一、 实验目的:
决策树分类算法(decision tree)通过树状结构对具有某特征属性的样本进行分类。其典型算法包括ID3算法、C4.5算法、C5.0算法、CART算法等。本次实验掌握用ID3的信息增益来实现决策树归纳。
二、 实验软件:
Rstudio
三、 实验思路
1.计算决策属性的熵 Info(D)
2.计算每个属性的熵 :计算年龄、收入、学生、信誉的条件熵 Info_A(D)
3.每个属性的信息增益 Gain(A)=Info(D)-InfoA(D)
4.选择节点 :选择信息增益最大的属性对数据集进行分类
四、 源代码:
#示例数据集
data<-data.frame(
Age=c("youth","youth","middle_aged","senior","senior","senior","middle_aged","youth","youth","senior","youth","middle_aged","middle_aged","senior"),
income=c("high","high","high","medium","low","low","low","medium","low","medium","medium","medium","high","medium"),
student=c("no","no","no","no","yes","yes","yes","no","yes","yes","yes","no","yes","no"),
credit_rating=c("fair","excellent","fair","fair","fair","excellent","excellent","fair","fair","fair","excellent","excellent","fair","excellent"),
buys_computer=c("no","no","yes","yes","yes","no","yes","no","yes","yes","yes","yes","yes","no")
)
info<-function(data){
rowCount=nrow(data) #计算数据集中有几行,也即有几个样本点
colCount=ncol(data)
class_result = levels(factor(data[,colCount])) # #决策变量的属性"no""yes"
class_Count = c() #存放个数
class_Count[class_result]=rep(0,length(class_result))
for(i in 1:rowCount){ #计算决策变量中每个值出现的个数
if(data[i,colCount] %in% class_result)
temp=data[i,colCount]
class_Count[temp]=class_Count[temp]+1
}
#1.计算总体的信息熵
p = c()
info = 0
for (i in 1:length(class_result)) {
p[i] = class_Count[i]/rowCount
info = -p[i]*log2(p[i])+info
}
# 2.计算每个属性的信息熵
infoA_D = function(data,k){
split_A = levels(factor(data[,k])) #某个属性可能的值
split_Acount = data.frame()
split_Acount[split_A,] = rep(0,length(split_A))
split_Acount[,class_result] = rep(0,length(split_A))
# split_Acount
for(i in 1:rowCount){ #计算决策变量中每个值出现的个数
if(data[i,k] %in% split_A & data[i,colCount] %in% class_result )
temp_A=data[i,colCount]
temp2 = data[i,k]
split_Acount[as.character(temp2),as.character(temp_A)]=split_Acount[as.character(temp2),as.character(temp_A)]+1
split_Acount$Count_D = split_Acount$no +split_Acount$yes
}
p_A = c()
info_A = 0
D_j=0
no_rate = 0
yes_rate = 0
for (i in 1:length(split_A)) {
p_A[i] = split_Acount$Count_D[i]/rowCount
no_rate[i] = split_Acount$no[i]/split_Acount$Count_D[i]
yes_rate[i] = split_Acount$yes[i]/split_Acount$Count_D[i]
D_j[i] = -(no_rate[i]*log2(no_rate[i])+yes_rate[i]*log2(yes_rate[i]))
if(D_j[i] == "NaN"){ #出现取对数为NaN的情况
D_j[i] = 0
}
info_A = p_A[i]*D_j[i] +info_A
}
return(info_A )
}
infoA_D(data,1) #age
infoA_D(data,2) #income
infoA_D(data,3) #student
infoA_D(data,4) #credi_rating
#每个属性的信息增益
age_Gain = info - infoA_D(data,1)
income_Gain = info - infoA_D(data,2)
student_Gain = info - infoA_D(data,3)
credit_rating_Gain = info - infoA_D(data,4)
Gain_frame<-data.frame(age_Gain,income_Gain,student_Gain,credit_rating_Gain)
createTree = function(gain_data,data,split_max){
#选出最大的信息增益所在的列
max<-max.col(gain_data)
#最大信息增益的属性为age属性
#根据age属性对数据集进行分类
split_max = levels(factor(data[,max]))
select = list()
for(i in 1:length(split_max)){
select[i] = list(data[data[,max] == split_max[i] ,] )
}
return(select)
}
decision_tree = createTree(Gain_frame,data)
return(list(Gain_frame,decision_tree))
}
infoResult = info(data)
infoResult
五、 实验结果:
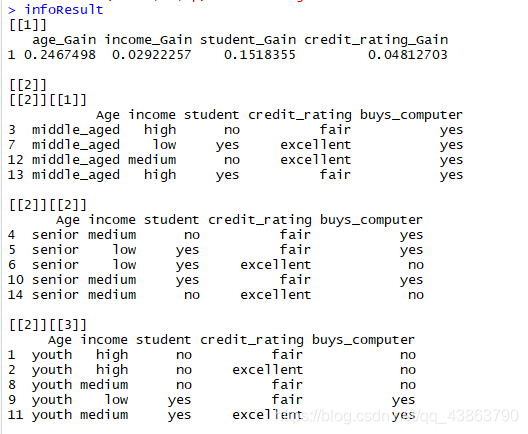
由于age属性具有最高的信息增益,所以它被选座分裂属性,元数据根据age的每个输出划分出三个子矩阵。
