文章目录
一、简介
事务的隔离级别有 4 个:
- 读未提交(Read Uncommitted)
- 读-提交 (Read Committed)
- 可重复读(Repeated Read,快照隔离,也称多版本并发控制 “MultiVersion Concurrency Contorl,MVCC”)
- 可串行化(Serializable)
事务提供的保证,如表格:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可以 | 可以 | 可以 |
| 读已提交 | 不可以 | 可以 | 可以 |
| 可重复读 | 不可以 | 不可以 | 可以 |
| 可串行化 | 不可以 | 不可以 | 不可以 |
(1)危险指标
1. 脏读
假定某个事务已经完成部分数据写入,但事务尚未提交(或中止),此时另一个事务是否可以看到尚未提交的数据呢?
如果是的话,那就是脏读。
造成后果:数据不一致。
2. 脏写
如果两个事务同时尝试更新相同的对象,我们不清楚写入的顺序,但可以想象后写的操作会覆盖较早的写入。
如果先前的写入是尚未提交事务的一部分,是否还是被覆盖?如果是,那就是脏写。
造成后果:并发问题,数据丢失。
3. 不可重复读(nonrepeatable read) 或 读倾斜(read skew)
所谓不可重复读是指在一个事务内根据同一个条件对行记录进行多次查询,但是搜出来的结果却不一致。
发生不可重复读的原因:是在多次搜索期间查询条件覆盖的数据被其他事务修改了。
看起来蛮符合逻辑的,但在一些场景下这是不能容忍的。
比如:
- 备份场景
备份任务要复制整个数据库,这可能需要数个小时才能完成。在备份过程中,可以继续写入数据库。
因此,得到镜像里可能包含部分旧版本数据和部分新版本数据。
如果从这样的备份进行恢复,最终就导致了永久性的不一致。
- 分析查询与完整性检查场景
有时查询可能会扫描几乎大半个数据库。这类查询在分析业务中很常见。
或者定期的数据完整性检查(即监视数据损坏情况)
如果这些查询在不同时间点观察数据库,可能会返回无意义的结果。
4. 写倾斜(write skew)
写倾斜:它既不是一种脏写,也不是更新丢失,两笔事务更新的是两个不同的对象。可看为更为广义的更新丢失问题。
举个栗子:
场景:一个急诊科至少需要一个医生值班。
有一天,Alice 和 Bob 同时值班。这时 Alice 和 Bob都有事,于是申请调班。
- Alice事务
// 查询急诊科有多少人值班?
SELECT COUNT(*) FROM doctors WHERE shift_id = 1234 AND on_call = true;
// 人数 > 1, 更新调班
UPDATE doctors SET on_call = false WHERE name='Alice' AND shift_id = 1234;
- Bob事务
// 查询急诊科有多少人值班?
SELECT COUNT(*) FROM doctors WHERE shift_id = 1234 AND on_call = true;
// 人数 > 1, 更新调班
UPDATE doctors SET on_call = false WHERE name='Bob' AND shift_id = 1234;
这时 Alice事务 和 Bob事务 都查到人数 > 1,然后更新了调班,并发情况下,就会发生急诊科就没人值班。
解决方法:
-
读锁
SELECT ... FOR UPDATE; -
实体化冲突(重新设计表)
比如将
shift抽为一张表,shift中有值班人数num,每次更新都要更新这里的记录。
5. 幻读
幻读:一个事务中的写入改变另一个事务查询结果的现象。
快照级别隔离可以避免只读查询时的幻读,但是对于 读-写事务(写倾斜),却不能为力。
二、读提交
它提供以下两种保证:
- 读数据库时,只能看到已成功提交的数据(防止 “脏读”)
- 写数据库时,只会覆盖已成功提交的数据(防止 “脏写”)
读提交是 Oracle 11g、PostgreSQL、SQL Server 2012、MemSQL等数据库的默认配置
(1)防止脏写
采用行级锁来防止脏写
当事务想修改某个对象(例如行或文档)时,它必须首先获得该对象的锁。
如果有另一个事务尝试更新同一个对象,则必须等待,知道前面的事务完成了提交(或中止回滚)后,才能获得锁并继续。
(2)防止脏读
有两种方法:
- 读锁
- 版本号(类似乐观锁)
1. 读锁
使用相同的锁,所有试图读取该对象的事务必须先申请锁,事务完成后释放锁。
运行时间较长的写事务会导致许多只读的事务等待太长时间,会严重影响只读事务的响应延迟、且可操作性差
2. 版本号
对于每个待更新的对象,数据库会维护其旧值和当前持锁事务将要设置的新值两个版本。
- 在事务提交之前,所有其他读操作都读取旧值
- 仅当写事务提交之后,才会切换到读取新值
三、可重复读(快照级别隔离)
快照级别隔离:实现通常采用写锁来防止脏写
写操作的事务会组织同一对象上的其他事务。
读取则不需要加锁。
为了实现快照级别隔离,数据库采用了 多版本并发控制(MultiVersion Concurrency Control, MVCC)
考虑到多个正在进行的事务可能会在不同的时间点查看数据库状态,所有数据库保留了对象多个不同的提交版本。
- 在读-提交级别下,对每一个不同的查询单独创建一个快照。(只保留对象两个版本:一个已提交的旧版本 和 尚未提交的新版本)
- 快照级别隔离:使用一个快照来运行整个事务
(1)PostgreSQL如何实现基于 MVCC 的快照级别隔离?
当事务开始时,首先赋予一个唯一的、单调递增的事务ID(txid)。
每当事务向数据库写入新内容时,所写的数据都会被标记写入者的事务ID。
事务ID 其实是个 32位整数,大约在40亿次事务之后会溢出。
PostgreSQL的 vacuum 进程会执行后台清理,确保不会出现异常情况
如图:
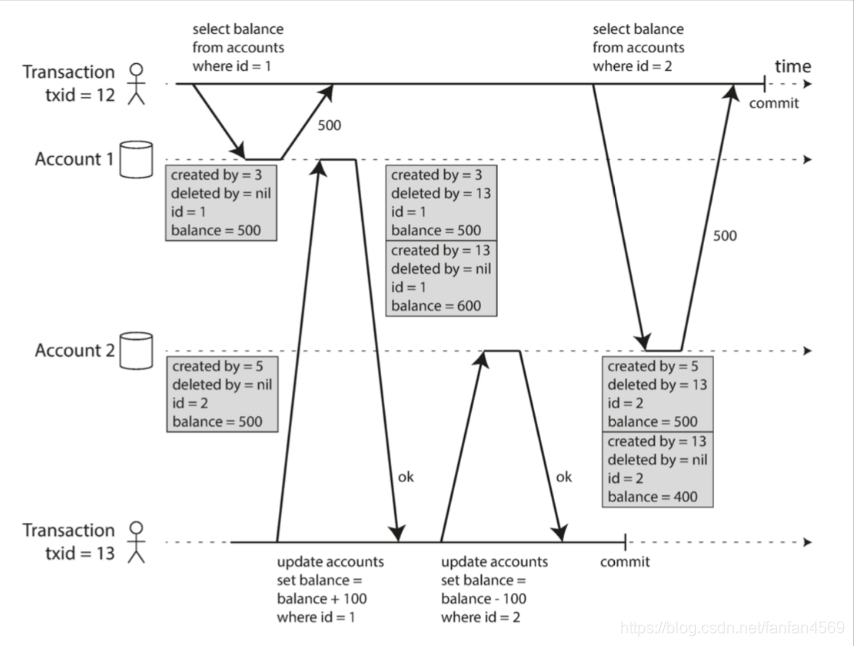
参数简介:
created_by: 包含创建该行的事务IDdeleted_by: 初识为空,如果事务要删除某行,该行实际上并未从数据库中删除,而只是将deleted_by字段设置为请求删除的 事务ID
(2)一致性快照的可见性规则
当事务读数据库时,通过事务ID可以决定哪些对象可见,哪些不可见。
-
每笔事务开始时,数据库列出所有当时正在进行中的其他事务(即尚未提交或中止),然后忽略这些事务完成的部分写入,即不可见。
-
所有中止事务所做的修改全部不可见。
-
较晚事务ID(即晚于当前事务,事务ID大的)所做的任何修改不可见,不管这些事务是否完成提交。
-
除此之外,其他所有的写入都对应用查询可见。
四、串行化
-
严格按照串行顺序执行(单线程循环来执行事务)
-
两阶段锁定(2PL)
-
乐观并发控制技术,例如可串行化的快照隔离。
… 卒
