2.1 获取文本语料库
古腾堡语料库
NLTK 包含古腾堡项目(Project Gutenberg)电子文本档案的经过挑选的一小部分文本,该项目大约有25,000本免费电子图书,放在http://www.gutenberg.org/上。 找出简.奥斯丁的《爱玛》,并给它一个简短的名称emma,然后找出它包含多少个词。
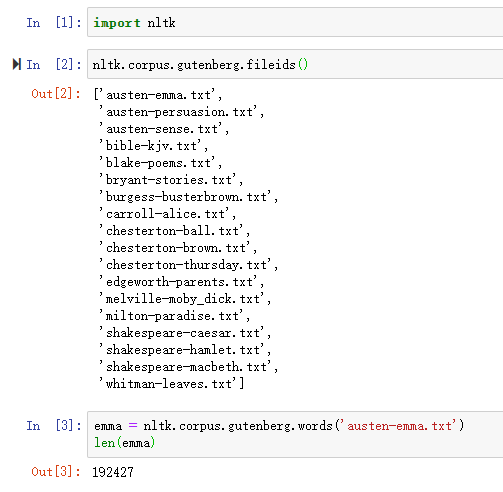
可以采用以下语句来处理索引和第1章中的其他任务

可以通过以下语句进行简化来定义emma

2.1 获取文本语料库
古腾堡语料库
NLTK 包含古腾堡项目(Project Gutenberg)电子文本档案的经过挑选的一小部分文本,该项目大约有25,000本免费电子图书,放在http://www.gutenberg.org/上。 找出简.奥斯丁的《爱玛》,并给它一个简短的名称emma,然后找出它包含多少个词。
可以采用以下语句来处理索引和第1章中的其他任务
可以通过以下语句进行简化来定义emma