Ristretto是一个自动化的CNN近似工具,可以压缩32位浮点网络。Ristretto是Caffe的扩展,允许以有限的数字精度测试、训练和微调网络。
Ristretto速览
- Ristretto Tool:Ristretto工具使用不同的比特宽度进行数字表示,执行自动网络量化和评分,以在压缩率和网络准确度之间找到一个很好的平衡点。
- Ristretto Layers:Ristretto重新实现Caffe层并模拟缩短字宽的算术。
- 测试和训练:由于将Ristretto平滑集成Caffe,可以改变网络描述文件来量化不同的层。不同层所使用的位宽以及其他参数可以在网络的prototxt文件中设置。这使得我们能够直接测试和训练压缩后的网络,而不需要重新编译。
逼近方案
Ristretto允许以三种不同的量化策略来逼近卷积神经网络:
- 动态固定点:修改的定点格式。
- Minifloat:缩短位宽的浮点数。
- 两个幂参数:当在硬件中实现时,具有两个幂参数的层不需要任何乘法器。
Ristretto: Layers, Benchmarking and Finetuning
这个改进的Caffe版本支持有限数值精度层。所讨论的层使用缩短的字宽来表示层参数和层激活(输入和输出)。由于Ristretto遵循Caffe的规则,已经熟悉Caffe的用户会很快理解Ristretto。下面解释了Ristretto的主要扩展:
Ristretto Layers
Ristretto引入了新的有限数值精度层类型。这些层可以通过传统的Caffe网络描述文件(* .prototxt)使用。
下面给出一个minifloat卷积层的例子:
layer {
name: "conv1"
type: "ConvolutionRistretto"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 96
kernel_size: 7
stride: 2
weight_filler {
type: "xavier"
}
}
quantization_param {
precision: MINIFLOAT
mant_bits: 10
exp_bits: 5
}
}该层将使用半精度(16位浮点)数字表示。卷积内核、偏差以及层激活都被修剪为这种格式。MANT:mantissa,尾数(有效数字)
注意与传统卷积层的三个不同之处:
type变成了ConvolutionRistretto- 增加了一个额外的层参数:
quantization_param - 该层参数包含用于量化的所有信息
Ristretto 在 src/caffe/ristretto/layers/ 中提供有限精度的层。
Blobs
Ristretto允许精确模拟资源有限的硬件加速器。为了与Caffe规则保持一致,Ristretto在层参数和输出中重用浮点Blob。这意味着有限精度数值实际上都存储在浮点数组中。
Scoring
对于量化网络的评分,Ristretto要求
- 训练好的32位FP网络参数
- 网络定义降低精度的层
第一项是Caffe传统训练的结果。Ristretto可以使用全精度参数来测试网络。这些参数默认情况下使用最接近的方案,即时转换为有限精度。
至于第二项——模型说明——您将不得不手动更改Caffe模型的网络描述,或使用Ristretto工具自动生成Google Protocol Buffer文件。
# score the dynamic fixed point SqueezeNet model on the validation set*
./build/tools/caffe test --model=models/SqueezeNet/RistrettoDemo/quantized.prototxt \
--weights=models/SqueezeNet/RistrettoDemo/squeezenet_finetuned.caffemodel \
--gpu=0 --iterations=2000在运行之前,请按照SqueezeNet示例进行操作。
Fine-tuning
为了提高精简网络的准确性,应该对其进行微调。在Ristretto中,Caffe命令行工具支持精简网络微调。与传统训练的唯一区别是网络描述文件应该包含Ristretto层。
微调需要以下项目:
- 32位FP网络参数
- 用于训练的Solver和超参数
网络参数是Caffe全精度训练的结果。
解算器(solver)包含有限精度网络描述文件的路径。这个网络描述和我们用来评分的网络描述是一样的。
# fine-tune dynamic fixed point SqueezeNet*
./build/tools/caffe train \
--solver=models/SqueezeNet/RistrettoDemo/solver_finetune.prototxt \
--weights=models/SqueezeNet/squeezenet_v1.0.caffemodel*在运行之前,请遵循SqueezeNet示例。
实施细节
在这个再训练过程中,网络学习如何用限定字参数对图像进行分类。由于网络权重只能具有离散值,所以主要挑战在于权重更新。我们采用以前的工作(Courbariaux等1)的思想,它使用全精度影子权重。对32位FP权重w应用小权重更新,从中进行采样得到离散权重w'。微调中的采样采用随机舍入方法进行,Gupta等2人成功地使用了这种方法,以16位固定点来训练网络。
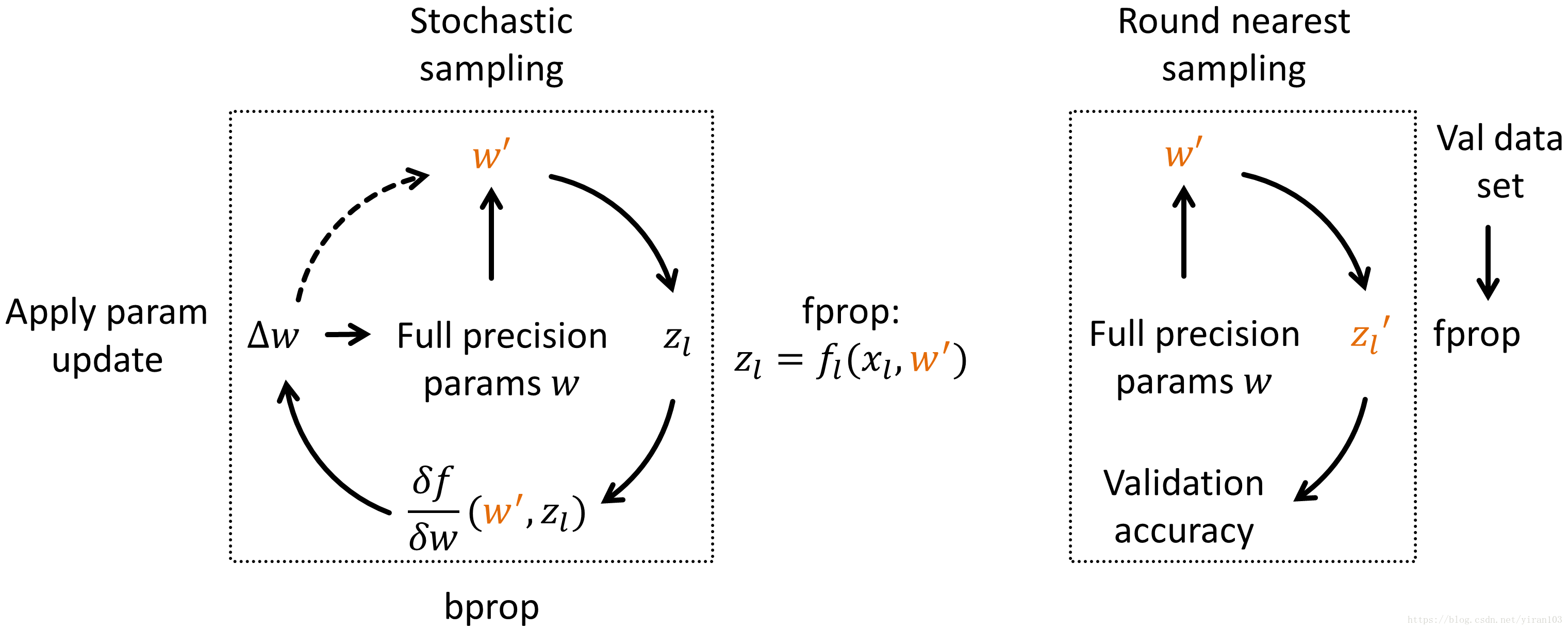
Ristretto:逼近策略
本节介绍了量化32位浮点网络的3种不同策略。
Dynamic Fixed Point
CNN的不同部分具有显着的动态范围。在大的层中,输出是数以千计的积累的结果,因此网络参数比层输出小得多。定点只具有有限的能力来覆盖宽动态范围。由Courbariaux等3人提出的动态固定点可以很好地解决这个问题。在动态的固定点上,每个数n表示如下:其中,每个数n表示如下: 。这里B提供位宽,s是符号位,f1是分数长度,x是尾数位。由于网络中的中间值具有不同的范围,所以希望将定点数值分组为具有常数f1的组中。所以分配给小数部分的比特数在该组内是恒定的,但与其他组相比是不同的。每个网络层分为三组:一个用于层输入,一个用于权重,一个用于层输出。这可以更好地覆盖层激活和权重的动态范围,因为权重通常特别小。
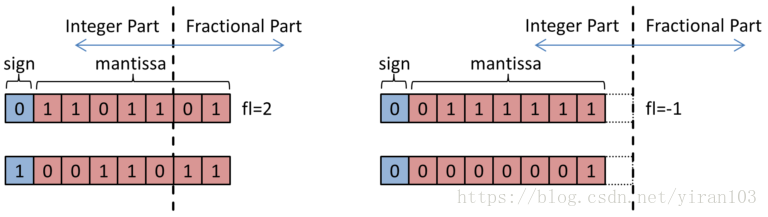
上图为4个属于两个不同组的动态定点数的例子。注意第二组的分数长度是负数。 所以第二组的分数长度是-1,整数长度是9,位宽是8。
Minifloat
由于神经网络的训练是以浮点的方式完成的,所以将这些模型压缩成比特宽度减少的浮点数是一种直观的方法。为了压缩网络并减少计算和存储需求,Ristretto可以用比IEEE-754标准少得多的位表示浮点数。我们在16bit、8bit甚至更小的数字上都遵循这个标准,但是我们的格式在一些细节上有所不同。也就是说,根据分配给指数的比特数降低指数偏差:
。这里exp_bits提供分配给指数的位数。与IEEE标准的另一个区别是我们不支持非规范化的数字,INF和NaN。INF由饱和数字代替,非规格化数字由0代替。最后,分配给指数和尾数部分的位数不遵循特定的规则。更确切地说,Ristretto选择指数位,以避免发生饱和。

Multiplier-free arithmetic
利用这种近似策略,乘法由位移代替。完全连接的层和卷积层由增加和乘法组成,其中乘法器需要更大的芯片面积。这促使以前的研究通过使用整数幂权重来消除所有的乘法器4。这些权重可以被认为是具有零尾数位的minifloat数值。权重和层激活之间的乘法变成了位移。幂的两个参数可以写成如下: 。这里exp是一个整数,对于网络参数通常是负的。由于接近于零的小参数对网络输出没有太大影响,所以可以忽略很小的指数。因此,可能的指数值可以显着减少。对于AlexNet,我们用 取得了很好的效果。在这种近似模式下,激活是动态定点格式。
Ristretto: Layer Catalogue
Ristretto支持逼近卷积神经网络的不同层类型。接下来的两个表格解释了如何量化不同的层,以及这种量化如何影响层的不同部分。
支持量化的层
| Layer Type | Dynamic Fixed Point | Minifloat | Integer-Power-of-Two Weights |
|---|---|---|---|
| Convolution | √ | √ | √ |
| Fully Connected | √ | √ | √ |
| LRN* | √ | ||
| Deconvolution | √ | √ | √ |
*支持GPU模式,不支持CPU模式
局部响应归一化(LRN)层仅支持量化到minifloat。该层类型使用“严格算术”,即所有中间结果都被量化。
量化参数和层输出
| Quantization | Parameters | Layer activations (in+out) |
|---|---|---|
| Dynamic fixed point | √ | √ |
| Minifloat | √ | √ |
| Integer-power-of-two parameters* | √ | √ |
*无乘法器算术:在这种模式下,网络权重量化为两个整数幂。层激活量化为动态的固定点。这模拟了硬件加速器,其中层之间的数据为8-bit 格式。我们模拟使用位移而不是乘法的卷积和全连接层。
Google Protocol Buffer Fields
就像使用Caffe一样,您需要使用协议缓冲区定义文件(* .prototxt)来定义Ristretto模型。所有Ristretto层参数都在caffe.proto中定义。
常见的字段
- type:Ristretto支持以下层:ConvolutionRistretto、FcRistretto(全连接层),LRNRistretto、DeconvolutionRistretto。
- 参数:
precision[defaultDYNAMIC_FIXED_POINT]:量化策略应该是DYNAMIC_FIXED_POINT,MINIFLOAT或INTEGER_POWER_OF_2_WEIGHTS*rounding_scheme[defaultNEAREST]:用于量化的舍入方案应该是最近偶数(NEAREST)或随机舍入(STOCHASTIC)
*在提交fc109ba之前:在早期的Ristretto版本中,精度为FIXED_POINT、MINI_FLOATING_POINT或POWER_2_WEIGHTS。
动态固定点
- 精度类型:
DYNAMIC_FIXED_POINT - 参数:
mant_bits[default:23]:用于表示尾数的位数exp_bits
Minifloat
- 精度类型:MINIFLOAT
- 参数:
- mant_bits[默认值:23]:用于表示尾数的位数
- exp_bits[default:8]:用于表示指数的位数
- 默认值对应于单精度格式
整数幂参数
- 精度类型:INTEGER_POWER_OF_2_WEIGHTS
- 参数:
- exp_min[默认值:-8]:使用的最小指数
- exp_max[默认值:-1]:使用的最大指数
- 对于默认值,网络参数可以用硬件中的4位表示(1个符号位,3位指数值)
Ristretto层示例
layer {
name: "norm1"
type: "LRNRistretto"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
quantization_param {
precision: MINIFLOAT
mant_bits: 10
exp_bits: 5
}
}Ristretto工具
Ristretto工具可以自动量化32位浮点网络,使用缩小字宽算法。ristretto命令行接口根据用户指定的最大精度下降量找到尽可能最小的位宽表示。而且,该工具生成量化网络的protocol buffer定义文件。
该工具被编译为./build/tools/ristretto。不带参数运行ristretto可输出帮助。
例子:
以下命令将LeNet量化为动态固定点:
./build/tools/ristretto quantize --model=examples/mnist/lenet_train_test.prototxt \
--weights=examples/mnist/lenet_iter_10000.caffemodel \
--model_quantized=examples/mnist/quantized.prototxt \
--iterations=100 --gpu=0 --trimming_mode=dynamic_fixed_point --error_margin=1给定1%的误差,LeNet可以量化为2-bit卷积核,4-bit全连接层参数和8-bit层输出:
I0626 17:37:14.029498 15899 quantization.cpp:260] Network accuracy analysis for
I0626 17:37:14.029506 15899 quantization.cpp:261] Convolutional (CONV) and fully
I0626 17:37:14.029515 15899 quantization.cpp:262] connected (FC) layers.
I0626 17:37:14.029521 15899 quantization.cpp:263] Baseline 32bit float: 0.9915
I0626 17:37:14.029531 15899 quantization.cpp:264] Dynamic fixed point CONV
I0626 17:37:14.029539 15899 quantization.cpp:265] weights:
I0626 17:37:14.029546 15899 quantization.cpp:267] 16bit: 0.9915
I0626 17:37:14.029556 15899 quantization.cpp:267] 8bit: 0.9915
I0626 17:37:14.029567 15899 quantization.cpp:267] 4bit: 0.9909
I0626 17:37:14.029577 15899 quantization.cpp:267] 2bit: 0.9853
I0626 17:37:14.029587 15899 quantization.cpp:267] 1bit: 0.1135
I0626 17:37:14.029598 15899 quantization.cpp:270] Dynamic fixed point FC
I0626 17:37:14.029605 15899 quantization.cpp:271] weights:
I0626 17:37:14.029613 15899 quantization.cpp:273] 16bit: 0.9915
I0626 17:37:14.029623 15899 quantization.cpp:273] 8bit: 0.9916
I0626 17:37:14.029644 15899 quantization.cpp:273] 4bit: 0.9914
I0626 17:37:14.029654 15899 quantization.cpp:273] 2bit: 0.9484
I0626 17:37:14.029664 15899 quantization.cpp:275] Dynamic fixed point layer
I0626 17:37:14.029670 15899 quantization.cpp:276] activations:
I0626 17:37:14.029677 15899 quantization.cpp:278] 16bit: 0.9904
I0626 17:37:14.029687 15899 quantization.cpp:278] 8bit: 0.9904
I0626 17:37:14.029700 15899 quantization.cpp:278] 4bit: 0.981
I0626 17:37:14.029708 15899 quantization.cpp:281] Dynamic fixed point net:
I0626 17:37:14.029716 15899 quantization.cpp:282] 2bit CONV weights,
I0626 17:37:14.029722 15899 quantization.cpp:283] 4bit FC weights,
I0626 17:37:14.029731 15899 quantization.cpp:284] 8bit layer activations:
I0626 17:37:14.029737 15899 quantization.cpp:285] Accuracy: 0.9826
I0626 17:37:14.029744 15899 quantization.cpp:286] Please fine-tune.参数
model:32位浮点网络的网络定义。weights:32位浮点网络的训练网络参数。trimming_mode:量化策略可以是dynamic_fixed_point、minifloat或integer_power_of_2_weights。*model_quantized:由此产生的量化的网络定义。error_margin:与32位浮点数网络相比绝对精度下降百分比。GPU:GPU ID,Ristretto支持CPU和GPU模式。iterations:用于评分网络的批次迭代次数。
*在早期版本的Ristretto(在提交fc109ba之前),trimming_mode曾经是fixed_point、mini_floating_point、power_of_2_weights。
trimming_mode
- 动态固定点:首先Ristretto分析层参数和输出。该工具选择在整数部分使用足够的位来避免最大值溢出。 Ristretto对如下层搜索可能的最低位宽
- 卷积层参数
- 全连接层参数
- 卷积层和完全连接层的激活输出
- Minifloat:首先Ristretto分析层激活。该工具选择使用足够的指数位来避免最大值溢出。Ristretto对如下层搜索可能的最低位宽
- 卷积和全连接层的参数和激活
- 整数幂参数:Ristretto以4-bit参数网络为基准,分别选择-8和-1作为最低和最高指数。激活是在8位动态固定点。
Ristretto: SqueezeNet Example
构造一个8位动态定点SqueezeNet网络
Iandola等人的SqueezeNet5具有AlexNet6的准确性,但是网络参数减少了50倍以上。本指南介绍了如何量化SqueezeNet到动态的固定点,微调压缩后的网络,最后在ImageNet验证数据集上对网络进行基准测试。
为了重现以下结果,您首先需要执行以下步骤:
- 从这里下载SqueeNet V1.0参数,并将它们放入models/SqueezeNet/文件夹中。这些是由DeepScale提供的预训练好的32位FP权重。
- 我们已经为您fine-tuned了一个8位动态定点SqueezeNet。从models/SqueezeNet/RistrettoDemo/ristrettomodel-url提供的链接下载它,并将其放入该文件夹。
- 对SqueezeNet prototxt(models/SqueezeNet/train_val.prototxt)做两个修改:您需要调整两个source字段为本地ImageNet数据的路径。
量化到动态定点
本指南假设您已安装了Ristretto(make all),并且在Caffe的根路径下运行所有命令。
在第一步中,我们将32位浮点网络压缩为动态的固定点。SqueezeNet在32位和16位动态定点上表现良好,但是我们可以进一步缩小位宽。参数压缩和网络准确性之间有一个折衷。Ristretto工具可以自动为网络的每个部分找到合适的位宽:
./examples/ristretto/00_quantize_squeezenet.sh这个脚本将量化SqueezeNet模型。你会看到飞现的信息,Ristretto以不同字宽测试量化模型。最后的总结将如下所示:
I0626 16:56:25.035650 14319 quantization.cpp:260] Network accuracy analysis for
I0626 16:56:25.035667 14319 quantization.cpp:261] Convolutional (CONV) and fully
I0626 16:56:25.035681 14319 quantization.cpp:262] connected (FC) layers.
I0626 16:56:25.035693 14319 quantization.cpp:263] Baseline 32bit float: 0.5768
I0626 16:56:25.035715 14319 quantization.cpp:264] Dynamic fixed point CONV
I0626 16:56:25.035728 14319 quantization.cpp:265] weights:
I0626 16:56:25.035740 14319 quantization.cpp:267] 16bit: 0.557159
I0626 16:56:25.035761 14319 quantization.cpp:267] 8bit: 0.555959
I0626 16:56:25.035781 14319 quantization.cpp:267] 4bit: 0.00568
I0626 16:56:25.035802 14319 quantization.cpp:270] Dynamic fixed point FC
I0626 16:56:25.035815 14319 quantization.cpp:271] weights:
I0626 16:56:25.035828 14319 quantization.cpp:273] 16bit: 0.5768
I0626 16:56:25.035848 14319 quantization.cpp:273] 8bit: 0.5768
I0626 16:56:25.035868 14319 quantization.cpp:273] 4bit: 0.5768
I0626 16:56:25.035888 14319 quantization.cpp:273] 2bit: 0.5768
I0626 16:56:25.035909 14319 quantization.cpp:273] 1bit: 0.5768
I0626 16:56:25.035938 14319 quantization.cpp:275] Dynamic fixed point layer
I0626 16:56:25.035959 14319 quantization.cpp:276] activations:
I0626 16:56:25.035979 14319 quantization.cpp:278] 16bit: 0.57578
I0626 16:56:25.036012 14319 quantization.cpp:278] 8bit: 0.57058
I0626 16:56:25.036051 14319 quantization.cpp:278] 4bit: 0.0405805
I0626 16:56:25.036073 14319 quantization.cpp:281] Dynamic fixed point net:
I0626 16:56:25.036087 14319 quantization.cpp:282] 8bit CONV weights,
I0626 16:56:25.036100 14319 quantization.cpp:283] 1bit FC weights,
I0626 16:56:25.036113 14319 quantization.cpp:284] 8bit layer activations:
I0626 16:56:25.036126 14319 quantization.cpp:285] Accuracy: 0.5516
I0626 16:56:25.036141 14319 quantization.cpp:286] Please fine-tune.分析表明,卷积层的激活和参数都可以降低到8位,top-1精度下降小于3%。由于SqueezeNet不包含全连接层,因此可以忽略该层类型的量化结果。最后,该工具同时量化所有考虑的网络部分。结果表明,8位SqueezeNet具有55.16%的top-1精度(与57.68%的基准相比)。为了改善这些结果,我们将在下一步中对网络进行微调。
微调动态固定点参数
上一步将32位浮点SqueezeNet量化为8位固定点,并生成相应的网络描述文件(models/SqueezeNet/RistrettoDemo/quantized.prototxt)。现在我们可以微调浓缩的网络,尽可能多地恢复原始的准确度。
在微调期间,Ristretto会保持一组高精度的重量。对于每个训练batch,这些32位浮点权重随机四舍五入为8位固定点。然后将8位参数用于前向和后向传播,最后将权重更新应用于高精度权重。
微调程序可以用传统的caffe工具来完成。只需启动以下脚本:
./examples/ristretto/01_finetune_squeezenet.sh经过1200次微调迭代(Tesla K-40 GPU〜5小时), batch大小为32 * 32,压缩后的SqueezeNet将具有57%左右的top-1验证精度。微调参数位于models/SqueezeNet/RistrettoDemo/squeezenet_iter_1200.caffemodel。总而言之,您成功地将SqueezeNet缩减为8位动态定点,精度损失低于1%。
请注意,通过改进数字格式(即对网络的不同部分选择整数和分数长度),可以获得稍好的最终结果。
SqueezeNet动态固定点基准
在这一步中,您将对现有的动态定点SqueezeNet进行基准测试,我们将为您进行微调。即使跳过上一个微调步骤,也可以进行评分。该模型可以用传统的caffe-tool进行基准测试。所有的工具需求都是一个网络描述文件以及网络参数。
./examples/ristretto/02_benchmark_fixedpoint_squeezenet.sh你应该得到56.95%的top-1精度。
- Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in Neural Information Processing Systems, 2015. ↩
- Suyog Gupta, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan. Deep learning with limited numerical precision. arXiv preprint, 2015. ↩
- Tang, Chuan Zhang, and Hon Keung Kwan. Multilayer feedforward neural networks with single powers-of-two weights. IEEE Transactions on Signal Processing 41.8 (1993). ↩
- Tang, Chuan Zhang, and Hon Keung Kwan. Multilayer feedforward neural networks with single powers-of-two weights. IEEE Transactions on Signal Processing 41.8 (1993). ↩
- Iandola, Forrest N., et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 1MB model size. arXiv preprint (2016). ↩
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems. 2012. ↩