文章目录
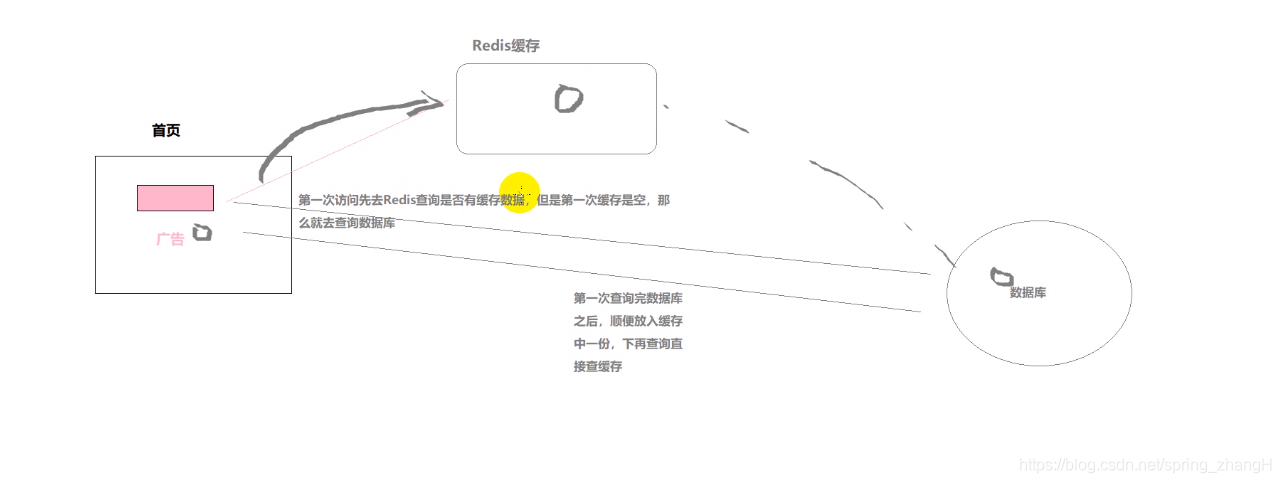
什么样的数据适合放入缓存中?
变化频率不高的数据适合放入缓存中
1:Redis是什么
Redis是一个no sql的数据库
no sql:非关系型的数据库 ------ Redis还是一个数据库
MySQL/Oracle数据库:关系型的数据库
关系:
1:表与表之间的关系
2:对象和表之间的关系
非关系型的数据库:指的是不存在表与表之间的关联、以及对象和表之间的关联
而且:非关系型数据库中 根本连表都不存在 没有表这个概念
存储到Redis中的数据都是以 键值对 的形式来进行存储的
Key–value
所以说 Redis你又可以看成是一个基于键值对形式的存储系统 类似于我们前面学习的map集合一样 都是以key—value的形式来玩的
2:Redis能干什么
2.1:做数据的缓存
2.2:购物车数据的存储
2.3:商城中评论的存储
2.4:商城中评分的存储
2.5:商城中最热商品的存储
2.6:商城中秒杀的设计
2.7:完成发布订阅(消息队列的功能)
Redis在开发中用的是非常多的、而且在面试职工也是重点
3:Redis的特点
3.1:Redis的最大的特点就是基于内存的(读写的速度非常的快)
3.2:如果出现了断电 那么Redis中的数据 会发生丢失(Redis的使用场景一定是对数据要求不严格的地方)
3.3:Redis中所有的存储结构 都是以键值对的形式来玩的(使用起来相当的方便)
3.4:Redis中提供了多种不同的数据类型来满足不同场景下的解决方案
3.5:Redis还提供了两种不同的持久化(将内存的数据 同步到硬盘)方案
3.6:Redis中有大量的命令集 这些命令集 就使得操作Redis变得了非常简单
3.7:Redis1.0的时候提供的是主从模式 2.0的时候提供了哨兵模式 3.0的时候提供了集群模式
4 redis的数据类型
Redis中五种不同的数据类型的使用场景是什么(面试问得多)
String:最大的使用是缓存(做数据缓存)
Hash:可以用于单点登录、可以存放购物车的数据、这个可以用用来代替以前的Session
List:可以存放评论、打分、回复… List中数据有序可以重复
Set:数据是无序不能重复的 找共同的好友
Sorted set:最大的用处就是找最热的商品
5:Redis的基本命令的使用
key相关的命令:
keys *:查看当前数据库中所有的key
select 下标(数据库下标) :表示切换到某一个数据库,Redis默认是有 16个数据库,默认数据存储是存储到0号数据库中的
del key:删除某一个key
exists key:判断某一个key是否存在 在当前数据库中
expire key:给这个key设置过期时间 expire:到期,过期的意思
例如:expire xiaobobo 1000 表示将xiaobobo这个键设置了过期时间,1000秒后将会删除。
ttl key:获取某一个key的过期时间 -1:表示永远不过期
move key 数据库下标:表示的是将一个key-value移动到另外一个数据库中去
randomkey:返回一个随机的key
String类型相关的命令
set key 值:设置一个键值对到数据库中
get key 从数据库中获取一个key对应的值
mset k v k v:一次性设置多个键值对
mget k k k:一次性获取获取键对应的值
setnx k v:表示的是当k不存在的时候才设置这个键值对
incr key:表示的是自增 这个值必须要是 number才有用
incrby key 步长:这个键的值每一次增加多少的步长
decr 键 :这个表示的是递减
decrby 键 步长:每一次减多少的问题
getset key 000 表示先获取可的值再设置成000,key必须先存在,如果不存在则设置失败。
hash结构的玩法
hset 集合的名字 键 值 :向某一个集合中添加数据
hget 集合的名字 键:获取集合中某一个key的值
hdel 集合的名字 键:删除集合中某一个key
hexists 集合的名字 键:判断集合中某一个key是否存在
hincrby 集合的名字 key 步长:给集合中某一个key指定增量
hkeys 集合的名字:获取的是当前集合中的所有的key
hlen 集合的名字:获取当前集合中数据的个数
hvals 集合的名字:获取当前集合中所有的值
list数据类型的玩法
lpush 集合的名字 集合中的值 :表示的是向这个集合中添加数据(压栈)
llen 集合的名字:获取集合中数据的个数
lpop 集合的名字:弹栈
lrange 集合的名字 开始位置 结束位置 :获取集合中指定位置的数据
lrem 集合的名字 删除的值的个数 要删除的这个值:删除某一个值 删除多少个
set类型的常用的方法(无序)
sadd 集合的名字 集合的值:向某一个集合中添加数据
scard 集合的名字:获取集合中数据的个数
smembers 集合的名字:获取这个集合中的值
spop 集合的名字 个数:弹栈(个数表示的是弹栈多少的数据)
sorted Set类型的常用命令 (Zset)
zadd 集合的名字 打分 键的名字:表示的是给某一个键大哥分存储下来
zcard 集合的名字:获取集合中的值的个数
zcount 集合的名字 开始区间 结束区间:获取集合中开始区间到结束区间之间的值的个数
例如:zcount hodproduct 0 100 获取0-100之间商品的个数。
zrange 集合的名字 开始区间 结束区间:获取开始区间到结束区间之间的节点的key值
例如:zrange hodproduct 0 10000 获取0—1000分之间的数据,从小到大排列
zscore 集合的名字 键的名字:获取某一个键的得分
zrem 集合的名字 键的名字:删除集合中的某一个key
zincrby hotProduct 1000 goodId1 :给某一个key增加一个得分
ZREVRANK hotProduct goodId5 :获取某一个值的排名
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] 获取最热商品从大到小排名
发布订阅模式:(一般不用)
什么叫做 发布订阅模式呢?
收音机------调广播的频道------你收听这个频道的内容
你如果订阅了某一个频道 那么这个频道传递过来的消息 你都可以接受到
这个家伙实际上干的事情是:消息队列干的事情
subscribe 频道名字:订阅某一个频道
publish 频道的名字 值:在某一个频道发布一个数据
Redis中的事务(没用)
Multi 开始事务
…
…
…
Exec 执行队列中的命令
Redis中的事务并不能保证事务的原子性 所以没啥用…
6. Redis中的持久化模式
什么叫持久化
所谓的持久化:表示的是 内存的数据最终会保存到硬盘的这个操作
RDB模式
默认就是rdb的模式
save 900 1 :在15分钟的时间内 如果有1个key发生改变 那么内存将会硬盘进行同步
save 300 10 :在5分钟的时间内 如果有10个key发生改变 那么内存将和硬盘同步
save 60 10000 :在1分钟的时间内 如果有1000个key发生改变 那么内存也将和硬盘同步
6.1 RDB模式 到底是如何将内存的数据 同步到硬盘的?
1:先将硬盘上的内容给清空 然后再将内存的数据 全部写入到硬盘 所以这种模式一般情况下 用来做数据的备份 生产环境中一般不会使用它
6.2AOF模式
appendonly yes
AOF模式的三种策略
appendfsync always :表示的是只要你的内存有key发生改变 那么立马内存的数据就要和硬盘同步 会产生频繁的IO操作 效率低
appendfsync everysec:每秒钟数据同步一次 (应该是选择 开发中的选择)
appendfsync no:永远不同步 数据只是存储到内存
AOF怎样来进行数据同步的
AOF模式在进行数据同步的时候 不会删除原来的内容 只是更改 改变的内容 进行追加
所以这种模式 也是生产环境中 我们经常用到的模式
即使有数据的丢失的话那么也只是丢失1秒钟的数据
