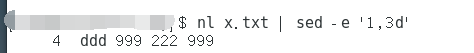管道相关命令
1 cut:根据条件从命令结果中提取对应内容
参数列表:
-
-b 按字节选取 忽略多字节字符边界,除非也指定了 -n 标志
-
-c 按字符选取
-
-d 自定义分隔符,默认为制表符。
-
-f 与-d一起使用,指定显示哪个区域
-
n:只有第n项
-
n-:从第n项一直到行尾
-
n-m:从第n项到第m项(包括m)
-
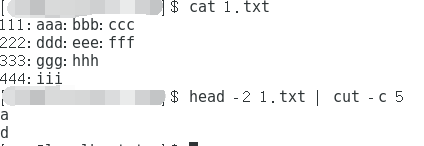
vim 1.txt
111:aaa:bbb:ccc
222:ddd:eee:fff
333:ggg:hhh
444:iii
- 截取出1.txt文件中前2行的第5个字
head -2 1.txt | cut -c 5
- 截取出1.txt文件中前2行以”:”进行分割的第1,2段内容
head -2 1.txt | cut -d ':' -f 1,2 # 或者head -2 1.txt | cut -d ':' -f 1-2

2. sort:排序
参数列表:
- -u 输出行中去除重复行
- -n 按数字排序
- -r 使次序颠倒
- -t 指定分隔符
- -k 根据某一列排序
vim 2.txt
banana
apple
pear
orange
pear
- 给2.txt中元素排序
sort 2.txt
- 删除2.txt中的重复行
sort -u 2.txt


vim 3.txt
1
3
5
7
11
2
4
6
10
8
9
- 给3.txt中数字按照升序排序
sort 3.txt sort -n 3.txt
- 给3.txt中数字按照降序排序
sort -nr 3.txt


3. wc:显示指定文件字节数,单词数以及行数
wc 文件名:指定文件,字节数,单词数,行数信息
参数:
- -c或–bytes或–chars 只显示Bytes数。
- -l或–lines 只显示行数。
- -w或–words 只显示字数。
- –help 在线帮助。
- –version 显示版本信息。
- 统计1.txt中的信息
wc 1.txt
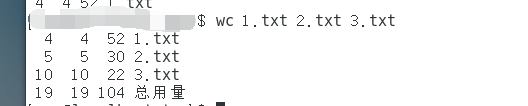
- 统计多个文件信息
wc 1.txt 2.txt 3.txt
- 查看目录下有多少个文件
ls / | wc -w


4.Uniq:检查及删除文件文本中的重复出现行(常和sort连用)
参数:
- c:统计行数
- 统计2.txt中每行内容出现的次数
cat 2.txt | sort | uniq -c
- 去除2.txt中的重复行
cat 2.txt | sort | uniq


5. tee:重定向
参数:
- -a:追加
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KanUZNuX-1578741850500)(C:\Users\acer\Desktop\新建文件夹\1578659878862.png)]
- 统计2.txt中每行内容出现的次数输出到a.txt,并且把内容显示在控制台
sort 2.txt | uniq -c | tee a.txt
- 统计2.txt中每行内容出现的次数输出追加到a.txt,并且把内容显示在控制台
sort 2.txt | uniq -c | tee -a a.txt


6. tr:替换或删除文件中的字符
参数:
- -d, --delete:删除指令字符
- 将“hello, p”换成"hello, j"
echo "hello, p" | tr "p" "j"
- 将“hello”换为“HELLO”
echo "hello" | tr "[a-z]" "[A-Z]"
- 删除abc1d4e5f中的数字
echo 'abc1d4e5f' | tr -d '[0-9]'



7. split:将大文件分为若干个小文件
参数:
- -b<字节> : 指定每多少字节切成一个小文件
- -l<行数> : 指定每多少行切成一个小文件
split -l 2000 v.txt
split -b 1k v.txt
8. awk: 实现模糊查询,按需提取字段,还可以进行判断和简单的运算





vim x.txt
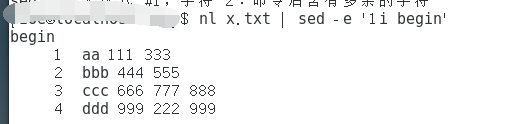
aaa 111 333
bbb 444 555
ccc 666 777 888
ddd 999 222 999
- 打印输出第一段
awk '{print $1}' x.txt
- 打印输出1,2,4段,用#号连接
awk '{print $1 "#" $2 "#" $4}' x.txt
awk -F " " '{OFS="#"}{print $1,$2,$3}' x.txt
3. 以指定分隔符分割awk -F ':' '{print $1}' x.txt
- 匹配有’cc’的内容
awk '/cc/' x.txt
- 匹配第1段包含至少连续两个c的内容
awk '$1 ~ /cc+/' x.txt
- 如果匹配到aaa就打印第1,3段,如果匹配到ccc,就打印第1,3,4段
awk '/aaa/ {print $1,$3} /ccc/ {print $1,$3,$4}' x.txt
- 如果第3段小于第4段就打印全部
awk '$3<$4 {print $0}' x.txt
- 显示行号
awk '{print NR " " $0}' x.txt # 不能用单引号
- 显示段数
awk '{print NF " " $0}' x.txt
- 打印前2行,并且第1段匹配 aa或者eee,打印全部,打印行号
awk 'NR<=2 && $1 ~/aa|eee/ {print NR " " $0}' x.txt
11. 打印前两行,并显示行号nl x.txt | head -2
nl x.txt | sed -ne '1,2p'
awk -F ":" 'NR<=2 {print NR " " $0}' x.txt
12. 将第一段内容替换为"abc",指定分隔符为|,显示行数cat x.txt | head -3 | awk -F" " '{OFS="|"} $1="abc" {print NR " " $0}'



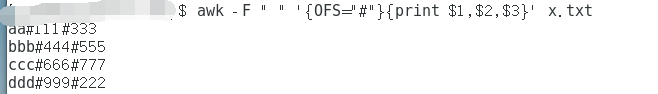
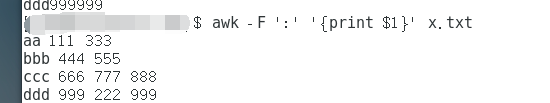









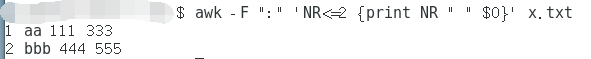

vim score.txt
张三 98 99 26
李四 100 99 09
王五 90 33 42
赵六 95 98 68
麻七 70 68 87
- 分段求和,对第二段求和
awk -F '\t' 'BEGIN{}{total=total+$2}END{print total}' score.txt
14. 打印九九乘法表awk 'BEGIN{ for(i=1;i<=9;i++){ for(j=1;j<=i;j++){ printf("%dx%d=%d%s", i, j, i*j, "\t" ) } printf("\n") } }'


9. sed :实现过滤和替换功能
参数:
- -n 仅显示处理后的结果
- -e 以选项中指定的脚本来处理输入的文本文件
- -f 以选项中指定的脚本文件来处理输入的文本文件
动作说明:
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
- d :删除
- a :新增,内容出现在下一行
- i :插入, 内容出现在上一行
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
- s :取代,可以直接进行取代的工作!通常这个 s 的动作可以搭配正规表示法!
- = :显示行号
- 列出第2到第5行数据,并显示行号
nl x.txt |sed -n -e '2,5p'
- 删除前3行数据,并显示行号
nl x.txt | sed -e '1,3d'
- 在第一行后添加’aaaa 111 1 22’
nl x.txt | sed '1a aaaa 111 1 22'
- 在第一行前面添加‘begin’
nl x.txt | sed -e 'li begin'
5. 查找包含’aa’的行sed -ne '/aa/p' x.txt