前言
我们计算机上面跑的每个任务,都是操作系统层面的资源分配,从启动进程到创建线程,在核数固定的情况下,多线程并发地执行。Go协程是一个比系统线程更细粒度的资源,轻量级和易切换。
这几天看了一些相关的文章,这次尝试从操作系统到Go协程,简单聊聊它们是如何关联上的以及我个人的理解。
基本概念
操作系统(OS)
操作系统负责着底层硬件的调度,它分配CPU,内存,磁盘的资源,并且替我们分配不同线程在不同CPU核的执行,保证各个程序如预期的指令进行执行。我们提交的每个程序,最终都会转换成一系列给操作系统识别的指令。
线程(Thread)
上述经过转换的一系列指令,操作系统会通过线程来帮我们执行,本质上线程是a path of execution,一段可执行的程序路径。
线程有下面三个状态:
- 运行中:正在执行任务,理想状态是所有线程都处于这个状态。
- 就绪:可以随时加入运行,从就绪到运行的状态切换,叫做上下文切换,它需要一定的代价。
- 等待就绪:需要等待资源分配或者IO(网络/设备)阻塞中,需要经过就绪才能运行,这是在用户角度最不想看到的,它成为了程序大部分的性能瓶颈。
系统调度器
调度器肩负着巨大的使命,主要在于调度CPU与线程关系,保证不会有CPU闲下来,想象一下CPU就是仓鼠笼子里面的仓鼠,调度器一旦发现有仓鼠(CPU)在打瞌睡,就推动它们到轮子(线程)上跑,一刻也不能停。毕竟CPU的运算能力是很强悍的,一毫秒的空闲都是巨大的浪费。
往细处说,仓鼠只有4只(四核),哪个轮子(线程)优先跑,取决于轮子(线程)的优先级。调度器肩负着运筹帷幄的使命,既要减少催促仓鼠跑动的延迟,同时还要保证不能有任务一直得不到执行,线程如果一直得不到仓鼠处理被称作“饥饿现象”。
任务类型
不同的任务对系统资源有不同的要求
-
I/O频繁切换:
未雨绸缪,IO指的是Input/Output,输入输出等待。这种等待资源输入/输出的job,主要瓶颈在资源是否分配到位,比如系统调用/文件IO等,其线程切换的时间远远小于IO设备/网络延迟,主要短板在于等待I/O,而不是线程上下文切换,因此可以分配较多线程,在“粮草”还没送到的这段时间,执行作战前的准备。 -
计算密集型:
这种任务主要耗CPU,比如用一个线程计算圆周率π的第N位。如果分配大量的线程给它,系统既要保证各个线程对计算状态的共享,先不考虑会发生脏读/脏写操作,还需要频繁进行线程切换,这会造成大量时间浪费,线程每次重新唤醒都要在程序计数器(PC)寻找下一个执行指令的位置,在核数固定的情况下,分配过多线程会有事倍功半的效果。If your program is focused on CPU-Bound work, then context switches are going to be a performance nightmare. Since the Thead always has work to do, the context switch is stopping that work from progressing.
当然也有例外的情况,比如Map-Reduce,指的是先拆分后聚合。当你的计算任务可以拆分成很多模块,在各个模块不同执行顺序不会影响最终结果的情况下,尝试“逐个击破”,最终再汇聚的情况,如果能合理分配任务,多线程肯定是优于单线程的。
后面尝试通过列举几个Go的简单程序,通过单/多协程处理,比对两者在不同情景的性能差异情况。
Map-Reduce:
这个例子比较简单,我们目标是累加一个等差数列
var PIXEL_ARRAY []int
//初始化一个等差数列,后面尝试将等差数列传到单协程/多协程函数进行累加
func init() {
for i := 1; i <= 100000; i++ {
PIXEL_ARRAY = append(PIXEL_ARRAY, i)
}
}
后面我们用单协程/多协程版本,区分开两个实现方式
//单协程暴力版本
func SumWithSingle(arr []int) int32 {
var sum int32
//遍历累加,相当暴力!
for i := 0; i < len(arr); i++ {
sum += int32(arr[i])
}
return sum
}
//多协程版本,每个协程均等计算自己分配的切片区间, gNum是起多少个协程并发处理
func SumWithMulti(arr []int, gNum int) int32 {
var wg sync.WaitGroup
//用于等待gNum个协程执行完
wg.Add(gNum)
var sum int32
//各个任务的平均长度
div := len(arr) / gNum
//注意切割长度需要向上取整,此处非本demo侧重点,为了简单化一律使用整除切开原数组.
//div := int(math.Ceil(float64(float64(len(arr)) / float64(gNum))))
for i := 0; i < gNum; i++ {
Left := i * div
Right := Left + div
if i == gNum {
Right = len(arr)
}
go func() {
//每个协程独立的汇总
ps := 0
for _, value := range arr[Left:Right] {
ps += value
}
//处理完累积到全局变量,由于仅有累加操作,可以用原子加实现互斥, 这里无需加锁.
atomic.AddInt32(&sum, int32(ps))
wg.Done()
}()
}
//等待各个子协程计算完毕
wg.Wait()
return sum
}
性能分析
下面尝试用BenchMark分析性能,输出如下:
import "testing"
var PIXEL_ARRAY []int
func init() {
for i := 1; i <= 100000; i++ {
PIXEL_ARRAY = append(PIXEL_ARRAY, i)
}
}
func BenchmarkSumWithSingle(b *testing.B) {
for i := 0; i < b.N; i++ {
SumWithSingle(PIXEL_ARRAY)
}
}
func BenchmarkSumWithMulti(b *testing.B) {
for i := 0; i < b.N; i++ {
SumWithMulti(PIXEL_ARRAY, 10)
}
}
结果示例:
在4核电脑上,启动10个协程去并发处理,针对这个例子多协程是优于单协程的,符合预期。
$ GOGC=off go test -run none -bench . -benchtime 3s
goos: windows
goarch: amd64
pkg: HelloGo/basic/Multi
BenchmarkSumWithSingle-4 50000 63583 ns/op
BenchmarkSumWithMulti-4 100000 39216 ns/op
PASS
ok HelloGo/basic/Multi 8.623s
在操作系统层面,每个线程的执行先后顺序是无法保证的。Go中,协程也是如此。拿上个例子来说,Map-Reduce的Map操作是切开等差数列,分配到任务的不同Go协程执行时间是不确定的,有可能1+2+3+..., 也有可能是21+22+23+...
如果程序要控制相应线程执行的顺序,需要在操作系统的上一层,比如编程语言中加入调度指令,如++原子操作,同步锁,互斥量++,程序的性能也和锁的粒度有关系,这个相关知识可以作为以后拓展。
Go调度器的实现是基于操作系统调度这些理念实现的,后面我们尝试往更高层(用户态)走,以Go协程是如何被调度的角度来分析。
Go Scheduler
众所周知,Go调度器有下面几个主要的组件:
- M: 工作线程, 由P创建,关联上OS线程,可以理解为M就是OS线程
- P: 上下文,处理代码的所需资源, 创建数量与CPU核数相关,每个P会分配一个OS线程(M)
- G: 当前go协程,如果关联上OS线程(M),代表即将或者正在执行的go代码。G可以在两个队列中找到它们,本地/全局队列,我们后面再细谈。
At any time, M goroutines need to be scheduled on N OS threads that runs on at most GOMAXPROCS numbers of processors.
P,逻辑CPU
GO的P和你的CPU核心数量有关,注意这里并不是真正CPU数量,是++逻辑CPU数量++。查看任务管理器,在4核CPU的情况下,假如说你的机器具备超线程(i7处理器),每个物理核有两个线程,那么意味着在Go程序里逻辑上有8个可用的处理器,逻辑CPU数量应该是8。即上面所提到的P。
我当前机器是(i5处理器),每个核一个线程,所以下面输出的逻辑CPU(P)数量是4,这代表当启动多个线程的时候,我的机器最多可以支持并行4个系统线程,多出来的线程就是并发了。
可以通过在你的机器执行下列Go代码,看下逻辑P的数量,
package main
import (
"fmt"
"runtime"
)
func main() {
// NumCPU returns the number of logical
// CPUs usable by the current process.
//我的机器输出 4
fmt.Println(runtime.NumCPU())
}
每一个P会分配一个系统线程M,相当于说在这个机器的Go程序中,我有4个系统线程可以用来执行我的任务,每个都独立与其中一个核,P挂钩。
M个Go协程会分配在N个系统线程上,每个要运行的G都必须关联上P(逻辑CPU),程序可以干涉GOMAXPROCS的数量,以控制最多有多少个P可以使用。
下面用图示可能会更加直观:
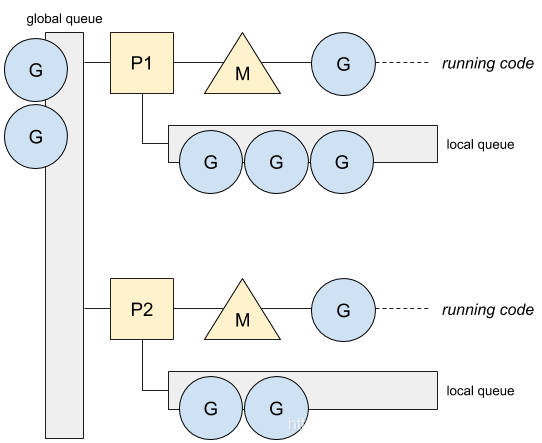
在Go中,每个上下文P会分配一个本地的协程队列(LRQ),叫做Local Run Queue ,一个M必须关联所需的资源P才能运行相应的G队列,正如操作系统层面上每个线程队列需要分配关联上CPU才能得到执行,类比前面的栗子,轮子(M)需要仓鼠(P)去带动,才能执行(跑G协程任务)。
如下图所示:
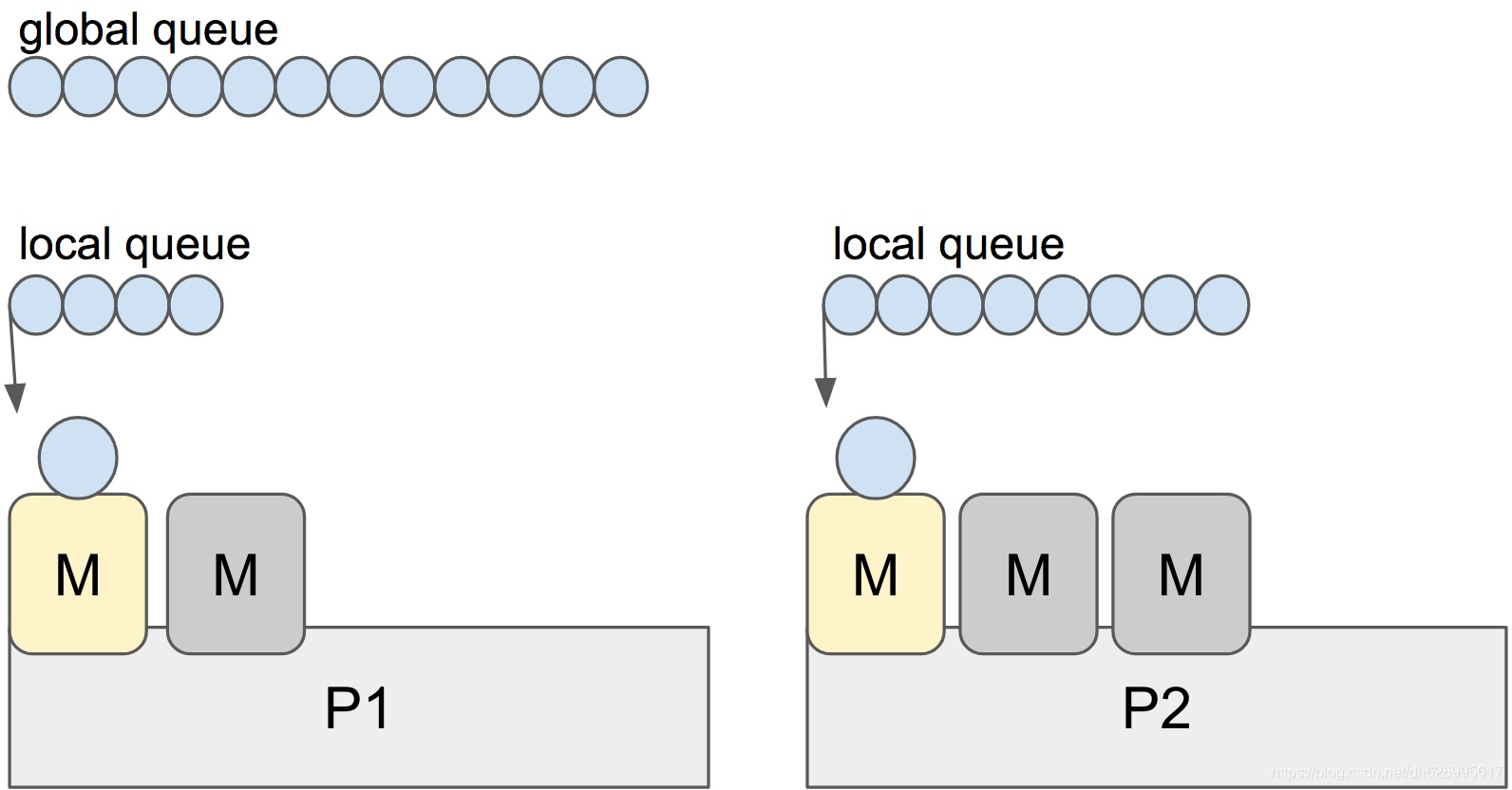
P1,P2是相对固定的,M和G是可以随调度器分配选择的。
Go协程的切换
理解完上面的一些概念之后,现在我们看下Go是如何对协程进行切换,文章前面提到,假如线程创建过多,由于系统调度的不确定性,线程得不到执行,可能会长期处于饥饿。同理Go协程也会有“靠边停车”的现象,所以Go调度器需要一些的条件来触发协程切换,避免停完车就不再启动了,具体的切换本质上就是Go调度器对P-M-G三者之间的断开与重连。
下列情景可能会让调度器对执行上下文,即go协程的切换做出决定:
- go关键字,创建新的协程
- 垃圾回收
- 系统调用
- 同步/互斥/
Gosched()等操作
程序示例:
下面展示一个简单而且比较常见的例子,我们通过限制逻辑CPU的个数,尝试干涉Go调度器。
func main() {
//设置最多一个P可以关联上
runtime.GOMAXPROCS(1)
go func() {
for {
//保持空转,如果没有其他函数调用,在单个处理器下该协程不会切换
;
}
}()
//尝试切换协程
runtime.Gosched()
println("main done.")
}
我们通过runtime.GOMAXPROCS(1)设置本次运行的逻辑CPU个数,代表可用的P只有1,意味着最多只能同时分配给一个协程去执行。如果执行这个程序,由于主协程执行了让步Gosched(),获得运行权的的Go协程会得到执行,由于该协程在死循环一直执行空语句,导致程序不会有任何输出,而且主协程得不到运行权,所以这个程序永远不会退出。
题外话:注意这里区别于上面的runtime.NumCPU(int)方法,NumCPU()是在启动时候直接调用系统方法,所以和经过GOMAXPROCS的设置之后,并不会改变NumCPU()原有的返回值,GOMAXPROCS仅是对本次运行时P数量进行限制。
协程偷窃
从Go调度器角度看,执行的协程任务有点快有的慢,既然我的职责是不能让CPU空闲,那当我有空的时候,我肯定要从别人那里偷一些任务来跑。
是的,是明目张胆的偷!我觉得这张图很贴切,所以我把这张图也偷来了哈哈哈。
原文参考:Go: Work-Stealing in Go Scheduler (可能需要科学上网)
前面提到两个队列,全局/本地队列:
- 本地队列:指的是当前上下文P关联上的Go协程队列(LRQ),本地队列,在go1.13版本每个本地协程队列的最大值是256,超过256就会放到全局队列里面去。本地队列是可以被其他P偷走的,在某些情况下,当有P发现本地的G队列空了,就会去偷其他P的本地队列,每次会从其它P的本地队列里面偷走一半的G。
- 全局队列:在其他情况,当有空闲P发现其他P的本地队列没有G可以偷的情况下,会尝试获取全局队列的G去执行。
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
上面的注释表明了偷窃各个部分的优先级,只有1/61的时间会去检查全局队列。
优先级:本地队列 > 其他P的队列 > 全局队列
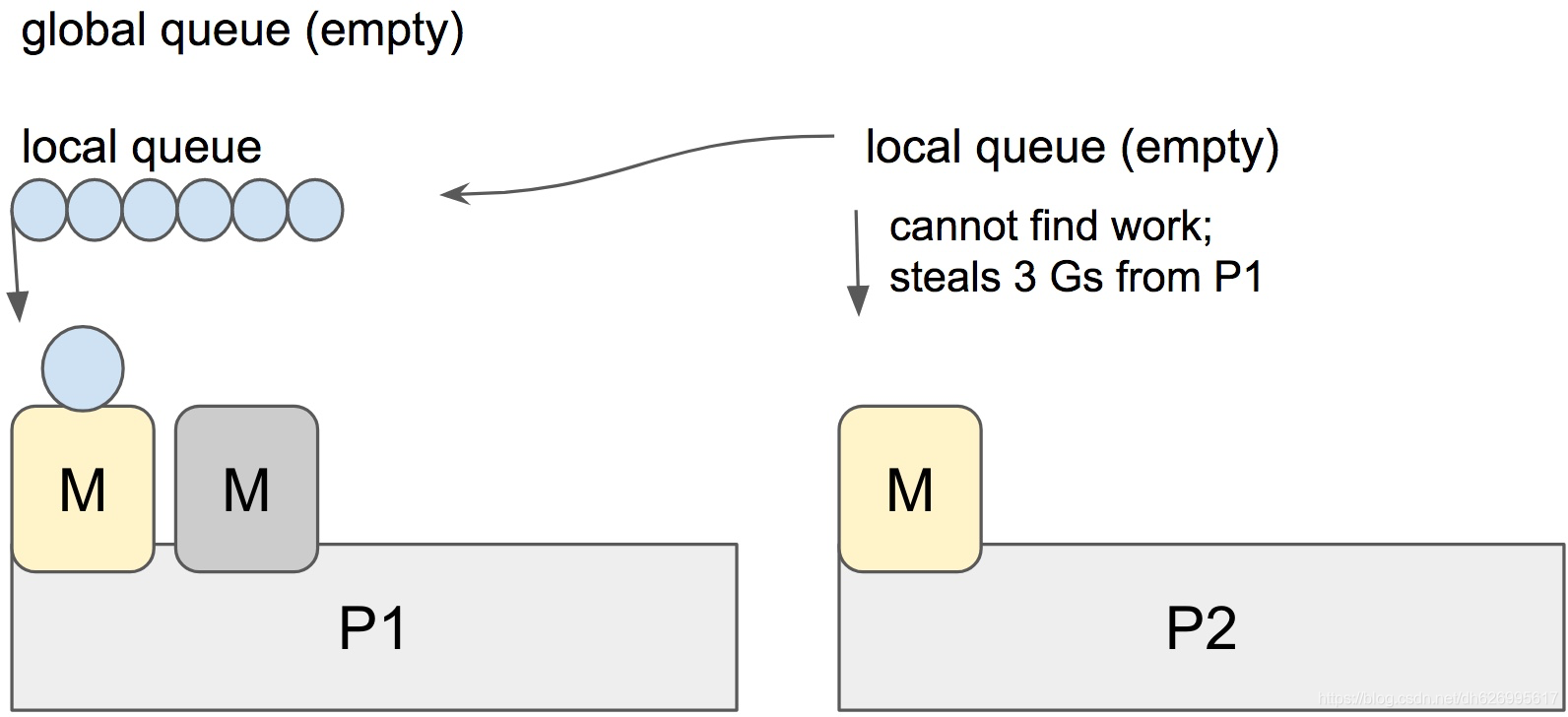
根据这张我从别处偷来的这张图,此时P2的本地队列已经是空的,所以这个时候P2即将要从P1偷走3个G
总结
Go调度的思想是基于上述系统调度实现的,归根结底Go中的协程切换是P-M-G三者之间的断开与重连。所以G协程在当前线程M的切换,就像从系统角度看,线程在CPU上面的切换。
Your workload is naturally stopped and this allows a different Goroutine to leverage the same OS/hardware thread efficiently instead of letting the OS/hardware thread sit idle.
因为Go协程比线程粒度更小,更加轻量级,所以Go协程切换会比OS直接切换线程代价更小。
到这里只是浅尝辄止的梳理Go调度的情况,大家如果有兴趣深入挖掘的话可以参考郝林老师的《Go并发编程实战》,或者直接看源码,相关的Go调度策略可以在src/runtime/proc.go找到。
参考链接
Scheduling In Go : Part II - Go Scheduler
Ardanlabs素质三连:
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
dotGo 2017 - JBD - Go’s work stealing scheduler
https://www.youtube.com/watch?v=Yx6FBsGNOp4
Go: Goroutine and Preemption
https://medium.com/a-journey-with-go/go-goroutine-and-preemption-d6bc2aa2f4b7
Go’s work-stealing scheduler
https://rakyll.org/scheduler/
