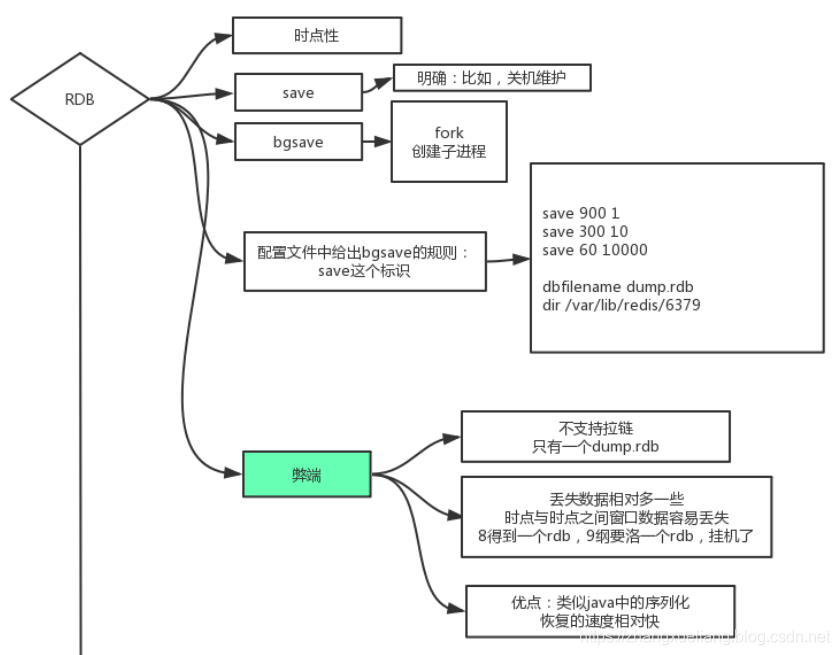
RDB
rdb持久化原理:
会涉及到操作系统底层的fork调用,详情查看:https://zhangxueliang.blog.csdn.net/article/details/104076571
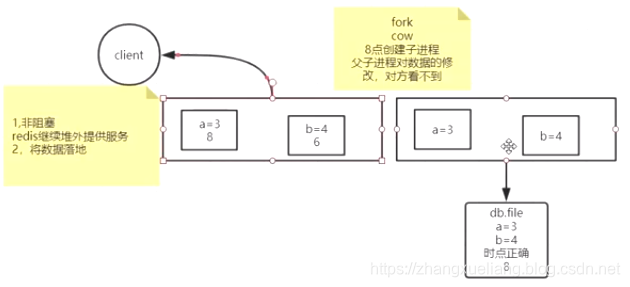
会fork出一个子进程用于持久化。
当redis主进程发生数据修改的时候,会触发内核级别的写时复制操作,写数据到持久化文件是子进程来完成的,数据的增删改是在父进程中进行的,所以redis的持久化是fork+copy on write来实现的。
比如8点fork出一个子进程用于持久化操作,此时子进程拷贝的是8点时的数据,父子进程的数据修改,彼此都不可见。假如10点redis数据发生了修改,此时会由内核的写时复制机制触发数据复制操作,将引用指向新的数据,此时子进程的引用还是指向旧数据。写时复制不是为了数据同步,而是数据隔离。
fork出来的子进程会一直等到数据持久化做完后才销毁。每次持久化开始时都会fork出一个子进程。每次拍快照(持久化)都是当前时间点的全量数据覆盖之前的快照数据,如果快照采用增量更新的方式的话,需要在内存中判断哪些数据有更新哪些没更新,反而消耗CPU资源。
拷贝引用的成本比拷贝数据的成本低很多,因为一个引用的大小是4个字节,但引用指向的数据可能是一个数组几百个字节。
redis RDB持久化配置方式:
如果想关闭持久化,只需在配置文件redis.conf中配置:
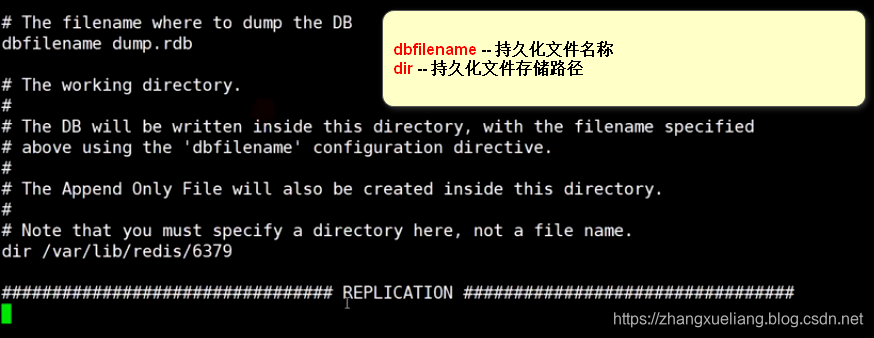
save ""redis.conf配置文件中配置持久化文件相关信息:
RDB的弊端:
①不支持拉链。由于只有一个dump.rdb持久化文件,所以会丢失前些天的数据,需要手工将dump文件拷贝出来。比如:我需要某一天的dump文件,如果不手工干涉的话,也许已经被覆盖了。
②丢失数据相对多一些。时点与时点之间的窗口数据容易丢失,比如8点得到一个dump.rdb,8:15要落一个rdb,结果挂机了。
RDB的优势:
类似于Java中的序列化,恢复数据的速度较快。想象一下,传输一个json数据然后解析成对象load到内存快还是直接传输一个二进制字节数组直接就怼到了内存快?用大腿想都知道是后者啦!
正是由于RDB的弊端,才有了AOF:Append Only File 的持久化机制。

AOF
将redis的写操作记录到文件中。类似于MySQL中的redo log和binlog一样。这样的话,丢失数据就会少啦。
在redis中,RDB和AOF可以同时开启,但是AOF优先,只会使用AOF做重启后的数据恢复。
aof执行日志文件中的命令,速度相对rdb要慢。但丢失数据相对rdb少。
aof天然的弊端:
①日志体量无限变大;
②恢复慢。
优点如果能保住,日志还是可以用的,需要设计一个方案让日志,AOF足够小。
4.0以前通过日志重写来实现:
①删除抵销的命令
②合并重复的命令
4.0以后也是通过日志重写来实现,只不过进行了优化:
①将老的数据RDB到aof文件中,存储的是二进制格式的日志数据。
②将增量的以redis指令的方式append到aof日志文件中。
AOF是一个混合体,利用了RDB的快和日志的全量。
redis 4.0 以后,AOF中包含RDB全量快照数据,增加记录新的写操作。
开启AOF
IO流中为什么要flush一下才能将数据写到磁盘,因为磁盘IO操作都是由操作系统内核来进行的,数据先是下入到内存的buffer中,flush就是将数据从buffer中刷到硬盘。redis中也是如此:
always:每次发生数据变更,立即持久化到硬盘
ererysec:每秒持久化一次,也就是每秒调一次flush将buffer数据刷到硬盘
no:等待OS自己将数据刷到硬盘,buffer一满OS就会刷到硬盘。
效率对比:always < everysec < no
no-appendfsync-on-rewrite默认是no:可能会发生丢数据的情况。但不会与自己的子进程争抢IO操作权。