1、 系统内置函数
(1)查看系统自带的函数
hive (default)> show functions;
OK
tab_name
!
!=
%
&
*
+
-
/
<
<=
<=>
<>
=
==
>
>=
^
abs
acos
add_months
and
array
array_contains
ascii
asin
assert_true
atan
avg
base64
between
bin
case
cbrt
ceil
ceiling
coalesce
collect_list
collect_set
compute_stats
concat
concat_ws
context_ngrams
conv
corr
cos
count
covar_pop
covar_samp
create_union
cume_dist
current_database
current_date
current_timestamp
current_user
date_add
date_format
date_sub
datediff
day
dayofmonth
decode
degrees
dense_rank
div
e
elt
encode
ewah_bitmap
ewah_bitmap_and
ewah_bitmap_empty
ewah_bitmap_or
exp
explode
factorial
field
find_in_set
first_value
floor
format_number
from_unixtime
from_utc_timestamp
get_json_object
greatest
hash
hex
histogram_numeric
hour
if
in
in_file
index
initcap
inline
instr
isnotnull
isnull
java_method
json_tuple
lag
last_day
last_value
lcase
lead
least
length
levenshtein
like
ln
locate
log
log10
log2
lower
lpad
ltrim
map
map_keys
map_values
matchpath
max
min
minute
month
months_between
named_struct
negative
next_day
ngrams
noop
noopstreaming
noopwithmap
noopwithmapstreaming
not
ntile
nvl
or
parse_url
parse_url_tuple
percent_rank
percentile
percentile_approx
pi
pmod
posexplode
positive
pow
power
printf
radians
rand
rank
reflect
reflect2
regexp
regexp_extract
regexp_replace
repeat
reverse
rlike
round
row_number
rpad
rtrim
second
sentences
shiftleft
shiftright
shiftrightunsigned
sign
sin
size
sort_array
soundex
space
split
sqrt
stack
std
stddev
stddev_pop
stddev_samp
str_to_map
struct
substr
substring
sum
tan
to_date
to_unix_timestamp
to_utc_timestamp
translate
trim
trunc
ucase
unbase64
unhex
unix_timestamp
upper
var_pop
var_samp
variance
weekofyear
when
windowingtablefunction
xpath
xpath_boolean
xpath_double
xpath_float
xpath_int
xpath_long
xpath_number
xpath_short
xpath_string
year
|
~
Time taken: 1.102 seconds, Fetched: 216 row(s)
hive (default)>
(2)显示自带的函数的用法
hive (default)> desc function upper;
OK
tab_name
upper(str) - Returns str with all characters changed to uppercase
Time taken: 0.046 seconds, Fetched: 1 row(s)
hive (default)>
(3)详细显示自带的函数的用法
hive (default)> desc function extended upper;
OK
tab_name
upper(str) - Returns str with all characters changed to uppercase
Synonyms: ucase
Example:
> SELECT upper('Facebook') FROM src LIMIT 1;
'FACEBOOK'
Time taken: 0.044 seconds, Fetched: 5 row(s)
hive (default)>
2、自定义函数
1)Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2)当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出
如lateral view explore()
4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
5)编程步骤:
(1)继承org.apache.hadoop.hive.ql.UDF
(2)需要实现evaluate函数;evaluate函数支持重载;
(3)在hive的命令行窗口创建函数
a)添加jar
add jar linux_jar_path
b)创建function,
create [temporary] function [dbname.]function_name AS class_name;
(4)在hive的命令行窗口删除函数
Drop [temporary] function [if exists] [dbname.]function_name;
6)注意事项
(1)UDF必须要有返回类型,可以返回null,但是返回类型不能为void;
3、自定义UDF函数
(1)创建一个Maven工程Hive

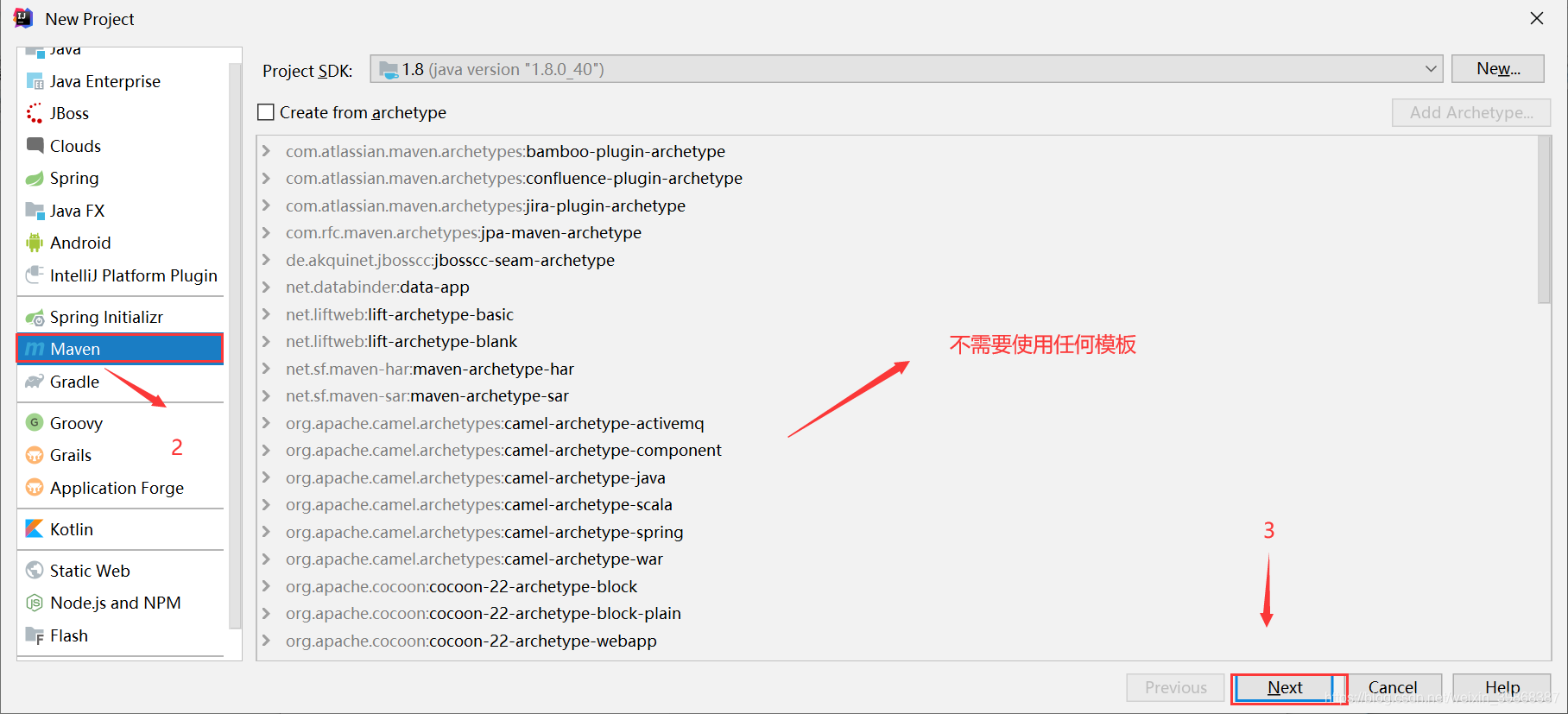
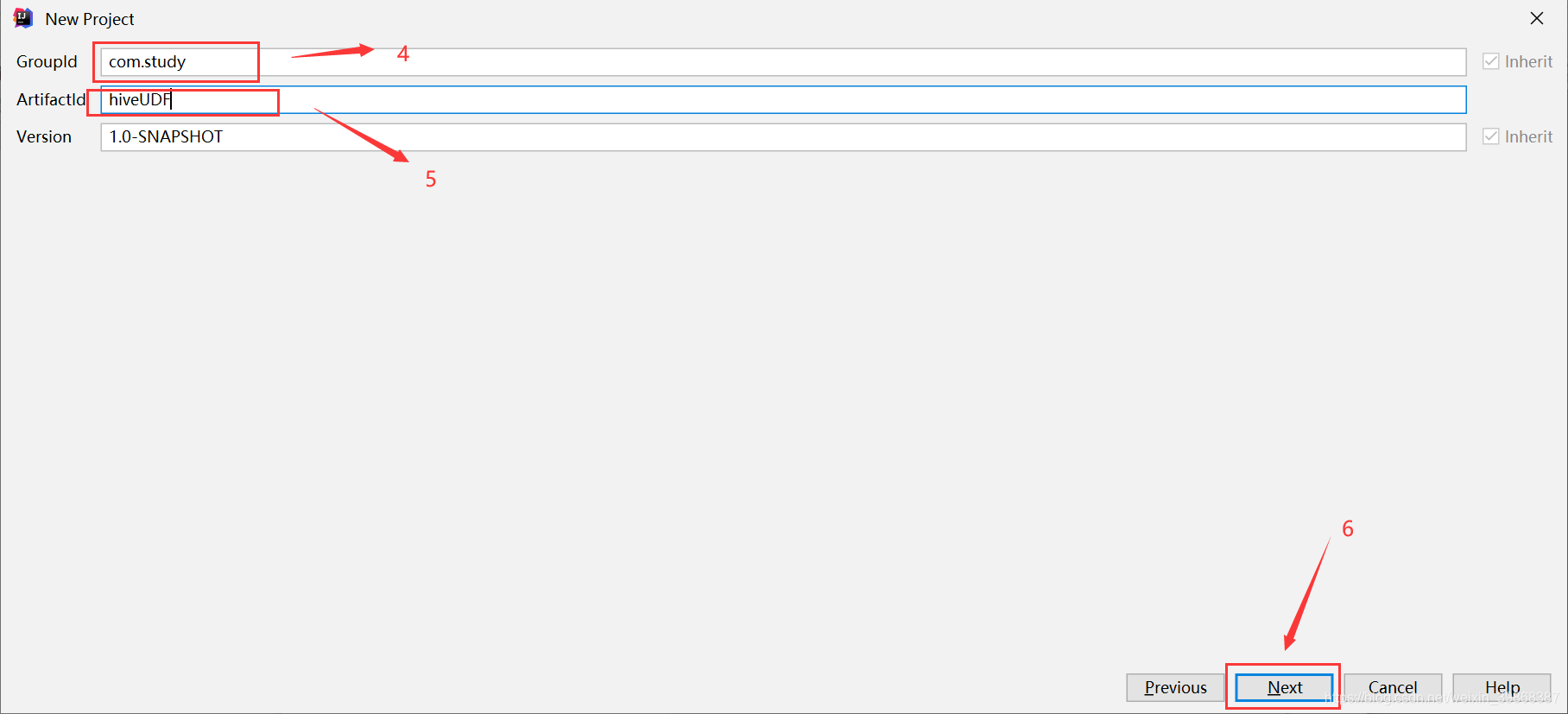
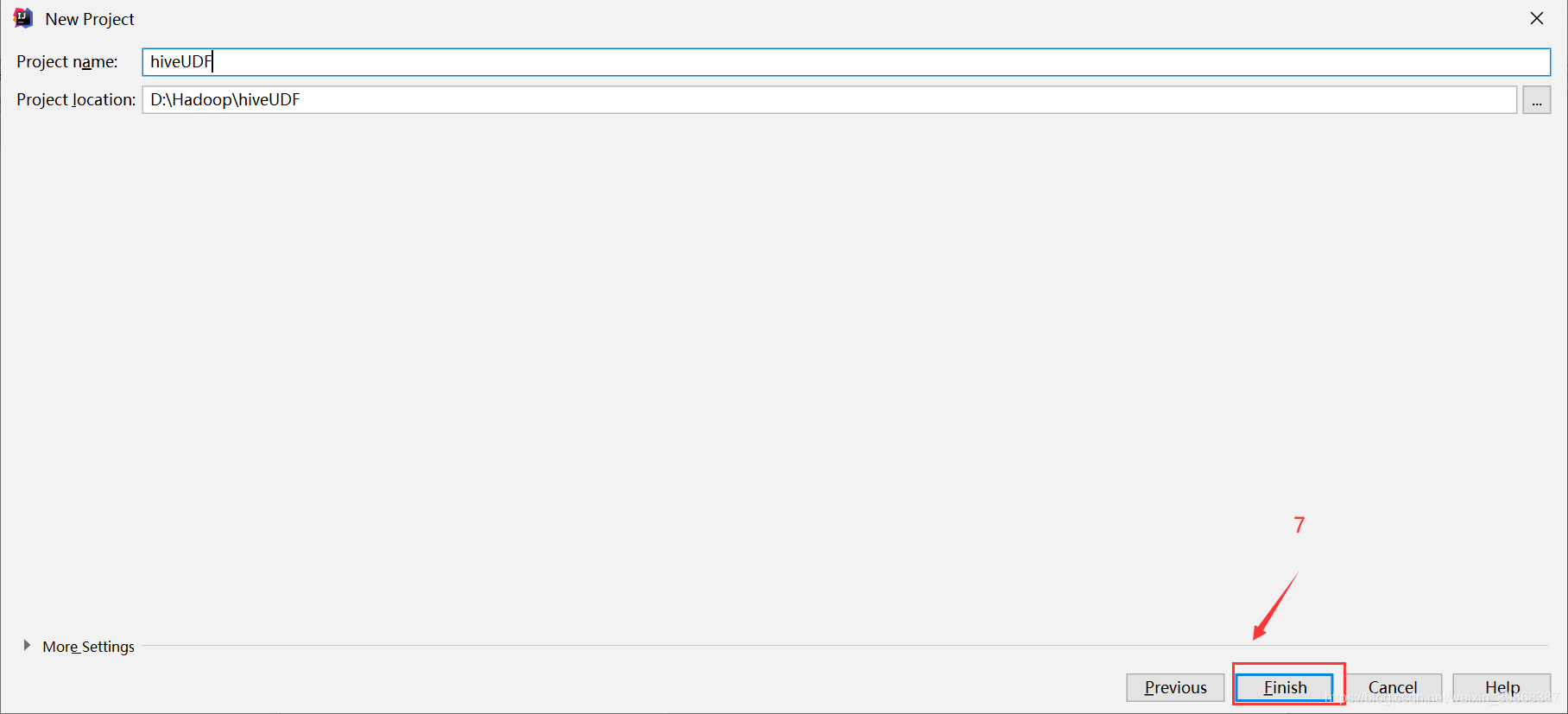
(2)导入依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
添加依赖,如图所示:

(3)创建一个类,在src/main/java目录下创建一个HiveUdf类
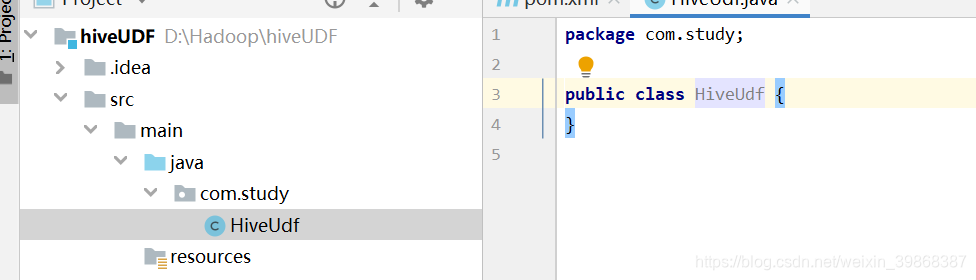
编写HiveUdf代码:
HiveUdf.java
package com.study;
import org.apache.hadoop.hive.ql.exec.UDF;
public class HiveUdf extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}
接下来,对代码进行打包
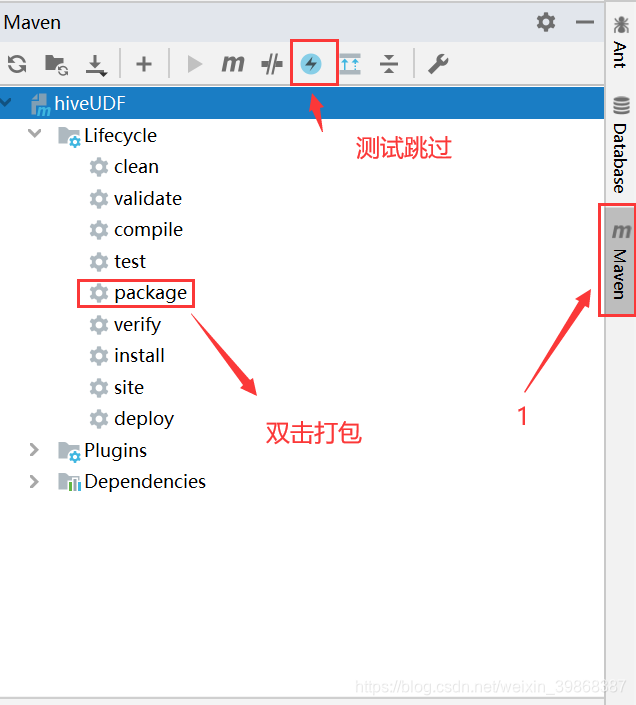
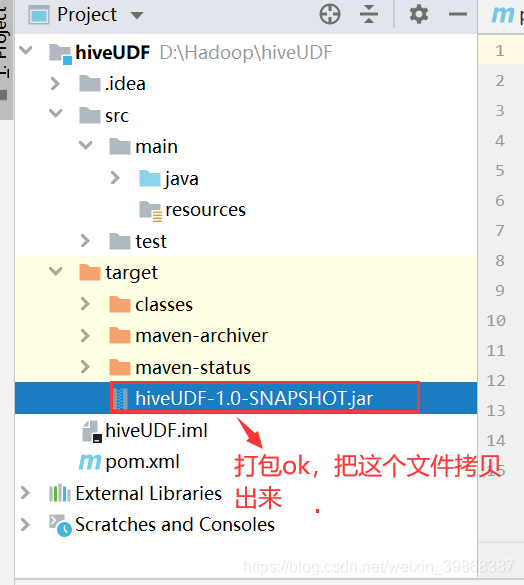
我们把打好的包上传Linux环境下,放在 /usr/local/hadoop/module/datas文件目录下:

当拷贝进来之后,需要做以下操作:
(1)添加jar
hive (default)> add jar /usr/local/hadoop/module/datas/hdf.jar;
Added [/usr/local/hadoop/module/datas/hdf.jar] to class path
Added resources: [/usr/local/hadoop/module/datas/hdf.jar]
hive (default)>
(2)创建函数
hive (default)> create temporary function myLower as "com.study.HiveUdf";
OK
Time taken: 0.103 seconds
hive (default)>
注意:“com.study.HiveUdf”:是主类全路径
(3)使用函数
hive (default)> select myLower(ename)from emp;
OK
_c0
smith
allen
ward
jones
martin
blake
clark
scott
king
turner
adams
james
ford
miller
Time taken: 1.462 seconds, Fetched: 14 row(s)
hive (default)>
将我们的姓名转化成小写
