一、疑问
前期学习过程当中,我们知道kafka为了提高数据的并发处理,将一类消息及topic发送到多个Partition当中,它是如何分区呢,生产者又是如何知道将具体的某一个数据发送到相应的Partition上呢?
下面我们看一下ProducerRecord 对象,生产者发送消息到kafka集群,new了一个ProducerRecord对象,通过对象重载实现了分区原则。

-- Topic (主题名,不能为空)
-- PartitionID ( 可选)
-- Key[( 可选 )
-- Value①前四个对象带有参数Integer partition ,指定Partition ID,则PR被发送至指定Partition。
②未指定 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值。
③未指定partition 值也未指定 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin(轮循)算法。
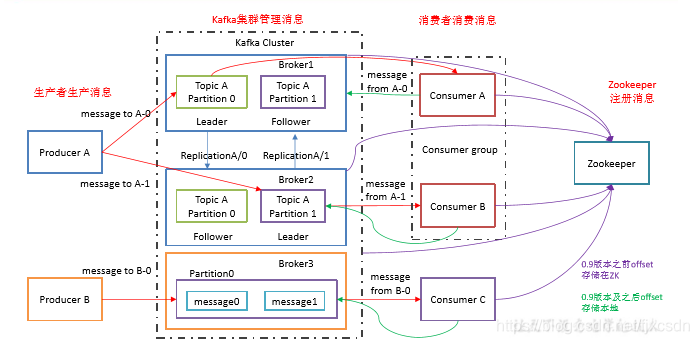
二、生产者将消息发送到了brokers服务器上,它是如何确定自己发送的消息已被服务器成功接收,并进行了备份呢?—数据可靠性保证
当生产者将数据发送到指定的topic的各个分区后,每个分区如果成功接收,就会向生产者发送ack(acknowledgement:确认收到),生产者接收后,继续发送下一轮消息。如果没有收到,则重新发送。
发送数据到每一个分区的leader,follower需要备份,即同步leader中的数据。是所有的follower备份完成以后发送ack呢,还是当一半的follower需要备份完成以后发送ack呢。
分析,如果全部follower同步完成备份后发送ack,这样延迟就会很高,也就是说时间性能更差一些。
如果部分follower同步完成备份后发送ack,虽然延迟低了,但是存在一个问题,如果一个集群能容忍n台机器故障,则这个方案至少需要2n+1个备份,这样在内存消耗方面就会消耗巨大,而如果全部follower同步完成备份后发送ack,则至少需要n+1个备份,只要有一台备份成功,就能保证数据恢复。
最终:kafka 是所有备份完成以后,才会发送ack的。(虽然延迟高,但是内存消耗小)。
三、生产者的ISR(in-sync replica set)
通过以上我们知道kafka 是所有的副本同步完成以后,才会发送ack的,此时问题产生了,有的副本同步慢,有的同步快,同步慢的导致生产者永远接收不到ack,此时就导致了系统瘫痪,所以引入了ISR。
ISR是一个follower集合,ISR中的follower同步完成leader中的数据后,会向leader发送一个ack,如果在一个时间阈值内(该阈值由replica.lag.time.max.ms 参数设定),有的follower没有给leader发送ack,则该follower将会被踢出ISR集合,当leader发生故障,ISR中将会选择新的leader。
四、生产者的ACK机制
kafka提供了三种可靠性级别,用户可以根据acks的参数进行配置。
0: 生产者不需要接收broker的ack,这样虽然延迟行降到了最低,但是这就会造成服务器中还未接收完数据,就被返回了,造成了数据的丢失。
1:生产者接收broker的ack,即leader同步完成后就发送ack,不需要等待副本全部同步完成,此时leader瘫痪,则也会造成数据的丢失。
-1(all) :生产者接收broker的ack,即leader接收数据完成,follower 也同步完成了数据,broker发送ack之前,leader瘫痪,则会造成数据重复。

LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,ISR 队列中最小的 LEOleader 瘫痪后, ISR 中将会选出一个新的 leader,为保证多个副本之间的数据一致性,follower 会将高于 HW 的部分截掉,然后从新的 leader同步数据。
