目录
扫描二维码关注公众号,回复:
8801167 查看本文章

CURD
创建文档
<1>两种方式
- Index文档
PUT my_index/_doc/1
如果id不存在,创建新的文档,否则,删除现有文档,在创建新的文档,版本数增加- Create文档
PUT my_index/_create/1
POST my_index/_doc/1
如果id已经存在,会失败<2>支持自动生成文档id和指定文档id两种方式
<3>通过调用 "POST my_index/_doc",系统自动生成document id
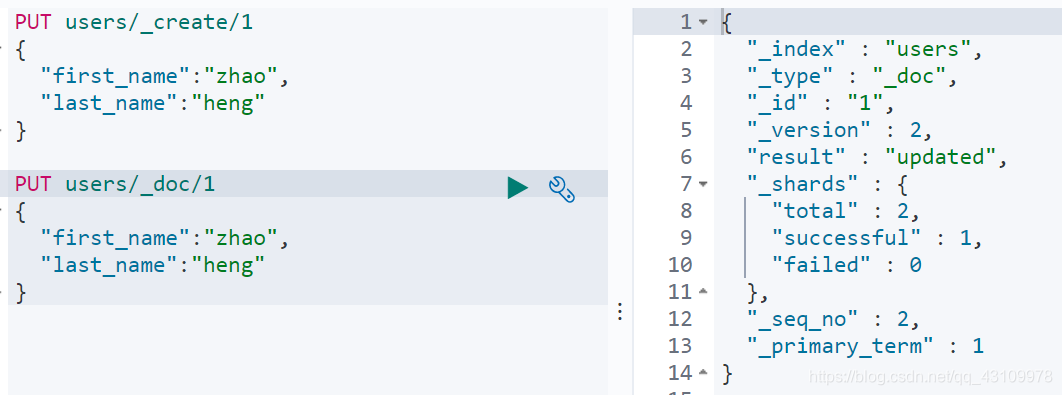
获取文档(GET)
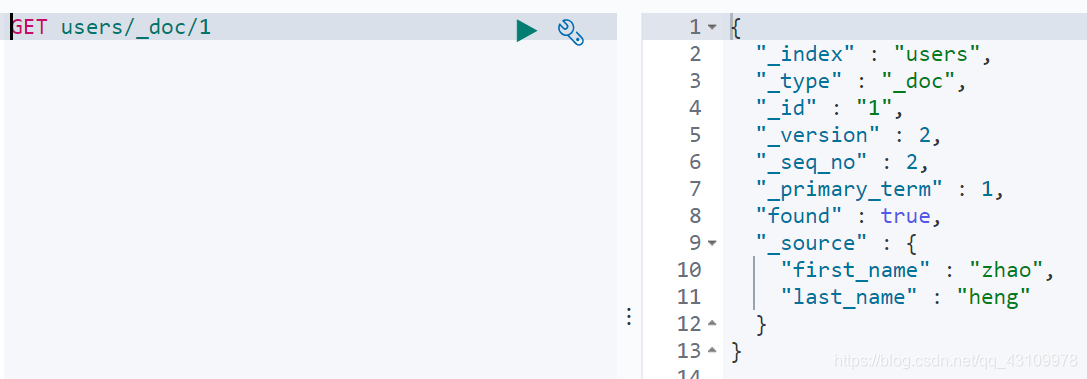
<1>找到文档,返回http 200
<2>文档元信息
- _index/ _type/
- 版本信息,同一个id的文档,即使被删除,version号也会增加。version表示文档改动过的次数
- _source中默认包含了文档的所有原始信息
<3>找不到文档,放回http 404

更新文档
- update不会删除原来的文档,而是实现真正的数据更新
- Post 方法需要包含在_doc中

删除文档

Bulk API
<1>支持在一次api调用中,对不同的索引进行操作
<2>支持四种类型操作
index,create,update,delete
<3>每行需要指定index信息,可以在URI中指定Index,也可以在请求的Payload中进行
<4>操作中单挑失败,不会影响其他操作
<5>返回结果包括了每一条操作执行的结果

批量读取 mget
批量操作,减少网络连接所产生的开销,提高性能
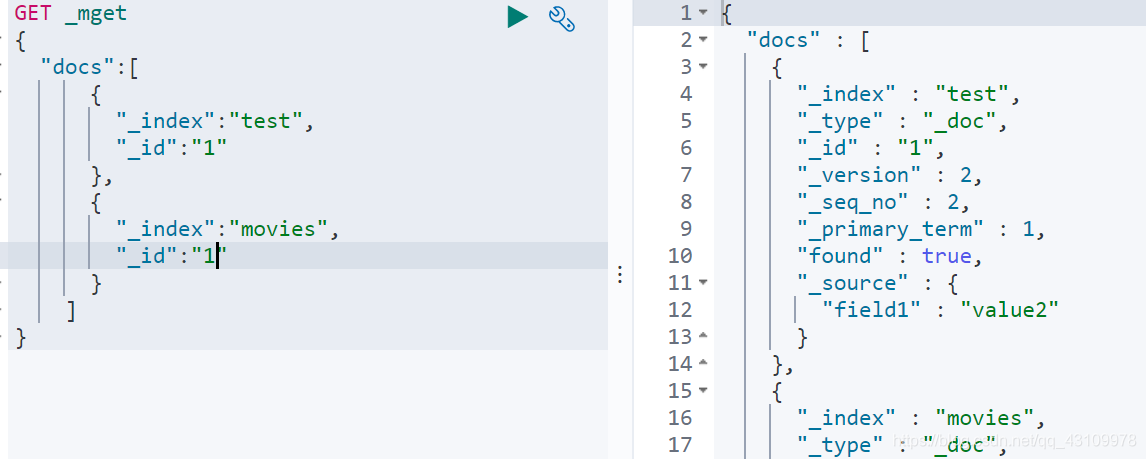
批量查询 _msearch