实验数据
数据来自出版书籍《An Introduction to Statistical Learning with Applications in R》(Springer, 2013),作者Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani。共200条数据,每条数据4个属性。该数据可以从这个链接直接下载得到:http://www-bcf.usc.edu/~gareth/ISL/Advertising.csv
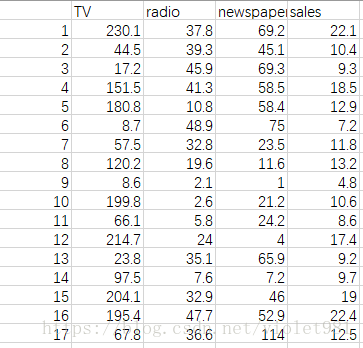
下载的数据是一个名为Advertising.csv的文件,一共200行4列 。这个是商品的销售量与电视广告、广播广告、报纸广告之间的关系,具体的单位可以先不管。每一行是一个商品,前三列是输入特征,后三列是输出特征。数据的样子如下:
python绘图
使用到了pandas和 matplotlib.pyplot这两个库,没安装的可以用pip安装或者直接安装一个Anaconda。需要吐槽一下我之前好蠢==一直以为是panda,所以很奇怪为什么import panda的时候没有这个库。
首先需要写好Advertising.csv的路径,python里面写路径可以在路径前加一个r,表示不需要转义字符了,比如说:
path = r'C:\Users\***\learning\data\Advertising.csv'然后使用pandas里面的函数read_csv()来读取这个Advertising.csv文件。
定义好绘图的横纵坐标,由于有三个输入特征,因此会分别绘制出三个输入特征与输出特征之间的关系。横坐标使用了list来存储三个输入特征,但是在实际绘制图形的时候,会分别绘制每个输入特征与输出特征的关系。
x = data[["TV","radio","newspaper"]]
print(type(x))
#<class 'pandas.core.frame.DataFrame'>
print(x.shape)
#(200, 3)这里由于会绘制出三幅图,因此在一张画布上,相当有三个子图构成一张图片,使用了subplot()这个函数,括号内的数字有讲究。此例中,三幅图片将会从上到下的摆放,因此是三行一列。指定某个图片的位置是按照从左到右,从上往下的编号。因此此例中的第一幅(即最上面的图片),是subplot(311)。第二幅是subplot(312)...如果是二行二列,左上角是subplot(221),右下角是subplot(224)。
再是指定绘制图片的横纵坐标和曲线模式。曲线模式有r(red),g(green),b(blue)三种颜色选,同时还有点的形状选,比如o的话是点点,^代笔三角形,*代表星型。
最后可以给图片加上名字,使用的函数是title()。最终分配布局grid()即可。别忘了要show()一下哦:)
画出来就是这样的:

代码部分
import pandas as pd
import matplotlib.pyplot as plt
if __name__ == "__main__":
path = r'C:\Users\**\learning\data\Advertising.csv'
data = pd.read_csv(path)
x = data[["TV","radio","newspaper"]]
y = data["sales"]
print(type(x))
#<class 'pandas.core.frame.DataFrame'>
print(x.shape)
#(200, 3)
plt.figure(figsize=(9,12))
plt.subplot(311)
plt.plot(data['TV'], y, 'ro')
plt.title('TV')
plt.grid()
plt.subplot(312)
plt.plot(data['radio'], y, 'g^')
plt.title('radio')
plt.grid()
plt.subplot(313)
plt.plot(data['newspaper'], y, 'b*')
plt.title('newspaper')
plt.grid()
plt.tight_layout()
plt.show()