去年BERT终于带动整个NLP领域火了一把。它的目标是通过预训练出的模型,很快适应新的目标任务(transfer learning)。其实NLP领域还有一大类任务需要迁移学习,就是跨语种的学习。
动机
需要跨语种学习的动机在于很多小众的语言资源缺乏。对于一个大语种来说(比如英语),因为研究的人多,所以相应的各种NLP任务的训练语料库也充分(比如sentiment analysis方面的SST,entailment inference方面的NLI等等)。但是对于世界上很多小语种来说这就显得很奢侈。如果能够通过很多语言的联合训练,产生一种"超"语言的编码器,利用它做零样本的迁移学习,就可以解决资源匮乏的问题。
举个例子来说,如果我们想解决某小众语言的语义相似性任务,在过去我们需要先建立该语言的较大规模的语义相似性数据集(在英语里对应的有STS-B),然后在上面训练出一个classifier。如果有100种小语种,我们就需要做100次这样的事情。且不说重复100次这样的工作是一种资源的浪费,单是对一个小语种建立这样一个高质量数据集就充满难度。
Facebook AI Research提出的Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond很好的解决了这个问题。它训练出了一个language agnositc的句子嵌入模型。利用它可以在英语这样的大语种上进行某一NLP任务的训练,比如说上文提到的语义相似性任务。在完成训练后可以直接零样本用在其他语种的语义相似性任务上。
近几年有一个趋势,就是monolingual和NMT之间的互动。Monolingual的语料库可以用在机器翻译任务上,反过来,NMT模型和bilingual(甚至multilingual)的语料也可以帮助monolingual的NLP任务。
Monolingual在NMT上的用途
先跑个题看看单语种语料对NMT的帮助。机器翻译需要bilingual的语料。但是相比之下monoligual的数据易得(比如网页数据)而bilingual数据稀有,那么利用monolingual语料库建立的语言模型(LM)来提高翻译质量会是一个很可行的方法。比如Dual Learning for Machine Translation by He et.al. 这篇2016年的文章提出了一个非常漂亮的想法来做翻译,它带动了后来的很多研究:去年的Zero-Shot Dual Machine Translation(ETH Zurich和Google联合发表),还有同样来自FAIR的Phrase-Based & Neural Unsupervised Machine Translation。
假设有两个智能体(agent)A和B:一个只懂A语言,另一个只懂B语言。A给B发了一个信息,为了让B听懂,A使用了一个从A语言到B语言的机器翻译模型。B智能体接收到信息(被翻译成B语言的信息)以后告诉A智能体,从纯语言的角度看, 这个信息是否是一个自然的语句。(注意这个时候B并不能判断翻译的质量,因为它并不知道A发出的原始信息是什么。) 这个关于语言是否通顺的事情,我们可以称之为信号1。
接下来B智能体使用了一个从B语言到A语言的机器翻译模型,把这个信息翻译成A语言并回传给A智能体。A接收到来自B的回传信息后,会检查该信息和它发出的原始信息的差距,并且会通知B。这个信号我们称之为信号2。
信号1和信号2作为reward,可以用来训练A和B这两个智能体用到的机器翻译模型。在以上过程中,可以交替置换A和B的角色。作者用了policy gradient methods来训练。
这个方法的前提条件是假定有两个机器翻译模型: AB之间的互译模型。并且其质量还过得去。这意味着严格来讲它不是zero-shot的学习,因为它需要基于一定数量的bi-lingual的数据集"初始化"了自己的翻译模型。 在这之后的训练过程中它不再需要任何bi-lingual的数据,仅仅依靠两种语言自己的LM,来帮助NMT进行bootstrap。 它的优点在于有效利用了易得的资源即monolingual语料来改进翻译模型。想象一下在考古工作中进行语言破译的研究,如果我们能够利用monolingual大幅度提高语言的互译会非常有帮助。
说到考古文字研究,破译玛雅语言的时候还没有机器翻译模型这回事。这说明语言学当然有它的作用。在翻译任务上,统计方法还是太嫩。
事实上dual learning这个方法能够用在一切有着dual form的任务中。比如语音识别vs.文本-语音任务,image caption vs. image generation,question answering vs. question generation等等。作者也更进一步的指出,该方法适合一切能够形成闭环的任务中,而不仅仅限于两个任务。因为对于闭环,我们总是可以用最终输出和原始输入的差别来作为反馈信号(reward)来训练模型。作者把这个更加一般化的方法称为闭环学习(close-loop learning)。
NMT在monoligual上的NLP任务的用途
上一节是说monolingual语料库作为bilingual的有益补充,帮助NMT任务。但是这个关系也可以反过来。在"动机"这一节我们说过,对于小语种来说,很多NLP的任务可以通过其他大语种来帮助完成。而连接它们的桥梁就是NMT。
FAIR的研究同时在语言维度和样本维度上做到了极致: 1.建立一个超语言的模型,同时对很多种(93种)语言成立。2.实现真正的zero-shot。
模型结构如下:
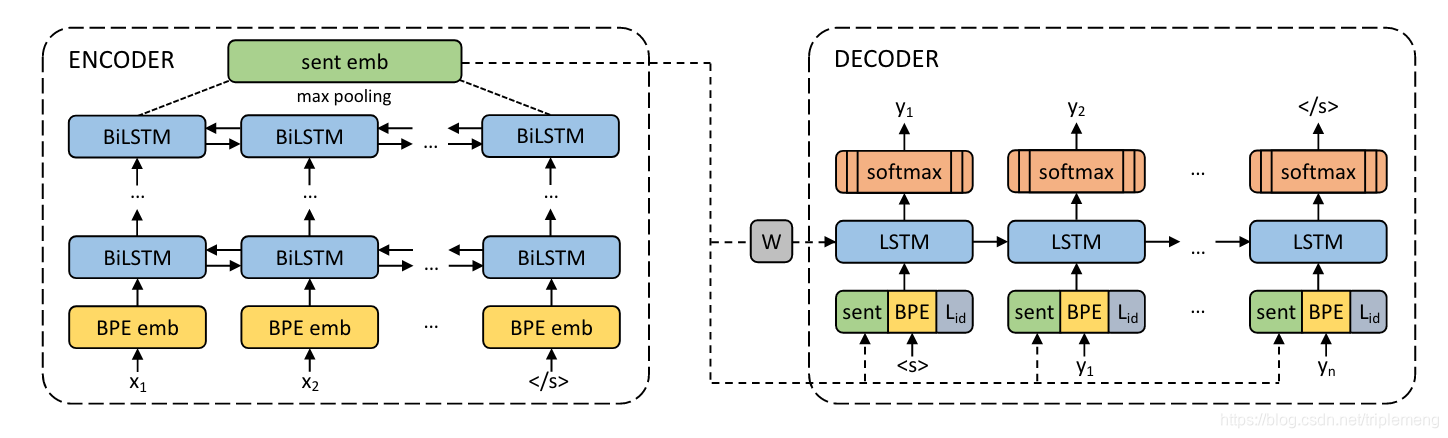 这是一个NMT模型。Encoder和decoder由所有语言共享。模型的输入利用了BPE编码对应的embedding。BPE是一种词典词汇的编码方式,大致是把语料库里最常出现的词汇的基本单元编码。Encoder由多层的双向LSTM组成,最后利用maxpooling来表征整个句子。
这是一个NMT模型。Encoder和decoder由所有语言共享。模型的输入利用了BPE编码对应的embedding。BPE是一种词典词汇的编码方式,大致是把语料库里最常出现的词汇的基本单元编码。Encoder由多层的双向LSTM组成,最后利用maxpooling来表征整个句子。
整个encoder并不接受任何语言类型方面的信息,目的就是为了训练出超越任何具体语言的表征。在下游的各种NLP的任务中,encoder的输出将作为multilingual sentence embedding的表征。
亮点在decoder上,它使用了一个language id embedding来区分不同的语言。使用语言id嵌入的原因不仅是区分目标语言那么简单。因为各个语种之间存在相关性(比如英语和德语),使用language id embedding(instead of one-hot)是最优选择。
另外注意encoder和decoder之间唯一的联系就是encoder的输出部分(即图中的sent emb),它经过一个线性变换后初始化decoder。作者说这是为了让sent emb学习到所有重要的信息。不过客观来讲,注意力机制这种建立在编码和解码器之间的联系可能不太适合多语种的训练背景。
训练数据包含93种语言。作者的研究表明实际上只使用两种目标语言(比如英语和西班牙语)就足够了,所以实际上对训练数据的要求远小于各语言两两之间互译的样本要求。训练完成后的encoder部分将用来对小语种进行句子编码,继而进行具体NLP任务的fine tuning。论文的实验里的具体的做法是:从训练好的multilingual sentence encoder出发,在上面加上一层classifier并对英语的任务数据进行训练,然后对其他的小语种语言数据进行测试。
总结
BERT和这项工作可以看成是在NLP的transfer learning这个领域里的不同维度上的努力。一个旨在训练出能够应付各种任务的universal sentence embedding,另一个是要训练出能够处理各种语言的multilingual sentence embedding。 如果一个模型能够找到language agnostic的表征,也许这意味着一种对语言背后的思想的一种近似。联系encoder和decoder的attention机制可能不适合多语种联合训练,但是我觉得self-attention会有作用,不知道把编码和解码部分换成transformer效果会怎么样。据说非洲存在2000种语言,这个跨语种的编码器应该可以援助一下非洲。
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关计算机视觉

