中,若要写数据出去给客户端,可以调用context的write方法,其会最终流到HeadConetxt进行处理,也就是调用head的write方法,这个write方法并不是真正的在写出数据,而是将数据存放到一个成员变量中
private volatile ChannelOutboundBuffer outboundBuffer = new ChannelOutboundBuffer(AbstractChannel.this);
write(){
...
outboundBuffer.addMessage(msg, size, promise);
}
当flush事件被传播,最终也会由HeadContext来执行,其flush方法才是真正写出数据
public final void flush() {
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
return;
}
// 将write的数据添加到flush的数据结构中
outboundBuffer.addFlush();
// 对flush的数据结构中的数据进行写出
flush0();
}
其flush0方法最终调用doWrite(outboundBuffer)方法,写出数据(这里进入NioSocketChannel的父类,AbstractNioByteChannel)
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
// 从配置中取出自旋写出的次数
int writeSpinCount = config().getWriteSpinCount();
do {
// current方法即为从flush数据结构从取出一个元素出来
// 也就是取出一个待写的ByteBuf出来
Object msg = in.current();
if (msg == null) {
// Wrote all messages.
// 若为空,代表已经将待写的数据都写完了
// 清空WRITE事件标志位
clearOpWrite();
// Directly return here so incompleteWrite(...) is not called.
return;
}
// 每写一次,自旋次数-1
writeSpinCount -= doWriteInternal(in, msg);
} while (writeSpinCount > 0);
// 若writeSpinCount被消耗完还能走到这里,证明flush数据结构还有数据没有写出
// 将设置WRITE事件标志位,表示channel有写事件,在EventLoop轮询到的时候
// 会执行flush,将没写完的数据写出去
incompleteWrite(writeSpinCount < 0);
}
首先这里简单看一下写出数据的过程,进入doWriteInternal方法中的doWriteBytes方法
protected int doWriteBytes(ByteBuf buf) throws Exception {
final int expectedWrittenBytes = buf.readableBytes();
return buf.readBytes(javaChannel(), expectedWrittenBytes);
}
将ByteBuf数据写到底层channel中
最后,判断是否所有数据都写出去了
protected final void incompleteWrite(boolean setOpWrite) {
// Did not write completely.
if (setOpWrite) {
setOpWrite();
}
...
}
若setOpWrite为true,则设置一个WRITE事件的标志位
public static final int OP_WRITE = 1 << 2;
protected final void setOpWrite() {
final SelectionKey key = selectionKey();
// Check first if the key is still valid as it may be canceled as part of the deregistration
// from the EventLoop
// See https://github.com/netty/netty/issues/2104
if (!key.isValid()) {
return;
}
final int interestOps = key.interestOps();
// 读事件是二进制第三位为1,则如果与的结果不为0,代表之前就有读事件注册了
// 所以这里只会对之前没有注册读事件的channel进行注册
if ((interestOps & SelectionKey.OP_WRITE) == 0) {
// 将interstOps的二进制第三位设置为1,代表此时关心读事件
key.interestOps(interestOps | SelectionKey.OP_WRITE);
}
}
在我们分析 Reactor线程模型 的时候知道,线程会反复执行3个流程,其中第二个流程为处理事件,我们回顾一下处理事件都做了什么
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
...
try {
int readyOps = k.readyOps();
// Process OP_WRITE first as we may be able to write some queued buffers and so free memory.
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
// Call forceFlush which will also take care of clear the OP_WRITE once there is nothing left to write
ch.unsafe().forceFlush();
}
...
}
略过了无关事件,这里可以看到,在处理事件的时候,会被selector选择出来,并在上述方法中执行,有OP_WRITE事件位的时候会执行flush方法
public final void forceFlush() {
// directly call super.flush0() to force a flush now
super.flush0();
}
就是执行上述的flush0方法而已。那么在全写出数据之后,就会将该事件标志位清除了
protected final void clearOpWrite() {
final SelectionKey key = selectionKey();
// Check first if the key is still valid as it may be canceled as part of the deregistration
// from the EventLoop
// See https://github.com/netty/netty/issues/2104
if (!key.isValid()) {
return;
}
final int interestOps = key.interestOps();
// 之前有OP_WRITE标志位
if ((interestOps & SelectionKey.OP_WRITE) != 0) {
// 与上二进制第三位为1取反的值,表示将原二进制第三位变成0
key.interestOps(interestOps & ~SelectionKey.OP_WRITE);
}
}
这里~为取反操作,大致意思就是清除在二进制第三位的数,变为0
从上面可以知道,在我们真正要写出数据的时候要调用writeAndFlush方法,不然就会在缓冲区等待发送,在我们要发送多个数据包的时候,例如发送一个HTTP响应出去,将会构建多个Response的部分,一个个写出去,这时候可以调用write方法,然后在最后一个Response包发送的时候调用writeAndFlush方法将数据真正写出去
尾节点Context
照例先看一下尾节点的类结构

同样的,它也是Conetxt和Handler双角色,但和head不同的是,它仅仅是一个InBound的Handler,意味着它并不负责写数据出去
兜底操作
这里先剧透一下,读事件的传播是从head到tail从上往下传播的,中间会经过我们自定义的Handler,但并不是会一直往下传播直到底部,只有传播到某个Handler中,此Handler又调用了一次例如fireChannelRead方法,才会继续传播下去,而如果Handler调用方法继续往下传播,是被看作自己不处理该消息,给下一个Handler处理,如果自己能处理,则处理掉,操作已经结束,就不要往下传播了,若是编解码器,则还会传播一下给后面的业务逻辑Handler,业务逻辑Handler处理结束,则不往下传播,若没处理结束或是无法处理该消息,则往下传播,若read事件传播到tail(由于是从上往下传播的),说明没有Handler能处理该事件,又或是没有处理完,此时tailContext就会进行一个兜底的操作
public void channelRead(ChannelHandlerContext ctx, Object msg) {
onUnhandledInboundMessage(msg);
}
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug(
"Discarded inbound message {} that reached at the tail of the pipeline. " +
"Please check your pipeline configuration.", msg);
} finally {
ReferenceCountUtil.release(msg);
}
}
其会打出一个日志,说明消息到达了底部,没有被处理,检查pipeline的Handler配置,并在最后释放了msg资源,属于一个预防的兜底操作。其实tailConetxt更多都是在做一些收尾的操作而已
