java抓取国家行政区划
前言
- 因有需要获取国家行政区划,但这份数据并没有直接提供,因此只能从网页扒取,本人由于对python不熟,故采用java+jsoup的方式进行抓取
- 国家行政区划官网:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/
- 本文提供了三种方式保存数据
- 第一种是将数据保存为json,这种比较通用,跟业务无关;
- 第二种是直接保存进数据库(涉及到连接数据库和批量插入方法的实现,如果这些已有现成的那这种方式就非常方便);
- 第三种则是生成sql语句,利用sql语句插入数据库
分析说明
-
国家行政区划官网对区域划分了五个级别,分别为
<tr class="provincetr"></tr> <tr class="citytr"></tr> <tr class="countytr"></tr> <tr class="towntr"></tr> <tr class="villagetr"></tr> -
值得注意的是这五个级别不是连续的,目前在广东省中发现东莞市和中山市和海南省的儋州市(这几个市在city级别)的下一级是town级别,而非county级别,因此这几个市要做特殊处理
方法
保存为json方式
-
其实方法非常简单,就是分析一下网页的结构,然后解析相应的数据
-
而分析网页结构jsoup非常好用,熟悉java的可以很快上手
-
需要注意的是网页的编码是gb2312,因此不能直接解析,会有乱码,使用jsoup时需要设置一下编码
-
本方法依赖jsoup,因此需要添加依赖
// https://mvnrepository.com/artifact/org.jsoup/jsoup compile group: 'org.jsoup', name: 'jsoup', version: '1.11.3' -
为了生成json数据,因此需要添加依赖
// https://mvnrepository.com/artifact/com.google.code.gson/gson compile group: 'com.google.code.gson', name: 'gson', version: '2.8.5' -
抓取的数据格式如下(为了节省空间,只抓取了广东省下的市,更多数据可以通过配置获取)
{ "code": "000000000000", "name": "中国", "child": [{ "code": "440000000000", "name": "广东省", "child": [{ "code": "440100000000", "name": "广州市" }, { "code": "440200000000", "name": "韶关市" }, { "code": "440300000000", "name": "深圳市" }, { "code": "440400000000", "name": "珠海市" }, { "code": "440500000000", "name": "汕头市" }, { "code": "440600000000", "name": "佛山市" }, { "code": "440700000000", "name": "江门市" }, { "code": "440800000000", "name": "湛江市" }, { "code": "440900000000", "name": "茂名市" }, { "code": "441200000000", "name": "肇庆市" }, { "code": "441300000000", "name": "惠州市" }, { "code": "441400000000", "name": "梅州市" }, { "code": "441500000000", "name": "汕尾市" }, { "code": "441600000000", "name": "河源市" }, { "code": "441700000000", "name": "阳江市" }, { "code": "441800000000", "name": "清远市" }, { "code": "441900000000", "name": "东莞市" }, { "code": "442000000000", "name": "中山市" }, { "code": "445100000000", "name": "潮州市" }, { "code": "445200000000", "name": "揭阳市" }, { "code": "445300000000", "name": "云浮市" }] }] } -
贴一下实现代码
import com.google.gson.Gson; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.net.URL; import java.util.ArrayList; import java.util.List; /** * 从国家统计局网站爬取指定年份的区划数据,保存为json * 可以指定抓取的数据范围,比如全中国或指定省份 * 可以指定抓取的数据层级,比如只抓取到市或区或街道等 * */ //http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/index.html //http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/ 44.html //http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/ 44/4401.html //http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/44/ 01/440103.html //http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/44/01/ 03/440103001.html public class GenRegionCodeFromWeb { //以下值从要抓取的网页分析获得,为元素里的class值(比如<tr class="citytr"><td><a href="44/4401.html">440100000000</a></td><td><a href="44/4401.html">广州市</a></td></tr>) public static final String LEVEL_PROVINCE = "provincetr"; public static final String LEVEL_CITY = "citytr"; public static final String LEVEL_COUNTY = "countytr"; public static final String LEVEL_TOWN = "towntr"; public static final String LEVEL_VILLAGE = "villagetr"; public static final int LEVEL_MODE_STRING = 1; public static final int LEVEL_MODE_NUMBER = 2; public static final String CHARSET = "GBK"; private static List<String> types = new ArrayList<>(); static { types.add(LEVEL_PROVINCE);//表示省 types.add(LEVEL_CITY);//表示城市 types.add(LEVEL_COUNTY);//表示区 types.add(LEVEL_TOWN);//表示街道 types.add(LEVEL_VILLAGE);//表示居委会 } private static List<String> specialCitys = new ArrayList<>(); //这个列表存放的是比较特殊的市,它们是属于LEVEL_CITY,但下一级却跳过了LEVEL_COUNTY,而直接到LEVEL_TOWN //由于数据较多,不能一一比对,使用当中发现属于这种情况的城市加入到这里即可 static { specialCitys.add("东莞市"); specialCitys.add("中山市"); specialCitys.add("儋州市"); } //**************************以下值请根据实际情况修改************************************* //抓取的首页 public static final String webUrl = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/index.html"; //保存路径 public static final String savePath = "G:/projects/VDS-3/service/pms/src/main/resources/static/china.json"; //抓取数据的范围 public static final String AREA = "中国";//抓取范围,支持第一级和中国,比如中国,广东省,北京市 // public static final String AREA="中国";//抓取范围,支持第一级和中国,比如中国,广东省,北京市 //表示抓取数据的层级,与LEVEL_MODE相关,如果LEVEL_MODE为LEVEL_MODE_STRING,TARGET_LEVEL为LEVEL_COUNTY则表示抓取到LEVEL_COUNTY这个级别的数据为止, //如果是东莞市或中山市,由于其没有LEVEL_COUNTY这一级,因此这两个市数据只抓取到LEVEL_CITY这个级别 //public static int TARGET_LEVEL = types.indexOf(LEVEL_COUNTY) + 1;//可选值请查看LEVEL_开头的 //表示抓取数据的层级采用的模式:LEVEL_MODE_STRING--表示按字符级别 LEVEL_MODE_NUMBER--表示按数字级别 //public static int LEVEL_MODE = LEVEL_MODE_STRING; //表示抓取数据的层级,与LEVEL_MODE相关,如果LEVEL_MODE为LEVEL_MODE_NUMBER,TARGET_LEVEL为3则表示抓取的是3级数据 //如果是东莞市或中山市,由于其没有LEVEL_COUNTY这一级,因此3级数据的话会抓取到LEVEL_TOWN这个级别 public static int TARGET_LEVEL = 3; //表示抓取数据的层级采用的模式:LEVEL_MODE_STRING--表示按字符级别 LEVEL_MODE_NUMBER--表示按数字级别 public static int LEVEL_MODE = LEVEL_MODE_NUMBER; //**************************以上值请根据实际情况修改************************************* //区划数据保存实体类定义 public static class Region { public Region(String code, String name, int level) { this.code = code; this.name = name; this.level = level; } public String code; //编码 public String name; //名称 public int level;//当前级别 public List<Region> child; } /** * 读省的信息 * * @param args * @throws Exception */ public static void main(String[] args) throws Exception { System.out.println("开始抓取,请耐心等待!!!"); System.out.println("抓取范围:" + AREA + ",抓取模式(1--字符 2--数字):" + LEVEL_MODE + ",抓取层级:" + TARGET_LEVEL + "(模式为字符:1--province,2--city,3--county,4--town,5--village;)"); long starttime = System.currentTimeMillis(); Region region = new Region("000000000000", "中国", 0); region.child = new ArrayList<>(); Document doc = getDocument(webUrl); Elements provincetr = doc.getElementsByClass(LEVEL_PROVINCE); for (Element e : provincetr) { Elements a = e.getElementsByTag("a"); for (Element ea : a) { String nextUrl = ea.attr("abs:href");//拿到绝对路径 String[] arr = nextUrl.split("/"); String code = arr[arr.length - 1].split("\\.")[0] + "0000000000"; String name = ea.text();//11.html if (AREA.equals("中国") || AREA.equals(name)) { Region child = new Region(code, name, 1); region.child.add(child); System.out.println(name); int currentlevel = LEVEL_MODE == LEVEL_MODE_STRING ? getLevel(LEVEL_PROVINCE) : child.level; if (currentlevel < TARGET_LEVEL) {//表示还需要继续解析 parseNext(types.get(1), nextUrl, child); } } } } // System.out.println(new Gson().toJson(region)); //写到文件里 saveJson(region); long endtime = System.currentTimeMillis(); System.out.println("抓取完毕!!!耗时:" + (endtime - starttime) / 1000 / 60 + "min"); } private static Document getDocument(String url) throws IOException { return Jsoup.parse(new URL(url).openStream(), CHARSET, url); } /** * @param type 见LEVEL_ * @return */ private static int getLevel(String type) { return types.indexOf(type) + 1; } private static void saveJson(Region region) throws IOException { FileWriter fw = new FileWriter(new File(savePath)); BufferedWriter bw = new BufferedWriter(fw); bw.write(new Gson().toJson(region)); bw.flush(); bw.close(); } /** * 解析下一级数据 * * @param type 见LEVEL_开头 * @param url 要抓取的网页url * @param region 将要保存的数据 * @throws Exception */ public static void parseNext(String type, String url, Region region) throws Exception { region.child = new ArrayList<>(); Document doc = getDocument(url); Elements es = doc.getElementsByClass(type); if (LEVEL_VILLAGE.equals(type)) { //<tr class="villagetr"><td>110101001001</td><td>111</td><td>多福巷社区居委会</td></tr> for (Element e : es) { Elements tds = e.getElementsByTag("td"); String code = tds.get(0).text(); String name = tds.get(2).text(); Region child = new Region(code, name, region.level + 1); region.child.add(child); System.out.println(space(child.level) + name); } } else { //需要处理以下两种情况 //第一种:<tr class="countytr"><td>130101000000</td><td>市辖区</td></tr> //第二种:<tr class="countytr"><td><a href="01/130102.html">130102000000</a></td><td><a href="01/130102.html">长安区</a></td></tr> for (Element e : es) { String code = null; String name = null; String nextUrl = null; Elements a = e.getElementsByTag("a"); if (a.isEmpty()) {//属于第一种情况 Elements tds = e.getElementsByTag("td"); code = tds.get(0).text(); name = tds.get(1).text(); } else { nextUrl = a.get(0).attr("abs:href");//13/1301.html code = a.get(0).text(); name = a.get(1).text(); } Region child = new Region(code, name, region.level + 1); region.child.add(child); System.out.println(space(child.level) + name); int currentlevel = LEVEL_MODE == LEVEL_MODE_STRING?getLevel(type):child.level; if (!a.isEmpty() && currentlevel < TARGET_LEVEL) { //如果是东莞市,LEVEL_CITY下一级是LEVEL_TOWN,而不是LEVEL_COUNTY这里需要特殊处理 String nextType = null; if (LEVEL_MODE == LEVEL_MODE_NUMBER &&(specialCitys.contains(name))) { nextType = LEVEL_TOWN; } else { nextType = types.get(types.indexOf(type) + 1); } // System.out.println("nextType=" + nextType); parseNext(nextType, nextUrl, child); } } } } private static String space(int level) { if (level > 5) { return ""; } return " ".substring(0, level); } } -
按照上面代码的思路,可以修改为自己想要的保存方式,比如直接将数据存入数据库,鼓励自己动手实践,丰衣足食
-
最后说一下,这些数据最好还是建表保存一下,然后一级一级获取数据,如果想一次性拿到不太现实,本人测试全国只到街道这一级的json数据就有2M多了,这么大的json,光是打开都费劲了
存入数据库方式
-
上面的步骤已经可以拿到json文件了,我们可以利用上面得到的json文件将数据按一定格式存入数据库
-
这里假设我要存入的数据库(mysql)表格式为
CREATE TABLE `pms_region` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '辖区id', `name` varchar(64) COLLATE utf8_bin NOT NULL COMMENT '辖区名称,与国家统计局一致', `code` varchar(45) COLLATE utf8_bin NOT NULL COMMENT '辖区编码,与国家统计局一致', `father_code` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '父辖区编码,如果没有则为null', `name_path` text COLLATE utf8_bin COMMENT '辖区名称路径,例如广东省/广州市', `id_path` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '辖区id路径,例如 1/2/3', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `UNIQUE_region_code` (`code`) USING BTREE COMMENT '编码唯一' ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8 COLLATE=utf8_bin ROW_FORMAT=DYNAMIC COMMENT='行政区域表'; -
数据库映射的实体类,这个实体类使用了lombok,能看懂就行了,其实就是一个普通bean类,由于使用了其他工具,因此多了好多注解,忽略即可
package com.gosuncn.pms.entity; import com.baomidou.mybatisplus.annotation.IdType; import com.baomidou.mybatisplus.annotation.TableId; import java.time.LocalDateTime; import java.io.Serializable; import com.fasterxml.jackson.annotation.JsonFormat; import io.swagger.annotations.ApiModel; import io.swagger.annotations.ApiModelProperty; import lombok.Data; import lombok.EqualsAndHashCode; import lombok.experimental.Accessors; /** * <p> * 行政区域表 * </p> * * @author hwj * @since 2019-04-29 */ @Data @EqualsAndHashCode(callSuper = false) @Accessors(chain = true) @ApiModel public class PmsRegion implements Serializable { private static final long serialVersionUID = 1L; /** * 辖区id */ // @TableId(value = "id", type = IdType.AUTO) //auto时即时手动设置也无效 @TableId(value = "id", type = IdType.INPUT)//input时才能手动设置 private Integer id; /** * 辖区名称,与国家统计局一致 */ @ApiModelProperty(value = "辖区名称,与国家统计局一致", required = true) private String name; /** * 辖区编码,与国家统计局一致 */ @ApiModelProperty(value = "辖区编码,与国家统计局一致", required = true) private String code; /** * 父辖区编码 */ @ApiModelProperty(value = "父辖区编码", required = true) private String fatherCode; /** * 辖区名称路径,例如广东省/广州市 */ @ApiModelProperty(value = "辖区名称路径,例如广东省/广州市", required = true,example = "广东省/广州市/天河区") private String namePath; /** * 辖区id路径,例如 1/2/3 */ @ApiModelProperty(value = "辖区id路径,例如 1/2/3", required = true) private String idPath; @ApiModelProperty(value = "创建时间", required = true) @JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss") private LocalDateTime createTime; @ApiModelProperty(value = "更新时间", required = true) @JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss") private LocalDateTime updateTime; } -
以下是核心代码,就是先读取本地json文件,再通过gson转为对应的实体类,之后解析实体类并按数据库的格式要求进行设置最后批量保存在数据库
/** * 解析json数据并存入数据库 */ public void saveRegionsWithJsonFile() { //读取json文件 GenRegionCodeFromWeb.Region r = new Gson().fromJson(readJsonFile(GenRegionCodeFromWeb.savePath), GenRegionCodeFromWeb.Region.class);//GenRegionCodeFromWeb这个就是上文中的那个抓数据的类了 List<PmsRegion> list = new ArrayList<>(); parse(1,"","",list, r); saveBatch(list);//批量保存进数据库,方法自己实现啦 } /** * * @param level 层级,在这里广东省表示第一级 * @param preid id路径前缀 * @param prename 名称路径前缀 * @param list 将要保存到数据库的数据列表 * @param r 从json里反序列化得到的实体类数据 */ private void parse(int level,String preid,String prename,List<PmsRegion> list, GenRegionCodeFromWeb.Region r) { int len= r.child.size(); for (int i=0;i<len;i++) { GenRegionCodeFromWeb.Region item =r.child.get(i); PmsRegion region = new PmsRegion(); int id=list.size()+1; region.setId(id); region.setCode(item.code); region.setFatherCode(r.code); region.setName(item.name); region.setIdPath(level==1?(preid+id):(preid+"/"+id)); region.setNamePath(level==1?(prename+item.name):(prename+"/"+item.name)); list.add(region); if(item.child!=null&&!item.child.isEmpty()){ parse(level+1,region.getIdPath(),region.getNamePath(),list,item); } } } /** * 根据路径读取json文件的内容 * @param path * @return */ private String readJsonFile(String path) { String Path = GenRegionCodeFromWeb.savePath; BufferedReader reader = null; String laststr = ""; try { FileInputStream fileInputStream = new FileInputStream(Path); InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF-8"); reader = new BufferedReader(inputStreamReader); String tempString = null; while ((tempString = reader.readLine()) != null) { laststr += tempString; } reader.close(); } catch (IOException e) { e.printStackTrace(); } finally { if (reader != null) { try { reader.close(); } catch (IOException e) { e.printStackTrace(); } } } return laststr; } -
存完后差不多就是这样啦
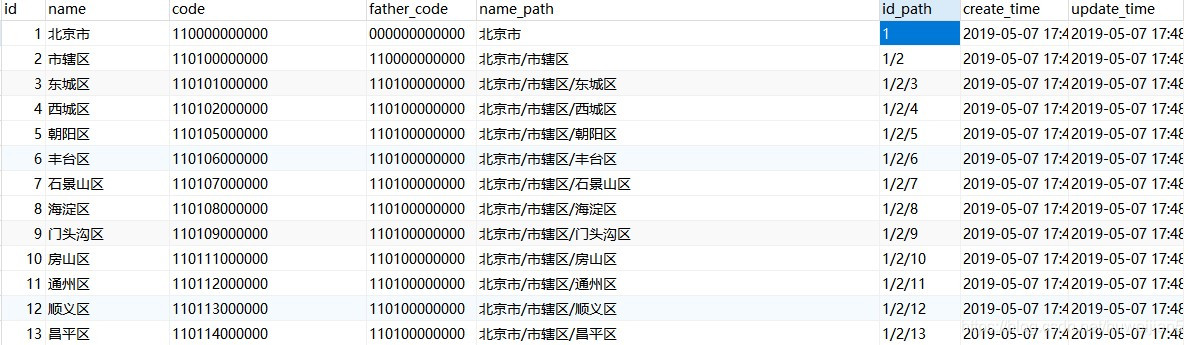
-
以上就向大家展示了保存进数据库的过程,上面的代码不能直接使用,大家的数据库设计也不一定跟我一致,但是上面的思路可以借鉴,或者是跟我差不多的数据库设计那简单修改一下就能满足了
生成sql方式
-
上一种方式是基于数据库的批量插入方法已经实现的情况下,如果没有的话,那要插入数据库还不如使用sql语句来的方便
-
只要将第二种方法获得的列表封装成sql语句保存即可,下面就以生成sql方式举例,核心代码如下
StringBuffer sb = new StringBuffer(); sb.append("insert into pms_region (id,`code`,`name`,father_code,id_path,name_path) values \n"); for (PmsRegion item : list) { sb.append("(") .append(item.getId()).append(",'") .append(item.getCode()).append("','") .append(item.getName()).append("','") .append(item.getFatherCode()).append("','") .append(item.getIdPath()).append("','") .append(item.getNamePath()) .append("'),\n"); } String sql = sb.toString().substring(0, sb.toString().lastIndexOf(",")) + ";"; String savePath = "G:/projects/VDS-3/service/pms/src/main/resources/static/china.sql"; FileWriter fw = new FileWriter(new File(savePath)); BufferedWriter bw = new BufferedWriter(fw); bw.write(sql); bw.flush(); bw.close();
参考
使用java爬取国家统计局的12位行政区划代码 - 自行车上的程序员 - 博客园
https://www.cnblogs.com/yangzhilong/p/3530700.html
